Draft-OPD:在线策略蒸馏把投机解码推过 5 倍
Draft-OPD 让草稿模型在自身起草的状态上训练。Qwen3 思考模型加速 4.86 到 4.89 倍,比 EAGLE-3 高 23%、DFlash 高 13%,且无损。
快速答案
Draft-OPD 是一套用于投机解码草稿模型的在线策略训练方法。它不再只模仿目标模型的转写,而是让草稿模型在自己起草所产生的状态上接受监督,包括那些提案被拒绝的位置。在 Qwen3 思考模型上,Qwen3-4B 达到 4.86 倍加速,Qwen3-8B 达到 4.89 倍,对比 EAGLE-3 的 3.87 倍和 4.06 倍、DFlash 的 4.33 倍和 4.34 倍。跨基准平均下来,在算力对齐条件下比 EAGLE-3 高 23%、比 DFlash 高 13%。解码保持无损:目标模型的输出分布不变,因此生成质量不受影响。
问题:离线训练的草稿模型在推理时会漂移
投机解码的做法是让小草稿模型一次提出若干 token,再由大目标模型一次验证,从而加速。难点在草稿模型的训练。EAGLE-3 和 DFlash 这类方法用目标模型生成的文本做监督微调,这是离线数据:草稿模型从未见过它自回归起草后真正会到达的状态。论文称之为离线与推理的失配。表现就是监督微调过程中接受长度很快触顶,加更多模仿数据也不再有用。草稿模型擅长复刻目标的转写,却不擅长从自己的错误中恢复,而这恰恰是验证环节制造出的处境。
方法:目标辅助 rollout 加错误位置重放
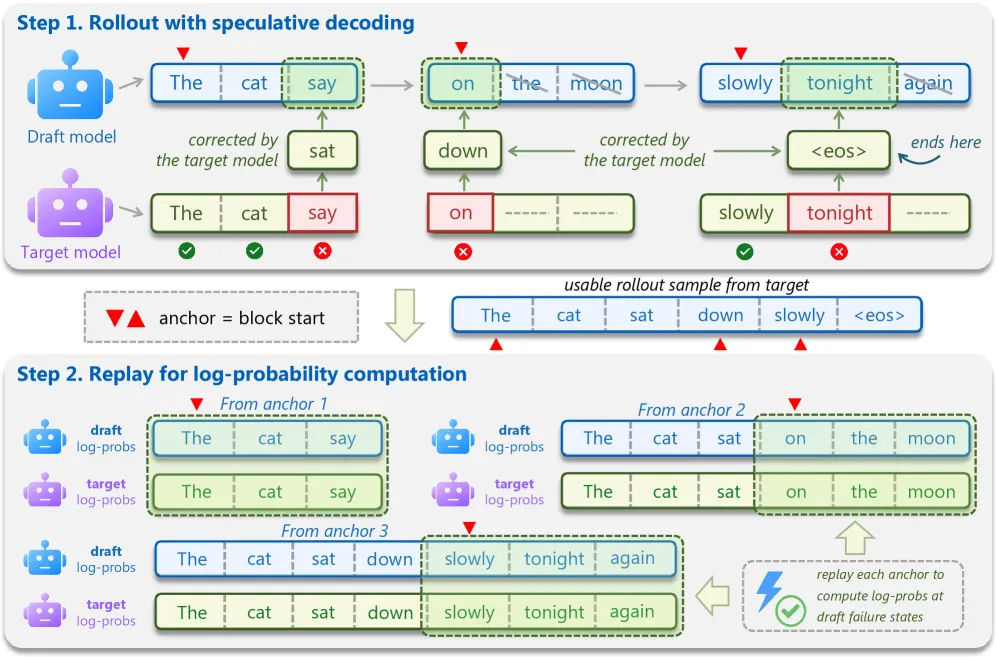
Draft-OPD 借用了强化学习里的在线策略思想,但针对起草做了改造。直接套用在线策略蒸馏对草稿模型行不通,因为放任草稿自由生成会产生目标模型根本不会接受的、偏离分布的不稳定序列。
解决办法分两步。目标辅助 rollout 跑普通的投机解码来收集高质量续写,同时记录每个草稿块起始的锚点位置,这样既让序列停留在目标分布上,又捕捉到草稿真正做了什么。错误位置重放随后从每个锚点重新起草,在草稿生成的 token 上同时计算学生和教师的对数概率,关键是包含那些标记草稿出错的被拒提案。
训练目标是非对称 KL 散度:对接受的 token 用前向 KL(此处草稿与目标已一致),对被拒的 token 用反向 KL(惩罚草稿把概率压在目标拒绝的续写上)。位置加权衰减强调块内靠前的拒绝,因为它们损失的接受长度最大。最终效果是草稿模型既从命中也从失误中学习,而纯监督微调做不到,因为它根本观察不到失误。
为什么是现在
思考模型生成很长的推理链,逐 token 解码的延迟成了主要成本。投机解码是标准应对方案,但草稿模型是瓶颈,监督微调训练的草稿又已撞到天花板。Draft-OPD 在不动目标模型、不牺牲输出质量的前提下抬高了这道天花板,因此对已经在跑 EAGLE-3 或 DFlash 式草稿的推理栈来说,是个可直接替换的升级。
关键结果
- Qwen3-4B(思考模式,温度 0): Draft-OPD 加速 4.86 倍,接受长度 tau 为 5.96;DFlash 4.33 倍,tau 5.51;EAGLE-3 3.87 倍,tau 5.33。
- Qwen3-8B(思考模式,温度 0): Draft-OPD 4.89 倍,tau 5.73;DFlash 4.34 倍,tau 5.19;EAGLE-3 4.06 倍,tau 5.64。
- 整体增益: 算力对齐下比 EAGLE-3 高约 23%、比 DFlash 高约 13%。
- 头条结论: 思考模型跨多任务取得超过 5 倍无损加速,非思考模式单任务峰值更高。
- 质量: 解码保持分布不变,按设计生成质量不受影响。
- 评测集: GSM8K、MATH-500、AIME、MBPP、HumanEval、SWE-Lite、MT-Bench,模型为 Qwen3-4B、Qwen3-8B、Qwen3-30B-A3B-Thinking。
局限与存疑
训练长度上限为 4,096 token,而评测跑到 8,192,因此草稿模型训练用的上下文比测试时更短。评测只覆盖 Qwen3 系列和 DFlash 式草稿架构,增益能否迁移到别的模型家族或草稿设计在此未验证。方法只针对速度而非质量,对那些目标模型本身是瓶颈的任务没有帮助。头条 5 倍是跨基准、跨模式聚合的数字,单任务会有差异,更干净的同口径数字是上面的逐模型加速。此外还有训练开销:rollout 加重放的循环比单遍监督微调更重。
常见问题
Draft-OPD 里的在线策略是什么意思?
指草稿模型在投机解码中由它自身起草策略所诱导的状态上接受监督,而不是只在固定的目标生成转写上训练。这弥合了监督微调草稿模型受限的离线与推理失配。
Draft-OPD 会改变目标模型的输出吗?
不会。投机解码保持目标模型的输出分布,Draft-OPD 明确只为提升解码速度而非生成质量而设计,输出与目标模型的标准解码一致。
它和 EAGLE-3、DFlash 有何不同?
EAGLE-3 和 DFlash 用离线目标文本做监督微调训练草稿。Draft-OPD 加入目标辅助 rollout 来保持在分布上,加入错误位置重放从被拒提案中学习,并用非对称的前向加反向 KL 目标训练。在 Qwen3 思考模型上分别带来高 23% 和 13% 的加速。