World Models · Alibaba Qwen Team
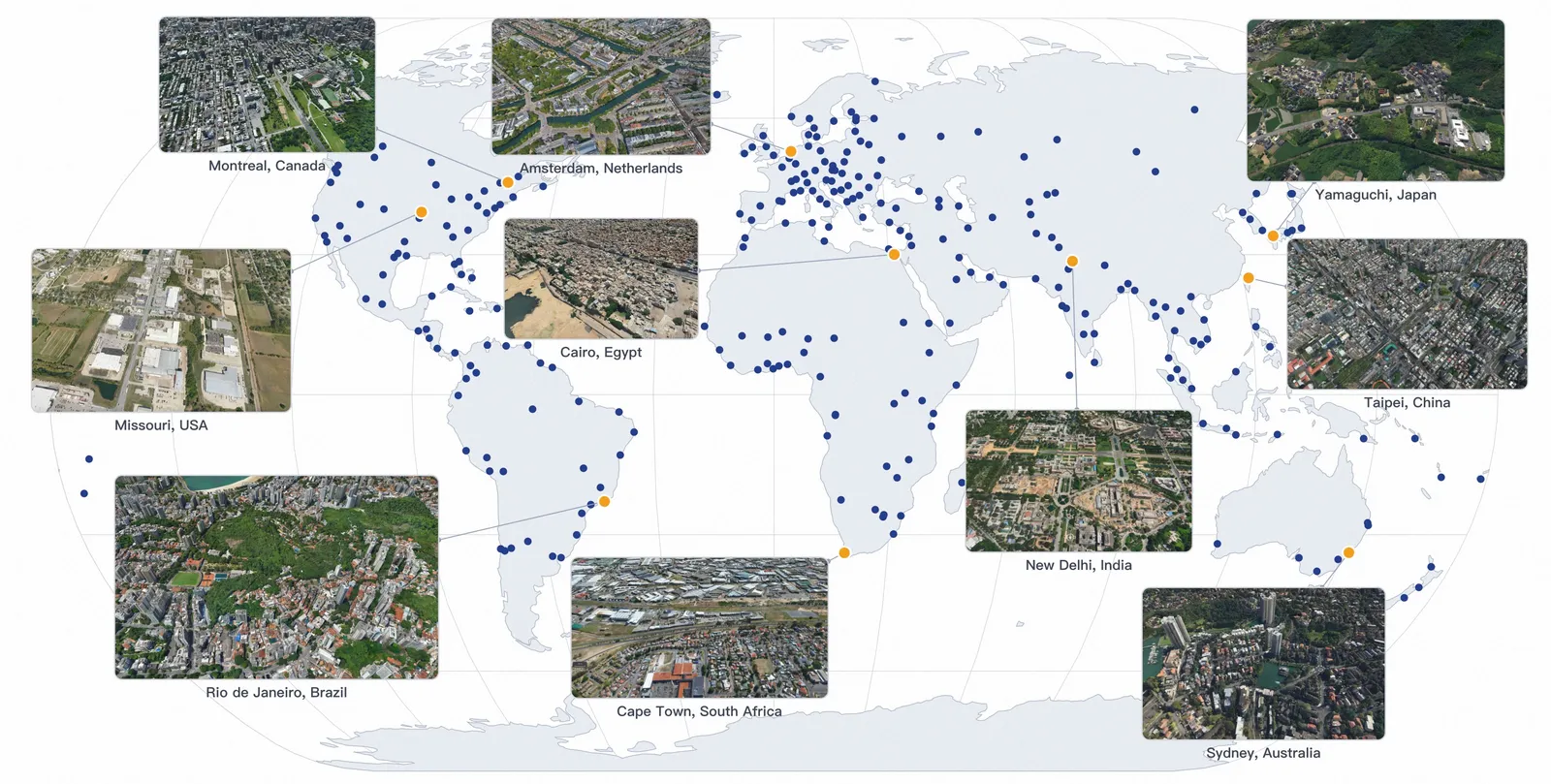
ABot-Earth 0.5: Generating 3D Cities From Satellite Images
ABot-Earth 0.5 uses satellite imagery to generate 3D Gaussian Splatting city scenes, reporting under 10 minutes per square kilometer and FID 16.1.
A research papers website with original explainers for important AI and frontier science papers.

Latest
World Models · Alibaba Qwen Team
ABot-Earth 0.5 uses satellite imagery to generate 3D Gaussian Splatting city scenes, reporting under 10 minutes per square kilometer and FID 16.1.
Agent Memory · National University of Singapore
EvoArena turns static agent tasks into evolving chains and finds current agents average only 39.6% accuracy; EvoMem adds patch memory and improves chain-level accuracy by 3.7 points.
Google DeepMind's report lays out four non-exclusive paths from AGI to ASI and treats each bottleneck, from data walls to regulation, as an open research question.
Text-to-Image · The Chinese University of Hong Kong
InterleaveThinker adds planner and critic agents around frozen image generators, reaching 66.3 to 67.2 average on UEval and lifting FLUX.2-klein WISE from 0.47 to 0.73.
Multimodal Models · Kuaishou Technology
Kwai Keye-VL-2.0 is a 30B-A3B open MoE multimodal model with 256K context, strong long-video scores, and 62.0 on SWE-bench Verified.
Vision-Language-Action · Zhejiang University
LabVLA trains a Qwen3-VL-4B backbone plus DiT action expert on laboratory workflows and reports 71.1% ID and 70.0% OOD success on LabUtopia.
MaxProof turns MiniMax-M3 into a generator, verifier, fixer, and ranker; with population-level test-time scaling it reports 35/42 on IMO 2025 and 36/42 on USAMO 2026.
MiniMax Sparse Attention keeps only 2,048 selected KV tokens per query group and reports 28.4x lower attention FLOPs plus 14.2x prefill speedup at 1M context.
SpatialClaw replaces rigid tool calls with a persistent Python kernel and reaches 59.9% average accuracy across 20 spatial reasoning benchmarks, +11.2 points over the recent spatial-agent baseline.
AI Agents · Renmin University of China
Arbor stores research attempts in a persistent hypothesis tree, then admits changes only through held-out evaluation. It reports best held-out results on six AO tasks and 86.36% Any Medal on MLE-Bench Lite.
AI Agents · TokenRhythm Technologies
Claw-SWE-Bench evaluates OpenClaw-style coding-agent harnesses on 350 GitHub issue tasks. OpenClaw jumps from 19.1% to 73.4% Pass@1 with a full adapter.
Mixture of Experts · Renmin University of China
MPI redesigns MoE routers by aligning router rows with expert weight directions. On 11B MoE, average benchmark accuracy rises from 40.92 to 42.76 with only 0.2% training slowdown.
AI Agents · Independent Researcher
AdaPlanBench: Testing Adaptive Planning in LLM Agents turns adaptive planning under constraints into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Agents' Last Exam tests AI agents on 1,490 expert-built professional tasks across 55 digital industries; the hardest tier averages only 2.6% full pass.
World Models · Independent Researcher
AnchorWorld: Egocentric World Simulation for Embodied AI turns egocentric world simulation into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
AI Agents · Independent Researcher
ArcANE: Measuring When Role-Playing Agents Break Character turns role-playing language agent reliability into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Brain Decoding · Independent Researcher
Brain-Diffuser turns natural scene reconstruction from fMRI signals into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Self-Supervised Learning · Google DeepMind
BYOL turns self-supervised visual learning without negative pairs into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Video Generation · Nanjing University
CoVEBench: Can Video Editors Follow Complex Instructions? turns complex instruction following for video editing into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Segmentation · Google Research
DeepLab turns semantic image segmentation into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Diffusion Language Models · Independent Researcher
Diffusion language modeling survey turns the state of diffusion language modeling into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Small Language Models · Hugging Face
DistilBERT turns knowledge distillation for compact language models into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Text-to-Image · Independent Researcher
DIRECT: 3D-Aware Object Insertion with Visual Proxies turns 3D-aware object insertion into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Brain Decoding · Independent Researcher
DreamDiffusion turns EEG-to-image generation into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
AI Agents · Nanjing University
TELBench asks models to find the span that broke a 12-step research trajectory. DRIFT audits claims against evidence, lifting macro-F1 to 54.91% with Claude-Sonnet-4.6, up to 30 points over raw inspection.
Biomolecular Modeling · Independent Researcher
DynamicMPNN turns multi-state protein sequence design into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Text Embeddings · Microsoft Research
E5 turns general-purpose text embeddings into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
World Models · JD.com (Joy Future Academy)
When a camera revisits an old spot, block-wise state-space recurrence scored 69.0 open-domain VLM consistency vs 12.25 for the no-memory baseline; aggressive compression and spatial summaries mostly collapsed.
Diffusion Language Models · Independent Researcher
Factorization-error-free decoding turns speculative decoding for discrete diffusion LMs into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Biomolecular Modeling · Independent Researcher
Feynman-Kac steering turns controllable protein design with guided diffusion into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
World Models · Independent Researcher
Function2Scene: 3D Indoor Layout from Functional Specs turns functional 3D scene layout into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Diffusion Models · The Hong Kong Polytechnic University
GGT-100K: Generative Ground Truth for Image Restoration turns real-world image restoration data into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
AI Agents · University of Illinois Urbana-Champaign
Harness-1 is a 20B RL search agent that hands working memory to the environment, hitting 0.730 average curated recall and beating the next open subagent by +11.4 points.
Theorem Proving · Google Research
HOList turns machine learning for higher-order theorem proving into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Multimodal Models · Peking University
A survey that reframes long-video MLLMs as three abilities (watch, remember, reason), comparing against 11 prior surveys and organizing 100+ methods plus 5 application domains.
AI Agents · Independent Researcher
K-BrowseComp: Korean Web-Browsing Agent Benchmark turns Korean-context web browsing agents into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
AI Agents · Shanghai Jiao Tong University
A hypernetwork compiles a textual skill into a LoRA adapter in one forward pass. On ALFWorld, LatentSkill lifts success by 21.4 points (seen) with 64.1% fewer prefill tokens.
Theorem Proving · Princeton University
LeanDojo turns retrieval-augmented theorem proving in Lean into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Language Models · Independent Researcher
Averaging the output distributions of 3 independent LLMs collapses watermark detection z-scores from 5-300 down below 2, and the WASH paper proves why it works with an O(1/sqrt(N)) error bound.
Reinforcement Learning · Tianjin University
When you RL-tune an LLM across math, code, QA, and writing in sequence, math drops from 66.49 to 57.66 even though gradients look orthogonal. A short math refresh pulls it back to 66.04 without wrecking the other three.
Speech Synthesis · Independent Researcher
A Broad Benchmark for Long-Form Speech Generation turns long-form speech generation into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Long Context · Tsinghua University
Tsinghua's LongTraceRL mines distractors from real search-agent trajectories and adds entity-level rubric rewards, lifting a Qwen3-4B reasoner from 53.3 to 59.0 average across five long-context benchmarks (+5.7).
Self-Supervised Learning · Meta AI
MAE turns masked image modeling for vision pretraining into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Mask R-CNN turns instance segmentation into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
AI Agents · Independent Researcher
When Masking Stale Observations Helps Search Agents turns context management for search agents into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Brain Decoding · Independent Researcher
MinD-Vis turns fMRI-to-image reconstruction with latent diffusion into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Theorem Proving · Independent Researcher
MiniF2F turns formal Olympiad-level mathematics benchmarking into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Small Language Models · Google Research
MobileBERT turns mobile-friendly BERT compression into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Speech Synthesis · Independent Researcher
MMAE: A Massive Benchmark for Audio Editing Models turns audio editing evaluation into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
OpenSkill lets agents build skills and their own verifiers from the open web, hitting 43.6% on SkillsBench (+8.9 over the best baseline) with zero target-task answers.
Multimodal Models · Shanghai AI Laboratory
OVO-S-Bench: Streaming Spatial Intelligence in MLLMs turns streaming spatial intelligence into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Biomolecular Modeling · Independent Researcher
ProGen2 turns protein sequence modeling and design into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
AI Agents · Shanghai AI Laboratory
ResearchClawBench: Testing Autonomous Research Agents turns end-to-end scientific research agents into a checkable test, with concrete failure signals, benchmark limits, and builder takeaways.
Reinforcement Learning · Tsinghua University
CHERRL injects four known judge biases to reliably reproduce reward hacking in rubric RL; an agent reading only training logs pinned the onset with 11-step total interval error and missed none of six runs.
SAAS uses self-aware RL to cut a Qwen2.5-7B search agent's average queries from 2.19 to 0.97 per question, while keeping accuracy near the best baseline (48.7% vs 49.8%).
Reinforcement Learning · University of Edinburgh
SCOPE co-evolves a task-writing Challenger and a retrieval Solver, judged by a frozen copy of the base model, lifting eight open-ended benchmarks by up to +10.4 points with zero curated prompts.
Diffusion Language Models · Independent Researcher
SEDD turns discrete diffusion language modeling into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Text Embeddings · Independent Researcher
Sentence-BERT turns sentence embeddings for semantic similarity into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Text Embeddings · Princeton University
SimCSE turns contrastive sentence embedding learning into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.
Self-Supervised Learning · Google Research
SimCLR turns contrastive visual representation learning into a concrete research object, with evidence anchors, method tradeoffs, and limits for practical use.