Multimodal Models · Vision Foundation Models
VLM3: Vision Language Models Are Native 3D Learners
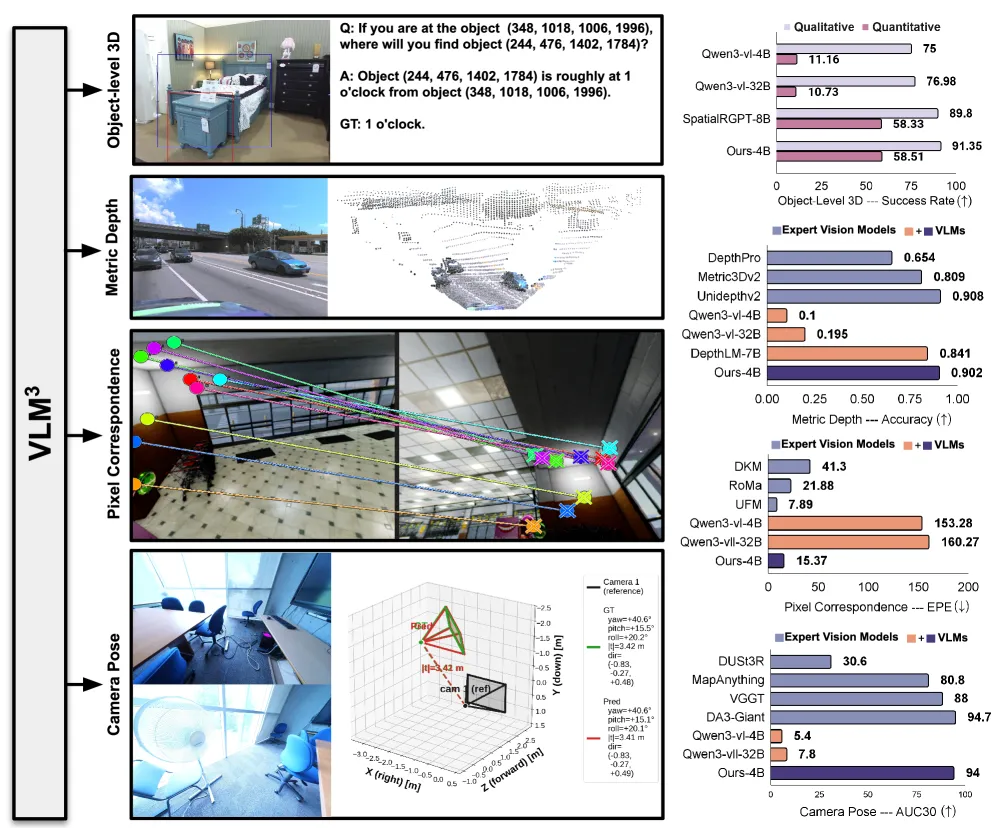
VLM3 shows a standard 4B vision-language model matches expert 3D models — 0.904 depth accuracy, 94.0% camera-pose AUC, 91.35% object-3D accuracy — with no 3D-specific architecture, only focal unification and scaling.
Quick answer
VLM3 argues that a plain vision-language model, with no 3D-specific architecture and no specialized geometric losses, learns 3D as well as the expert models built for it. The 4B model hits a 0.904 average δ₁ on metric depth across 8 datasets, matching UnidepthV2 and MoGe-2, and lifts DepthLM’s 0.84 to 0.90. On camera pose it scores 94.0% AUC@30° on ETH3D and ScanNet++, statistically tying DA3-Giant’s 94.7% and beating VGGT. The claim of the paper, stated plainly: “focal length unification, text-based pixel reference and data mixture and scaling, are all you need for effective 3D learning.” The implication is that the field has been over-engineering 3D — adding cost-volume heads, depth decoders, and bespoke losses to solve a problem a generic transformer already absorbs from data.
The problem: why VLMs were thought to be bad at 3D
Vision-language models read pixels and emit text. 3D vision lives in continuous geometry — depth in meters, camera rotations, dense per-pixel correspondences. The standard assumption was that text decoding throws away the spatial precision 3D needs, so the community kept building expert models with geometry-aware components. VLM3 attacks two concrete obstacles that made VLMs underperform, rather than the architecture itself.
First, camera ambiguity. The same scene shot at different focal lengths produces different pixel-to-depth relationships, so a model trained on mixed data sees contradictory supervision for visually identical inputs. Second, how to point at a pixel. Earlier methods like visual prompting overlay markers on the image to specify a location, which is clumsy and breaks the clean text interface.
The method: three changes, no new architecture
VLM3 keeps the standard VLM stack and the text-based training paradigm. It adds three ingredients.
Focal length unification resizes every image so the effective focal length is 1000 pixels. This removes the camera ambiguity above and makes data from different cameras and datasets directly mixable — a precondition for scaling.
Text-based pixel reference drops visual markers entirely. The model names pixels using normalized integer coordinates in a [0, 2000) range, emitted as text. The paper reports this matches the accuracy of visual prompting while keeping the interface purely textual, so correspondence and pose tasks become ordinary text generation.
Data mixture and scaling is the part the authors weight most heavily. They find that once the first two fixes are in place, dataset weighting becomes “(almost) the most important thing when scaling up training” — weighting by dataset size prevents the model overfitting to whichever corpus is largest. There is no new loss function and no 3D decoder; the gains come from making heterogeneous 3D data trainable at scale.
Key results
A single 4B VLM3 model covers four tasks that usually need four separate expert systems:
- Metric depth (δ₁, higher better): 0.904 average across 8 datasets, matching UnidepthV2 and MoGe-2; improves DepthLM-7B’s 0.84 to 0.90 — and does it with fewer parameters.
- Camera pose (AUC@30°, higher better): 94.0% average on ETH3D and ScanNet++, statistically tying DA3-Giant’s 94.7% and surpassing VGGT.
- Object-level 3D understanding: 91.35% qualitative accuracy and 58.51% quantitative accuracy, outperforming SpatialRGPT-8B on both.
- Pixel correspondence (EPE, lower better): 15.37 pixels average, a roughly 10x reduction versus a baseline VLM, beating expert matchers DKM and RoMa.
The honest read: depth and pose are the headline wins, where VLM3 genuinely ties the best specialists. Correspondence is where it competes but does not lead.
Limits and open questions
The most important caveat is in correspondence. VLM3’s 15.37 EPE beats DKM and RoMa but trails the expert matcher UFM at 7.89 EPE — roughly half the error. So the “VLMs match experts” claim holds for depth, pose, and object-3D, but not yet for dense matching, where a dedicated model still wins by 2x.
The authors attribute the remaining gap to data rather than architecture, suggesting “further scaling and more careful data mixture tuning” would close it — which is a hypothesis, not a demonstrated result. Open questions follow: does the no-3D-architecture story survive at the matching frontier, or does correspondence need something the text interface cannot express precisely enough? How far does focal-length unification generalize to extreme or unknown intrinsics? And the [0, 2000) coordinate quantization caps achievable spatial precision — an inherent ceiling of pointing at pixels through text.
FAQ
What is VLM3?
VLM3 is a vision-language model from Meta and Princeton that learns 3D tasks — metric depth, camera pose, pixel correspondence, object-level 3D — without any 3D-specific architecture or specialized loss. A 4B version matches expert vision models on most of these.
How does VLM3 match expert 3D models without a 3D architecture?
Three changes to a standard VLM: focal-length unification (resize images to a 1000-pixel focal length to remove camera ambiguity), text-based pixel reference (name pixels as text coordinates in [0, 2000) instead of visual markers), and data mixture and scaling weighted by dataset size.
Is VLM3 better than DepthLM and SpatialRGPT?
On depth, VLM3 improves DepthLM-7B’s δ₁ from 0.84 to 0.90 with a smaller 4B model. On object-level 3D understanding it outperforms SpatialRGPT-8B on both qualitative (91.35%) and quantitative (58.51%) accuracy.
What can VLM3 not do well?
Dense pixel correspondence. VLM3 reaches 15.37 EPE — better than DKM and RoMa, but the expert matcher UFM is far ahead at 7.89 EPE, about half the error. Matching is the one task where a specialist still beats it.
What does “focal length unification” mean in VLM3?
It resizes images so the effective focal length is always 1000 pixels. Because focal length controls how pixels map to real-world depth, fixing it removes the contradictory supervision that otherwise arises when training on images from many different cameras.