DeNovoSWE: 4,818 Auto-Built Repos to Train Whole-Repo Code Agents
DeNovoSWE auto-constructs 4,818 verifiable whole-repository generation tasks. Fine-tuning Qwen3-30B-A3B on them lifts BeyondSWE-Doc2Repo pass rate from 0.058 to 0.472.
Quick answer
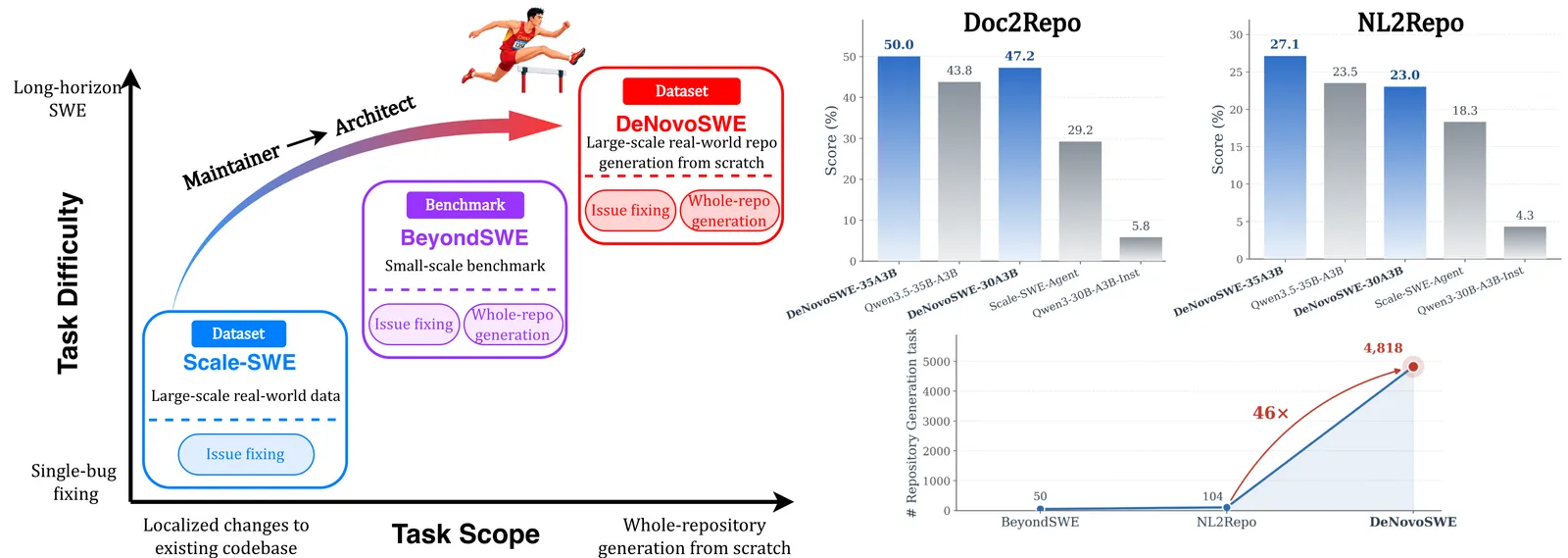
DeNovoSWE is both a dataset and a training recipe for code agents that write an entire repository from a specification, not patch a single bug. The dataset has 4,818 instances, each asking a model to regenerate a full repo from capability documentation, and each instance ships with executable unit tests so the result is graded automatically. Fine-tuning Qwen3-30B-A3B-Instruct on this data raises its pass rate on the BeyondSWE-Doc2Repo benchmark from 0.058 to 0.472, and the 35B-A3B variant reaches 0.500. The grading metric is the fraction of unit tests that pass, averaged over rollouts in a sandboxed Docker container. The honest framing: this is a small-model fine-tuning win on a hard new task, not a frontier result, since proprietary models like GPT-5.4 (0.563) and GLM-5 (0.568) still score higher.
What the task actually is
Most SWE training data is localized: SWE-bench-style issues hand the model a working repo and ask for a patch. DeNovoSWE targets the opposite end. The model gets only capability documentation and must produce the whole repository, file layout, implementations, and all, so its output runs the project’s tests. The closest prior dataset, NL2Repo, had 104 instances; DeNovoSWE is roughly 46 times larger at 4,818, which is the point, because long-horizon repo generation is exactly the regime where a few hundred examples cannot teach a model the habit.
The catch with this task is verification. A patch can be checked against a known-good test suite. A from-scratch repo has no test suite until you build one, and a test suite written by the same model that writes the code is circular. DeNovoSWE’s construction is mostly an answer to that problem.
How the repos are auto-constructed
The pipeline reverse-engineers tasks from real repositories using a divide-and-conquer plus critic-repair workflow, with no human annotation.
The divide phase partitions a source repo into functional capabilities. It runs the existing unit tests, traces runtime to label each function or class as direct, core-indirect, or non-core-indirect to that capability, then maps components to capabilities with an LLM classifier. The conquer phase builds the documentation that becomes the task prompt: a draft agent writes initial capability docs with sandboxed read access to the source, a critic agent flags gaps in structure, coverage, and API specification, and a repair agent patches those gaps. The per-capability documents merge into one repo-level spec.
Because the tests come from the original repo, not from the generating model, the verification is grounded. The generated repo is graded by how many of those real tests it passes. That sidesteps the circularity, though it also means the task is “rebuild a repo that already exists” rather than “invent a novel repo,” a distinction the benchmark name (Doc2Repo) makes honestly.
How scoring and leakage control work
Each instance is scored as passed unit tests over total unit tests, averaged across rollouts, all inside a Docker sandbox with restricted network and package access. The interesting engineering is the leakage defense, because the reference repo physically exists in the construction environment and a lazy agent could just copy it. DeNovoSWE purges site-packages traces, hidden pip wheel caches, and compilation artifacts; it destroys and reinitializes .git so the agent cannot recover the original code from reflog or loose objects; and it blocks clone, pip install, and curl/wget aimed at the reference, with an LLM-as-judge auditing execution traces for cheating. This is the part a builder reusing the data should read closely, since it is where a sloppy reimplementation would silently inflate scores.
Key results
- Qwen3-30B-A3B-Instruct: 0.058 to 0.472 on BeyondSWE-Doc2Repo after fine-tuning on DeNovoSWE. That is an 8x relative jump and the headline claim. Pass rate here is mean fraction of unit tests passed, not full-repo all-or-nothing.
- 35B-A3B variant: 0.438 to 0.500. The stronger base starts much higher (0.438) and gains less in absolute terms, so most of the dramatic lift is from rescuing a weak base, not from a uniformly large effect.
- Still below frontier proprietary models: GPT-5.4(CodeX) 0.617, GLM-5 0.568, DeepSeek-V4-Pro 0.566, GPT-5.4 0.563, Gemini3-Pro 0.520. DeNovoSWE-Agent-30A3B (0.472) closes much of the gap but does not pass them.
- Beats the prior agent baseline: Scale-SWE-Agent scores 0.292; the fine-tuned 30B-A3B reaches 0.472 at a far smaller size.
- Difficulty-aware filtering helps, modestly: instance-specific thresholds (0.90 for easiest down to 0.60 for hardest, tuned by Pearson correlation with empirical pass rate) reach 0.500 vs 0.488 for the best fixed threshold. The team keeps partial-success trajectories on hard instances because fully successful rollouts are rare.
- Scale: 4,818 instances, ~46x NL2Repo’s 104. The contribution is volume on a task where prior data was too thin to train on.
Limits and open questions
The benchmark measures reconstruction, not invention. Doc2Repo asks a model to regenerate a repository whose documentation was derived from that same repository’s tests, so a high score proves the model can rebuild a documented codebase, not that it can architect something new from a vague product spec. The pass-rate metric is per-test, so 0.472 does not mean 47% of repos run end to end; partial credit inflates the number relative to a strict all-tests-pass bar. The paper reports no token, wall-clock, or dollar cost for either the construction pipeline (which runs several LLM agents per instance) or the long-horizon rollouts at eval, so the efficiency of this data-generation loop is unmeasured. The leakage defenses are specific and thoughtful, but their completeness rests on the LLM-as-judge audit, itself unvalidated against an adversarial agent. Reproducibility depends on the promised release of the dataset and construction code; without the difficulty-weight tuning recipe, the 0.500 ablation result is hard to rebuild.
FAQ
What is DeNovoSWE and what task does it cover?
DeNovoSWE is a dataset and fine-tuning recipe for whole-repository generation: producing an entire codebase from capability documentation rather than patching one bug. It has 4,818 auto-constructed instances, each with executable unit tests for grading, and is used to train long-horizon SWE agents like Qwen3-30B-A3B.
How does DeNovoSWE get Qwen3-30B-A3B from 0.058 to 0.472 on BeyondSWE-Doc2Repo?
By supervised fine-tuning on the 4,818 DeNovoSWE instances. The base Qwen3-30B-A3B-Instruct scores 0.058 pass rate on BeyondSWE-Doc2Repo; after training on DeNovoSWE trajectories it reaches 0.472. The metric is mean fraction of unit tests passed across rollouts, not full-repo success.
Is DeNovoSWE 0.472 better than GPT-5.4 on whole-repo generation?
No. DeNovoSWE-Agent-30A3B reaches 0.472, while GPT-5.4(CodeX) scores 0.617 and plain GPT-5.4 0.563 on the same BeyondSWE-Doc2Repo benchmark. The result is a strong small-model fine-tuning gain that narrows the gap to proprietary models, not a frontier-beating score.
How does DeNovoSWE prevent the agent from copying the reference repository?
The construction sandbox purges site-packages traces, pip wheel caches, and compilation artifacts, destroys and reinitializes .git so the original code cannot be recovered from reflog or loose objects, and blocks clone/pip install/curl aimed at the reference, with an LLM-as-judge auditing execution traces for cheating.
Is DeNovoSWE a dataset paper or a training method?
Both. The dataset is the 4,818 auto-built verifiable instances; the method is the divide-and-conquer plus critic-repair construction pipeline and the difficulty-aware trajectory filtering used to fine-tune small code models on long-horizon repo generation.
For agent-side context on how long-horizon coding agents explore and act, see SWE-Explore on repository exploration and the batch siblings Orchestra-O1 on agent orchestration and Beyond Uniform Token Trust Region on RL for agents.
One line: DeNovoSWE shows that whole-repo generation, the hardest long-horizon SWE task, can be turned into 4,818 auto-verified training examples, lifting a weak 30B model 8x without a frontier base. Read the original paper on arXiv.