OpenSkill:无监督下的自进化 LLM 智能体
OpenSkill 让智能体从开放网络自建技能与验证器,SkillsBench 上达 43.6%(+8.9),全程不碰目标任务答案。
快速答案
OpenSkill 是一个让已部署的 LLM 智能体在面对新任务时自我提升的框架,关键在于全程不接触该任务的答案、人工整理的技能、或现成的打分验证器。它转而从开放世界资源(文档、代码库、网页)里抓取知识和验证线索,蒸馏成可复用技能,再用自己写的”虚拟测试”来打磨这些技能。
最亮眼的数字:在 SkillsBench(11 个领域)上,OpenSkill 配合 Claude Code(Opus 4.6)拿到 43.6% 的总通过率,比最强基线高出 8.9 个点,距离 44.5% 的人类参考线只差不到一个点;配合 Codex(GPT 5.2)则是 42.1%(+8.8)。但要先说清楚:这套方法只在你确实无法提供任务监督时才有意义。如果你有答案,普通技能库更省钱。
OpenSkill 想破解的”监督陷阱”
多数所谓”自进化智能体”其实都偷偷用了答案。技能库方法假设有人已经整理好优质技能;验证器反馈方法假设奖励信号现成存在;连检索方案也常常是从目标任务自己的材料里检索。可一旦智能体部署后撞上真正陌生的任务(一个新 API、一个内部工具、一个不熟的领域),这些拐杖全都没了。
OpenSkill 直面问题最难的版本:任何形式的目标任务监督都不给。 没有答案,没有标准测试,没有人工技能种子。智能体唯一能依靠的就是开放世界,而这恰恰是人类工程师会去翻的东西:文档、GitHub 仓库、博客、问答帖。它的贡献在于证明:技能和打分信号都能从这堆原始材料里”造”出来。
三阶段流程如何运转
第一阶段:开放世界知识获取。 智能体检索两类截然不同的东西:任务相关知识(怎么做)和验证锚点(怎么判断做对没有)。把两者分开很关键,正是第二类检索,后面才让智能体能给自己打分。
第二阶段:无泄漏技能进化。 这是核心循环。智能体先起草初版技能,然后基于验证锚点(而非任何真实答案)构建一套虚拟测试集。它让技能跑这些虚拟测试,再用一个带”缺口 vs. 缺陷”分类器的诊断驱动精修循环:技能失败是因为缺能力(缺口)还是实现出错(缺陷)?这个区分决定了修复方向。虚拟测试源自开放世界的验证知识,绝不来自隐藏的目标答案,这正是循环保持无泄漏的原因。
第三阶段:零样本目标评测。 只有到了评测这一步,真正的标准答案测试才出现,而智能体从未针对它训练过。
关键结果
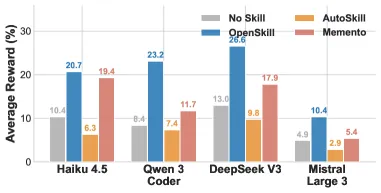
- SkillsBench,Opus 4.6: 43.6% 总通过率,对比 Skill-Creator 的 34.7%,即比最强基线高 8.9 个点,人类参考线为 44.5%。也就是说,OpenSkill 在无监督下补上了大部分人机差距。
- SkillsBench,GPT 5.2: 42.1%,对比思维链基线 33.3%(+8.8),人类参考线 44.8%。
- SocialMaze(6 个子任务): Opus 4.6 拿 82.7%(对比 Skill-Creator 的 81.0%),GPT 5.2 拿 70.7%(对比 69.8%)。
- ScienceWorld: Opus 4.6 拿 90.0%(对比 SkillNet 的 88.7%),GPT 5.2 拿 85.3%(对比 83.1%)。
- 自建验证器对齐度: 虚拟验证器在从未访问真值的情况下,达到 80.5% 召回率和 56.9% 精确率,对真值测试意图的覆盖率为 88.9%。
对这些数字给两点诚实的解读。其一,SkillsBench 上的大幅提升(+8.9/+8.8)才是真正的看点:这个基准恰恰是”从零造技能”最能发力的地方。而在 SocialMaze 和 ScienceWorld 上,差距很薄(1–2 个点),所以 OpenSkill 的优势是看任务的,并非普适。其二,验证器 56.9% 的精确率意味着它误报了不少”假失败”;高召回搭配中等精确率,说明它倾向于”宁可错杀”,对一个自打分器来说这是更安全的失败方向,但代价是多耗迭代。
为什么是现在
技能正在成为智能体的一等公民(Claude Code skills、Codex)。悬而未决的问题是:智能体能否在实战中自己长出技能,既不靠人工整理也不靠基准打分。OpenSkill 给出了证据:自建验证器能与隐藏真值保持约 80% 的对齐,且 Opus 生成的技能能迁移到其他模型(图 3)。正是这一点让”无监督”这个说法从口号落到实处。
局限与存疑
- 来源噪声。 网页和仓库内容可能过时或自相矛盾;框架依赖来源溯源与校验,论文承认这点但未彻底解决。
- 虚拟测试可能太简单。 自写测试若难度不够,会高估技能质量;若不慎编码进隐藏答案或验证器行为,无泄漏的保证就悄悄破功了。
- 成本与延迟。 开放世界检索比闭环技能生成更贵更慢,所以那 +8.9 的提升背后是一笔论文未按任务量化的算力账。
- SkillsBench 之外的差距很薄。 在 SocialMaze 和 ScienceWorld 上提升只有一两个点,别指望普遍受益。
常见问题
OpenSkill 和普通的智能体技能库有什么不同?
技能库假设有人已经整理好优质技能,而且往往还配了打分方式。OpenSkill 两者都不假设。它既获取技能,又从开放世界自己造出验证信号,全程不用目标任务答案。“无监督”这个约束就是它的全部意义所在。
OpenSkill 在 SkillsBench 上真的超过人类了吗?
还没有。它配合 Opus 4.6 达到 43.6%,而人类参考线是 44.5%,很接近但仍偏低。值得注意的是它在零任务监督下逼到这么近,而不是超过人类。
如果我已经有标注任务或验证器,还该用 OpenSkill 吗?
大概率不该。OpenSkill 的价值恰恰在于你无法提供监督的场景。如果你手里有标准答案或真实奖励信号,更简单的监督式技能方法更省钱,也免去了额外的开放世界检索成本和延迟。