Perception or Prejudice: Can MLLMs Ground Personality in Real Evidence?
MM-OCEAN tests whether multimodal LLMs justify Big Five personality ratings with real video evidence. Across 27 models, 51.3% of correct ratings rest on wrong cues, and the best grounds only 33.5% fully.
Quick answer
MM-OCEAN shows that multimodal LLMs mostly guess personality from first impressions rather than read the evidence. Across 27 models (13 closed, 14 open), the mean Prejudice Rate is 51.3% — over half of all correct Big Five ratings are not anchored in the behavioral cues the model was supposed to use. Full success, where a model rates, explains, and grounds all in agreement, averages just 10.4%, and even the best system (Gemini 3 Flash) reaches only 33.5%.
What Grounded Personality Reasoning asks for
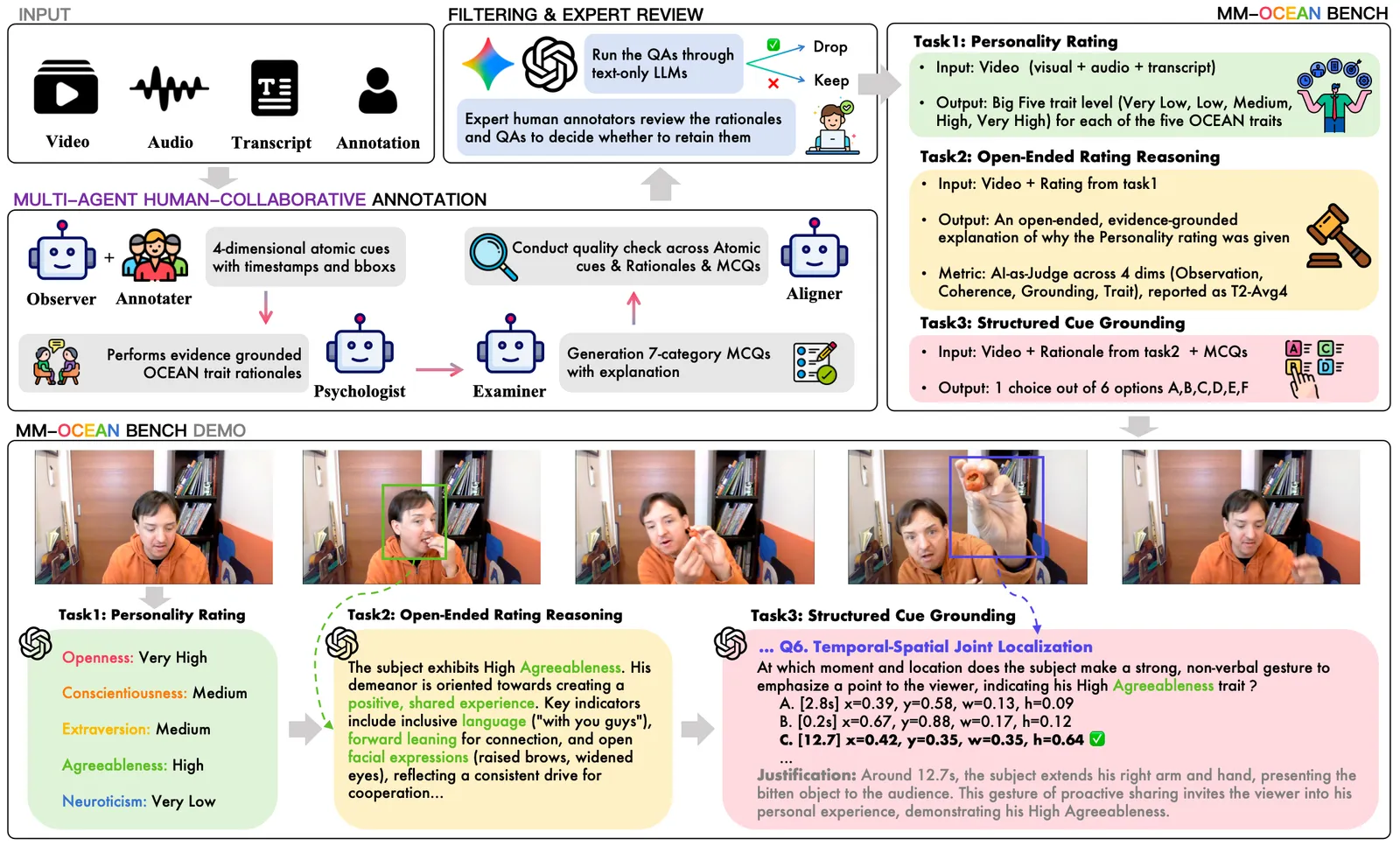
The paper formalizes a task it calls Grounded Personality Reasoning (GPR), which splits an apparent-personality judgment into three linked outputs a model must produce together:
- T1 — Rating: an ordinal 1-5 score for each Big Five trait (Openness, Conscientiousness, Extraversion, Agreeableness, Neuroticism).
- T2 — Reasoning: an open explanation that cites specific observable behavior, not vibes.
- T3 — Grounding: structured multiple-choice questions that pin the judgment to concrete cues — micro-expressions, spatial location, temporal-causal chains, and more.
The point is that a right answer for the wrong reason is a failure. A model that says “highly extraverted” but cannot point to the smile, the gesture, or the vocal energy that justifies it is pattern-matching on a stereotype, not perceiving. GPR is built to catch exactly that.
What is in MM-OCEAN
MM-OCEAN is a benchmark of 1,104 videos drawn from the ChaLearn First Impressions V2 dataset, paired with 5,320 multiple-choice questions (about 4.8 per video) and roughly 13,500 human-verified atomic behavioral observations across four perceptual channels. It was built through a multi-stage human-collaborative pipeline: an observer agent proposes cues, humans verify them, a psychologist agent maps cues to traits, an examiner agent writes the questions, and a final text-leakage filter plus expert review strips out anything answerable from the transcript alone. Inter-annotator agreement on the verdict labels is 77%.
The text-leakage filter matters more than it sounds. A recurring problem with multimodal benchmarks is that the “vision” task is secretly solvable from text. By filtering those cases out, MM-OCEAN forces models to actually look.
The four failure modes it measures
Instead of one accuracy number, MM-OCEAN reports four diagnostic rates that separate how a model fails:
- Prejudice Rate (PR): right rating, wrong cues — the headline finding.
- Confabulation Rate (CR): a plausible-sounding rationale built on inaccurate evidence.
- Integration-failure Rate (IR): right cues identified, but the wrong trait conclusion drawn from them.
- Holistic-grounding Rate (HR): the only success state — rating, reasoning, and grounding all correct and consistent.
This decomposition is the paper’s real contribution. A single leaderboard score would have hidden the fact that high rating accuracy and genuine perception are almost decoupled.
Key results
- 51.3% mean Prejudice Rate across 27 models: the majority of correct trait ratings are not grounded in the right behavioral evidence.
- 10.4% mean Holistic-Grounding Rate: field-wide, models fully ground their judgment about one time in ten.
- 0 to 33.5% HR range: the weakest model grounds nothing; Gemini 3 Flash leads at 33.5% HR with a 17.2% PR.
- Closed beats open mainly on grounding, not rating: the closed-source advantage is 5.6 points on rating (T1) but 26.6 points on grounding (T3) — the gap is overwhelmingly about whether a model can locate evidence, not whether it can output a plausible score.
- Vision is the bottleneck: spatial localization sits at 30.7% mean accuracy and micro-expression detection at 34.6%, while temporal-causal reasoning reaches 64.8%. Models reason about behavior far better than they perceive it.
- Among open models, the best is Qwen3.5-397B at 15.9% HR — but with a 41.5% PR, far more prejudiced than the closed leaders.
Why this benchmark is worth attention
Apparent-personality prediction is already deployed in hiring screens and ad targeting, and the comfortable assumption is that a model scoring well on Big Five traits is “reading” the person. MM-OCEAN shows that assumption is mostly false: the rating can be right while the reasoning underneath is a stereotype. That is a fairness problem, not just an accuracy one — a system that judges extraversion from a face it has not actually examined will carry whatever bias its training distribution encoded. By making grounding a first-class, separately scored requirement, the benchmark gives a concrete target for fixing it.
Limits and open questions
The honest caveats are real. MM-OCEAN measures apparent personality — how a person comes across in a 15-second, single-speaker, English clip — not ground-truth self-reported traits, so a model could be “wrong” in a way humans would also be wrong. The T2 reasoning quality is judged by an AI (GPT-4o-mini) rather than humans, which imports that judge’s own blind spots. The clips are short, monolingual, and cut from one dataset, so cross-cultural and long-form perception are untested. And the paper is diagnostic, not prescriptive: it shows the prejudice gap clearly but proposes no training method to close it, leaving the obvious next question — can grounding be trained in? — wide open.
FAQ
What does the MM-OCEAN benchmark actually test?
It tests whether a multimodal LLM can justify its Big Five personality ratings with the correct observable evidence, not just produce a plausible score. It scores rating, free-text reasoning, and structured cue-grounding together, so a right answer backed by the wrong cues counts as a failure.
What is the Prejudice Rate in MM-OCEAN?
The Prejudice Rate is the fraction of correct personality ratings that are not anchored in the right behavioral cues — “right answer, wrong reasons.” Across 27 models it averages 51.3%, meaning over half of correct ratings are effectively lucky guesses from first impressions.
Which model does best on MM-OCEAN?
Gemini 3 Flash leads with a 33.5% Holistic-Grounding Rate and a 17.2% Prejudice Rate. No model exceeds 34% full grounding, and the field-wide average is only 10.4%, so even the leader fails to fully ground its judgment most of the time.
Why is grounding harder for MLLMs than rating personality?
Because rating only needs a plausible score, while grounding needs the model to locate specific visual evidence. The closed-vs-open gap is 5.6 points on rating but 26.6 points on grounding, and the hardest categories are perceptual — spatial localization at 30.7% and micro-expression detection at 34.6%.
One line: getting the personality rating right is easy; getting it right for the right reason is where MLLMs fall apart. Read the original paper on arXiv.