Multimodal Models · Vision Foundation Models · Alignment
Robust-U1: MLLMs Recover Corrupted Images First
Robust-U1 trains an MLLM to reconstruct corrupted visual content, reaching 0.7398 overall on R-Bench versus 0.5770 for BAGEL and 0.5017 for Robust-R1.
Quick answer
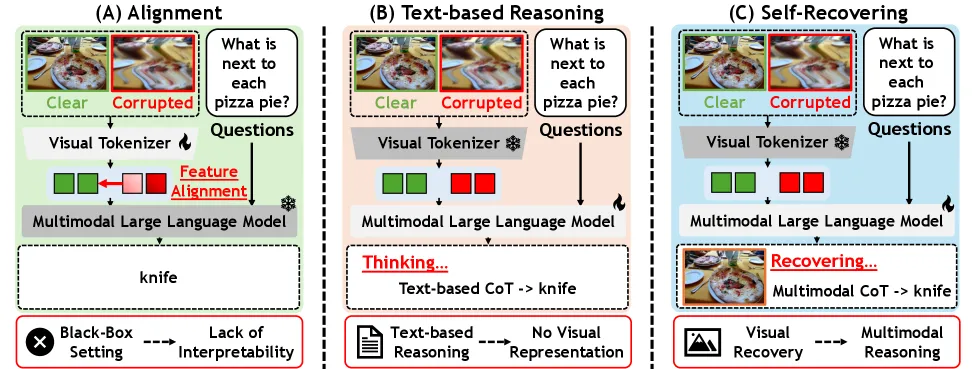
Robust-U1 argues that robustness for multimodal large language models should not stop at saying “the image is degraded.” The model should try to recover the visual content, then reason over both the corrupted input and the recovered image. On R-Bench, Robust-U1 reaches 0.7398 overall, compared with 0.5770 for BAGEL and 0.5017 for Robust-R1. On MMMB with 100% synthetic corruption, it scores 83.18, above BAGEL at 78.48 and Robust-R1 at 75.35. The interesting part is that the method treats reconstruction quality as part of reasoning, not as a separate image-restoration demo.
The mechanism: recovery as a reasoning input
The pipeline has three stages. First, supervised fine-tuning gives the MLLM an initial ability to map corrupted images toward cleaner images. Second, reinforcement learning improves the recovered image using two rewards: a pixel-level SSIM reward and a semantic CLIP-similarity reward. Third, the model learns to answer using both the corrupted image and its recovered version.
That separation is useful because previous robust MLLM approaches attack different failure modes. Feature alignment can improve corrupted-image features, but the process is hard to inspect. Textual reasoning about corruption is interpretable, but it cannot restore pixel-level details. Robust-U1 tries to make the missing pixels visible enough for the model to use them.
The case study shows the difference. In a degraded driving image, Qwen2.5-VL and Robust-R1 infer the wrong direction; BAGEL attempts recovery but generates a misleading image; Robust-U1 recovers an image that supports the correct “left” answer. That is not proof of broad driving reliability, but it shows why a text-only corruption chain can fail.
Key results
- On R-Bench, Robust-U1 reaches 0.7398 overall; BAGEL is 0.5770 and Robust-R1 is 0.5017.
- R-Bench high-degradation CAP is where the gap is sharp: Robust-U1 scores 0.7640, BAGEL 0.4288, and Robust-R1 0.3484.
- On MMMB at 100% corruption, Robust-U1 scores 83.18 versus 78.48 for BAGEL and 75.35 for Robust-R1.
- The MMMB clean-to-100% drop is 1.57 points for Robust-U1, compared with 3.44 for BAGEL and 6.06 for Robust-R1.
- Ablation on R-Bench shows the full method at 0.7398 overall; removing multimodal reasoning drops to 0.6623, and removing either reward drops to about 0.726.
What builders should take from it
The practical takeaway is not to copy the headline number blindly. Robust-U1 is useful when a team can reproduce the paper’s setup and when the measured bottleneck matches its own product or research loop. The paper-specific evidence above tells builders where the gain comes from, what comparator was used, and which parts are still protocol-dependent. A good follow-up is to rerun the same idea on a local task distribution before treating it as a general capability upgrade.
For vision teams, the immediate test is whether recovery improves decisions that matter after corruption, not whether the restored image looks attractive. The paper’s numbers are strongest when image quality and answer quality move together.
Limits and open questions
Robust-U1 is strongest when the corruption can plausibly be inverted into a useful recovered image. If the image has lost evidence entirely, recovery can become hallucination. The model also inherits risks from using generated visual content as evidence: a cleaner-looking image may be wrong in a way that is harder for the language model to doubt. For deployment, the right use is robust perception under common degradations, with uncertainty checks around safety-critical details.
The missing evidence that would change the judgment is a broader external replication: more independent harnesses, clearer release artifacts, and stress tests designed by groups that did not build the method. Until then, the paper is best read as a strong directional result with a concrete evaluation surface.
FAQ
What is Robust-U1?
Robust-U1 is a multimodal framework that trains an MLLM to recover corrupted visual content and then answer using both the corrupted and recovered images.
How much better is Robust-U1 on R-Bench?
It reports 0.7398 overall on R-Bench, ahead of BAGEL at 0.5770 and Robust-R1 at 0.5017 across MCQ, VQA, and captioning under low, mid, and high degradation.
Why do Robust-U1 dual rewards matter?
The SSIM reward pushes structural fidelity, while the CLIP-similarity reward preserves semantic content. The full model balances both and beats variants that remove either reward on the overall R-Bench score.
One line: Robust-U1 is worth watching because it makes corrupted-image recovery part of multimodal reasoning, while also exposing the risk that a restored image can become a confident but wrong witness. Read the original paper on arXiv.