Claw-SWE-Bench: Why Coding Agent Harnesses Matter
Claw-SWE-Bench evaluates OpenClaw-style coding-agent harnesses on 350 GitHub issue tasks. OpenClaw jumps from 19.1% to 73.4% Pass@1 with a full adapter.
Quick answer
Claw-SWE-Bench is a SWE-bench-style benchmark for evaluating coding-agent harnesses, not just base models. It contains 350 GitHub issue-resolution instances across 8 programming languages and 43 repositories, plus an 80-instance Lite subset for cheaper iteration. The headline number is blunt: on the full benchmark, OpenClaw with a minimal direct-diff adapter scores 19.1% Pass@1, while the full adapter reaches 73.4% with the same GLM 5.1 backbone.
What Claw-SWE-Bench measures
SWE-bench expects a clean Docker workspace, a patch, and a prediction contract. A general-purpose agent such as OpenClaw may be good at tool use, but it does not automatically satisfy that contract. Claw-SWE-Bench adds an adapter protocol so heterogeneous agent harnesses, or “claws,” can be compared under the same prompt, runtime budget, workspace contract, patch extraction, and evaluator.
That distinction matters. If an agent fails because its harness cannot extract the right patch, cannot manage the workspace, or stops at the wrong time, the model score alone is misleading. The paper argues that harness design is a first-class variable in coding-agent evaluation.
Why the Lite subset is useful
The full benchmark has 350 instances, which is expensive when each run involves a long agent loop. Claw-SWE-Bench Lite selects 80 instances with a cost-aware, rank-aware procedure over 17 calibration columns. The goal is not to make a friendly demo set. The Lite subset tries to preserve rankings, language coverage, and cost structure so teams can debug harnesses without repeatedly paying for the full benchmark.
The paper reports that Lite-80 reduces full-run cost to about 22.9% of full-350. Across the 17 calibration columns, mean Pass@1 is 0.639 on full-350 and 0.643 on Lite-80, a difference of about 0.4 percentage points.
Key results
- Benchmark size: 350 issue-resolution instances, 8 languages, and 43 repositories.
- Lite subset: 80 instances covering 34 of 43 repositories, or 79% of the full repository set.
- Adapter effect: OpenClaw on GLM 5.1 rises from 19.1% Pass@1 with a minimal direct-diff adapter to 73.4% with the full adapter.
- Model axis: in the OpenClaw by nine-model sweep, model choice changes Pass@1 by 29.4 percentage points.
- Harness axis: in the five-claw by two-model sweep, harness choice changes Pass@1 by 27.4 percentage points under fixed models.
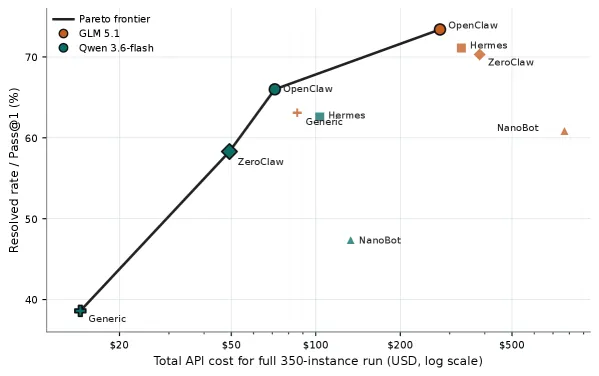
- Cost: systems with similar Pass@1 can have different total API costs, so the paper reports cost, token use, and cache hit rate beside accuracy.
The most useful takeaway is that harness variation can be almost as large as model variation. A benchmark that hides the harness behind a model name can rank the wrong thing.
What future-commit cleanup changes
The paper also cleans up future-commit visibility. In SWE-style tasks, an agent can sometimes see repository history that leaks information from after the issue. After cleanup, Pass@1 does not increase for any of the nine OpenClaw model runs; the largest reported drop is Claude Opus 4.7 from 84.7% to 76.7%, an 8.0 percentage-point decrease.
That is a useful sanity check. It shows that contamination treatment can change rankings, and it gives readers a reason to prefer the cleaned numbers.
Limits and open questions
The main experiments are single-run aggregates, so small differences should not be treated as stable superiority. The claw sweep covers five harnesses and two models, enough to prove that harness choice matters, but not enough to map every interaction between model family, tool loop, parser, stopping rule, and cost. Provider pricing and cache accounting also affect the reported cost numbers.
There is a broader question too: does the same model-harness non-separability hold for browser agents, desktop agents, and research agents? Claw-SWE-Bench answers it for SWE-style coding tasks, not every agent domain.
FAQ
What is Claw-SWE-Bench?
Claw-SWE-Bench is a multilingual SWE-bench-style benchmark and adapter protocol for evaluating coding-agent harnesses on real GitHub issue-resolution tasks.
How large is Claw-SWE-Bench?
The full benchmark has 350 instances across 8 programming languages and 43 repositories. Claw-SWE-Bench Lite has 80 instances for lower-cost validation.
Why does OpenClaw improve from 19.1% to 73.4% Pass@1?
The 19.1% result uses a minimal direct-diff adapter, while 73.4% uses the full adapter with the same GLM 5.1 backbone. The gap shows that adapter and harness design strongly affect coding-agent scores.
Is Claw-SWE-Bench Lite a replacement for the full benchmark?
No. Lite-80 is for screening, debugging, and regression checks. It reduces cost to about 22.9% of full-350 while preserving aggregate Pass@1 closely in the calibration study.
What is the main limitation of Claw-SWE-Bench?
The current results are mostly single-run aggregates over a limited harness and model sweep. Wider replication is needed before small Pass@1 differences are treated as durable.
One line: Claw-SWE-Bench is useful because it stops treating the coding agent harness as invisible plumbing. Read the original paper on arXiv.