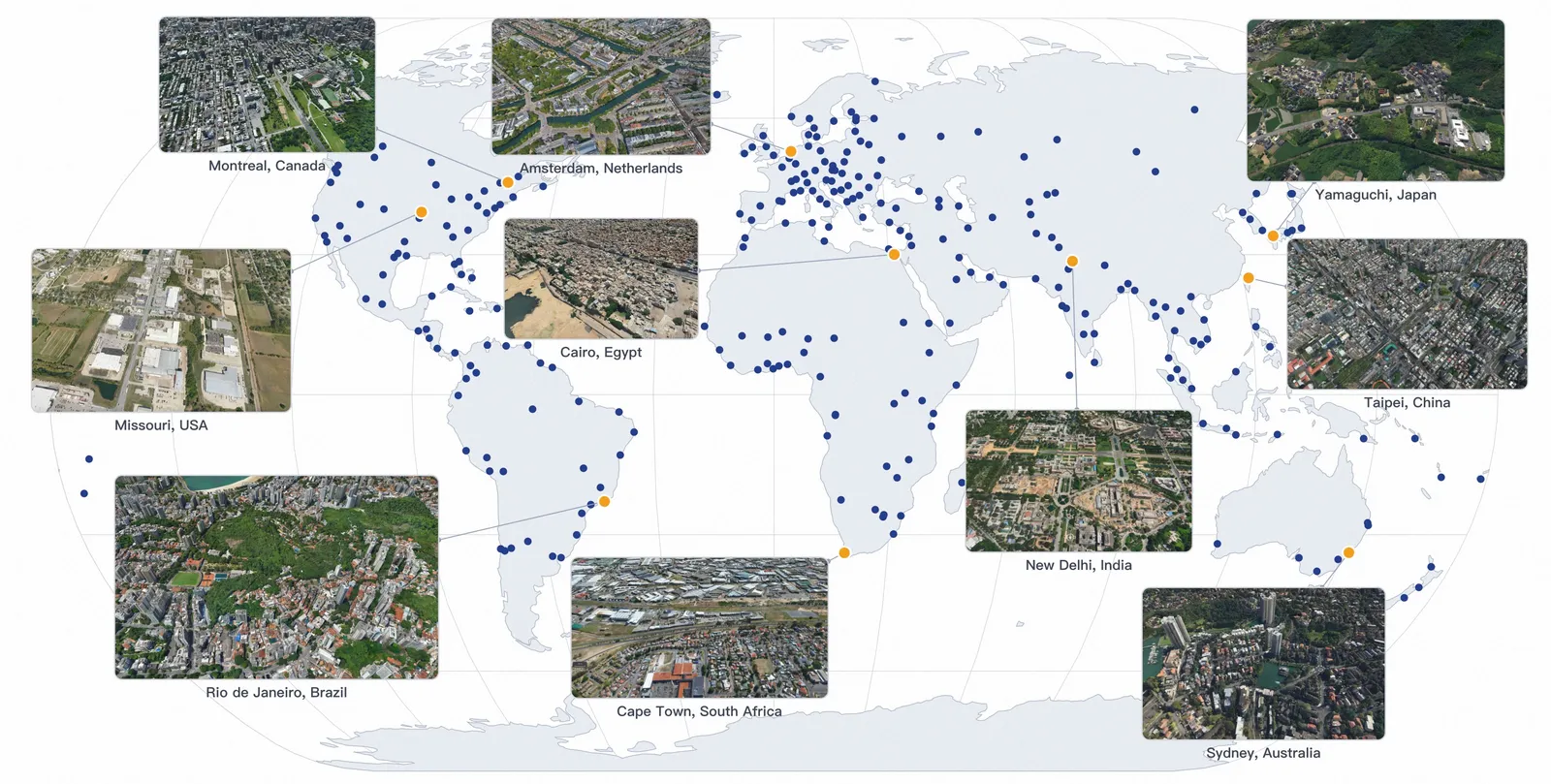
ABot-Earth 0.5:从卫星图生成3D城市
ABot-Earth 0.5 用卫星图生成 3D Gaussian Splatting 城市场景,报告每平方公里 10 分钟内生成,FID 为 16.1。
面向 AI 与科学前沿的重要论文,提供原创结构化解读。

最新
ABot-Earth 0.5 用卫星图生成 3D Gaussian Splatting 城市场景,报告每平方公里 10 分钟内生成,FID 为 16.1。
智能体记忆 · National University of Singapore
EvoArena 把静态智能体任务改造成演化链,当前智能体平均准确率只有 39.6%;EvoMem 用 patch memory 将链级准确率提高 3.7 点。
Google DeepMind 报告梳理 AGI 到 ASI 的四条非互斥路径,并把数据墙、资源约束、监管等瓶颈视为开放研究问题。
文生图 · The Chinese University of Hong Kong
InterleaveThinker 给冻结图像生成器加 Planner 和 Critic,UEval 达到 66.3/67.2,WISE 从 0.47 提到 0.73。
Kwai Keye-VL-2.0 是 30B-A3B 开放 MoE 多模态模型,支持 256K 上下文,在长视频、时间定位和代码智能体任务上表现突出。
视觉-语言-动作 · Zhejiang University
LabVLA 用实验室工作流数据训练 Qwen3-VL-4B 加 DiT 动作专家,在 LabUtopia 上达到 71.1% ID 和 70.0% OOD 成功率。
MaxProof 把 MiniMax-M3 当作生成器、验证器、修复器和排序器使用,在 IMO 2025 得到 35/42,USAMO 2026 得到 36/42。
MSA 让每个查询组只看 2048 个被选中的 KV token,在 1M 上下文报告 28.4 倍注意力 FLOPs 降低、14.2 倍 prefill 加速。
SpatialClaw 用持久 Python kernel 替代僵硬工具调用,在 20 个空间推理基准上达到 59.9% 平均准确率,比近期 spatial agent 高 11.2 点。
AI 智能体 · Renmin University of China
Arbor 用持久假设树管理科研尝试,6 个 AO 任务 held-out 结果全胜,MLE-Bench Lite Any Medal 达 86.36%。
AI 智能体 · TokenRhythm Technologies
Claw-SWE-Bench 用 350 个 issue 测 coding-agent harness,完整 adapter 让 OpenClaw Pass@1 升至 73.4%。
专家混合 · Renmin University of China
MPI 让 MoE 路由行对齐专家权重的主奇异方向。11B MoE 平均 benchmark 准确率从 40.92 升到 42.76,训练只慢 0.2%。
AI 智能体 · Independent Researcher
AdaPlanBench:测试智能体自适应规划把约束下的自适应规划变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
ALE 用 1490 个专家构建的专业任务测试智能体,覆盖 55 个数字行业,最难档平均完整通过率只有 2.6%。
AnchorWorld:具身视角世界模拟把自我视角世界模拟变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
AI 智能体 · Independent Researcher
ArcANE:角色扮演智能体何时出戏把角色扮演语言智能体可靠性变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
Brain-Diffuser:fMRI 自然场景重建把从 fMRI 信号重建自然场景落到具体方法和可检查结果上,适合判断该方向的真实进展。
BYOL:没有负样本的自监督学习把无负样本自监督视觉学习落到具体方法和可检查结果上,适合判断该方向的真实进展。
CoVEBench:视频编辑能否听懂复杂指令把视频编辑复杂指令遵循变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
DeepLab:空洞卷积语义分割把语义图像分割落到具体方法和可检查结果上,适合判断该方向的真实进展。
扩散语言模型 · Independent Researcher
扩散语言模型的机会与难题把扩散语言模型研究现状落到具体方法和可检查结果上,适合判断该方向的真实进展。
DistilBERT:更小更快的 BERT把紧凑语言模型的知识蒸馏落到具体方法和可检查结果上,适合判断该方向的真实进展。
DIRECT:三维感知的对象插入把三维感知对象插入变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
DreamDiffusion:从 EEG 生成图像把从 EEG 信号生成图像落到具体方法和可检查结果上,适合判断该方向的真实进展。
TELBench 让模型在十余步的研究轨迹里找出坏掉的那一段。DRIFT 用主张对证据的审计法,把 span 级宏 F1 推到 54.91%,比直接喂原始轨迹最高高出 30 个百分点。
生物分子建模 · Independent Researcher
DynamicMPNN:多状态蛋白质设计把多构象蛋白质序列设计落到具体方法和可检查结果上,适合判断该方向的真实进展。
E5:弱监督对比文本向量把通用文本向量落到具体方法和可检查结果上,适合判断该方向的真实进展。
世界模型 · JD.com (Joy Future Academy)
镜头转回旧场景时,块状状态空间循环拿到 69.0 的开放域一致性分,无记忆基线只有 12.25;激进压缩与空间摘要几乎全军覆没。
扩散语言模型 · Independent Researcher
扩散语言模型的无因子化误差解码把离散扩散语言模型的投机解码落到具体方法和可检查结果上,适合判断该方向的真实进展。
生物分子建模 · Independent Researcher
Feynman-Kac 引导可控蛋白设计把用引导扩散做可控蛋白设计落到具体方法和可检查结果上,适合判断该方向的真实进展。
Function2Scene:按功能生成室内三维布局把功能驱动三维场景布局变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
扩散模型 · The Hong Kong Polytechnic University
GGT-100K:图像修复的生成式真值把真实图像修复数据变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
AI 智能体 · University of Illinois Urbana-Champaign
Harness-1 是个 20B 的 RL 搜索智能体,把工作记忆交给环境维护,平均策展召回 0.730,比最强开源子智能体高 11.4 分。
HOList:高阶逻辑定理证明环境把面向高阶逻辑证明的机器学习落到具体方法和可检查结果上,适合判断该方向的真实进展。
综述把长视频 MLLM 重构为「看-记-想」三种能力,对比 11 篇已有综述,梳理 100+ 方法与 5 个应用领域。
AI 智能体 · Independent Researcher
K-BrowseComp:韩语网页智能体基准把韩语语境网页浏览智能体变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
AI 智能体 · Shanghai Jiao Tong University
超网络一次前向就把文本技能编译成 LoRA。ALFWorld 成功率涨 21.4 分,prefill token 省 64.1%。
LeanDojo:检索增强定理证明把Lean 中的检索增强定理证明落到具体方法和可检查结果上,适合判断该方向的真实进展。
把 3 个独立大模型的输出分布做平均,水印检测 z 分数从 5-304 直接掉到 2 以下,WASH 还给出了 O(1/根号N) 的误差证明。
按数学→代码→问答→写作顺序做 RL 后训练,数学从峰值 66.49 跌到 57.66,可梯度看上去却是正交的。末尾补一段短数学复习,数学回到 66.04,其余三域几乎不动。
长语音生成的综合基准把长语音生成变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
清华 LongTraceRL 从搜索智能体轨迹挖更难的干扰文档,再加实体级 rubric 奖励,让 Qwen3-4B 五个长上下文基准平均分从 53.3 涨到 59.0。
MAE:可扩展视觉掩码自编码器把视觉预训练中的掩码图像建模落到具体方法和可检查结果上,适合判断该方向的真实进展。
Mask R-CNN:实例分割经典框架把实例分割落到具体方法和可检查结果上,适合判断该方向的真实进展。
AI 智能体 · Independent Researcher
搜索智能体何时该屏蔽旧观察把搜索智能体上下文管理变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
MinD-Vis:用扩散模型解码大脑视觉把基于 fMRI 的图像重建落到具体方法和可检查结果上,适合判断该方向的真实进展。
MiniF2F:形式化奥赛数学基准把形式化奥赛级数学评测落到具体方法和可检查结果上,适合判断该方向的真实进展。
MobileBERT:端侧紧凑 BERT把面向端侧的 BERT 压缩落到具体方法和可检查结果上,适合判断该方向的真实进展。
MMAE:大规模音频编辑基准把音频编辑评测变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
OpenSkill 让智能体从开放网络自建技能与验证器,SkillsBench 上达 43.6%(+8.9),全程不碰目标任务答案。
多模态模型 · Shanghai AI Laboratory
OVO-S-Bench:流式空间智能评测把流式空间智能变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
生物分子建模 · Independent Researcher
ProGen2:蛋白质语言模型设计蛋白把蛋白质序列建模与设计落到具体方法和可检查结果上,适合判断该方向的真实进展。
AI 智能体 · Shanghai AI Laboratory
ResearchClawBench:自主科研智能体基准把端到端自主科研智能体变成可检查任务,帮助读者判断系统在哪里失效、结果应如何解读。
CHERRL 主动给裁判注入四类已知偏见,让奖励黑客稳定复现;只读训练日志的检测 agent 把六次实验的起点定位区间误差合计压到 11 步,零漏检。
SAAS 用自我感知强化学习,把 Qwen2.5-7B 搜索智能体的平均检索次数从 2.19 降到 0.97,准确率仍贴近最优基线(48.7% vs 49.8%)。
强化学习 · University of Edinburgh
SCOPE 让出题的 Challenger 与检索作答的 Solver 互相进化,靠一份冻结的自评委打分,八个开放基准最高提升 +10.4 分,且不用任何人工标注的提示。
扩散语言模型 · Independent Researcher
SEDD:用概率比率做离散扩散语言模型把离散扩散语言建模落到具体方法和可检查结果上,适合判断该方向的真实进展。
Sentence-BERT:孪生 BERT 句向量把用于语义相似度的句向量落到具体方法和可检查结果上,适合判断该方向的真实进展。
SimCSE:对比学习句向量把对比式句向量学习落到具体方法和可检查结果上,适合判断该方向的真实进展。
SimCLR:对比学习视觉表征把对比式视觉表征学习落到具体方法和可检查结果上,适合判断该方向的真实进展。