Efficient AI · Language Models · Sequence Modeling
HRM-Text: A 1B Model Trained From Scratch for $1,500
HRM-Text trains a 1B language model from scratch on 40B tokens for about $1,500, scoring 60.7% MMLU, 84.5% GSM8K and 56.2% MATH by swapping Transformers for a hierarchical recurrent model.
Quick answer
HRM-Text is a 1B-parameter language model trained from scratch on only 40 billion unique tokens for roughly $1,500 (46 hours on 16 H100 GPUs), and it scores 60.7% on MMLU, 81.9% on ARC-C, 82.2% on DROP, 84.5% on GSM8K, and 56.2% on MATH. It hits those numbers by replacing the standard Transformer with a Hierarchical Recurrent Model and training only on instruction-response pairs rather than raw web text — using an estimated 100-900x fewer tokens and 96-432x less compute than the 2-7B open models it competes with.
Why $1,500 pretraining is the real claim
The headline is not “another small model.” It is that the authors built a competitive model on a budget any university lab can afford, by attacking the two things that make pretraining expensive: the token count and the architecture’s sample efficiency. Standard pretraining burns through trillions of internet-scraped tokens because next-token prediction on raw text is a wasteful learning signal. HRM-Text argues that if you redesign the architecture and the objective together, you can compress that to tens of billions of tokens without collapsing.
That framing — “an empirical existence proof of efficient pretraining” — is the honest way to read this paper. It is a demonstration that the compute-to-performance ratio is not fixed, not a claim that HRM-Text beats frontier models.
How the hierarchical recurrent model works
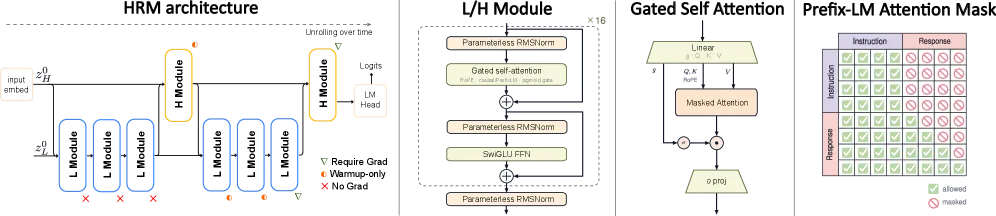
The architecture borrows from neuroscience, specifically the frontoparietal loop’s multi-timescale processing. Instead of stacking identical Transformer blocks, HRM splits computation into two coupled recurrent layers: a slow-evolving strategic layer that updates infrequently and holds a plan, and a fast-evolving execution layer that iterates many steps per strategic update. Depth comes from recurrence — running the same layers repeatedly — rather than from parameter count, which is how a 1B model gets the “effective depth” of a much larger one.
Deep recurrence is notoriously unstable to train for language. Two ingredients keep it from blowing up:
- MagicNorm — a normalization scheme that exploits the asymmetry between the forward and backward computation horizons in truncated backpropagation, blending a PreNorm identity path with PostNorm activation stability.
- Warmup deep credit assignment — the gradient backpropagation horizon is expanded progressively (from K=2 to K=5 recurrent steps) over training, a temporal curriculum that lets credit assignment reach deeper as the model stabilizes.
Why training only on instruction pairs matters
HRM-Text never sees raw web text. It trains exclusively on instruction-response pairs with a task-completion objective: loss is computed only over the response tokens, not the prompt. It also uses PrefixLM masking — bidirectional attention across the instruction, causal masking for the answer — so a decoder-only model behaves like an encoder-decoder over the instruction. This is the lever that lets 40B tokens go so far: every gradient update targets a useful answer instead of predicting the next word of arbitrary scraped text.
Key results
- A 1B HRM-Text trained on 40B unique tokens for ~$1,500 scores 60.7% MMLU, 81.9% ARC-C, 82.2% DROP, 84.5% GSM8K, and 56.2% MATH.
- Training ran in 46 hours on 16 H100 GPUs.
- It uses an estimated 100-900x fewer training tokens and 96-432x less compute than the open baselines it is compared against (Llama 3.2 3B, Gemma 3 4B, OLMo 3 7B, and recurrent models like Huginn and Ouro).
- At 1B parameters it performs competitively with 2-7B-parameter open models on these benchmarks despite the token and compute gap.
Limits and open questions
The benchmark suite is reasoning- and knowledge-heavy (MMLU, GSM8K, MATH, ARC, DROP), which is exactly where instruction-pair training and recurrent “thinking” should shine. The paper does not establish that HRM-Text matches Transformers on open-ended generation, long-form coherence, or broad world knowledge that raw-text pretraining absorbs incidentally — so “competitive with 2-7B models” should be read as “on these tasks,” not everywhere.
Training only on instruction-response pairs also raises a data question: high-quality instruction data is itself expensive to curate, and the paper’s efficiency depends on having it. The compute comparison is an estimate against baselines trained under different regimes, so the 96-432x range is indicative, not a controlled head-to-head. Finally, deep recurrence trades parameter count for sequential compute steps, which can hurt inference latency — the cost story at serving time is less clear than the training one. Whether the recipe scales past 1B without new instabilities is the open question this existence proof invites rather than answers.
FAQ
What is HRM-Text and how is it different from a Transformer?
HRM-Text is a 1B language model that replaces stacked Transformer blocks with a Hierarchical Recurrent Model — a slow strategic layer and a fast execution layer that recur over many steps. Depth comes from recurrence, not parameters, which is what makes it sample-efficient enough to train on 40B tokens.
How much did it cost to train HRM-Text?
About $1,500, corresponding to 46 hours on 16 H100 GPUs and 40 billion unique tokens — roughly 96-432x less compute than the 2-7B open models it is compared with.
How good is HRM-Text on benchmarks?
The 1B model scores 60.7% on MMLU, 81.9% on ARC-C, 82.2% on DROP, 84.5% on GSM8K, and 56.2% on MATH, performing competitively with open models in the 2-7B range on these reasoning and knowledge tasks.
What are MagicNorm and warmup deep credit assignment in HRM-Text?
They are the stability tricks for deep recurrence. MagicNorm blends PreNorm and PostNorm to handle truncated backpropagation’s asymmetric horizons; warmup deep credit assignment grows the backpropagation horizon from 2 to 5 recurrent steps over training so gradients reach deeper safely.
Does HRM-Text use raw web text for pretraining?
No. It trains exclusively on instruction-response pairs with a task-completion loss over the response and PrefixLM masking, which is the main reason 40B tokens are enough.
One line: co-designing a recurrent architecture with an instruction-only objective makes from-scratch pretraining a $1,500 problem, not a million-dollar one. Read the original paper on arXiv.