Multimodal Models · Vision Foundation Models · Video Generation
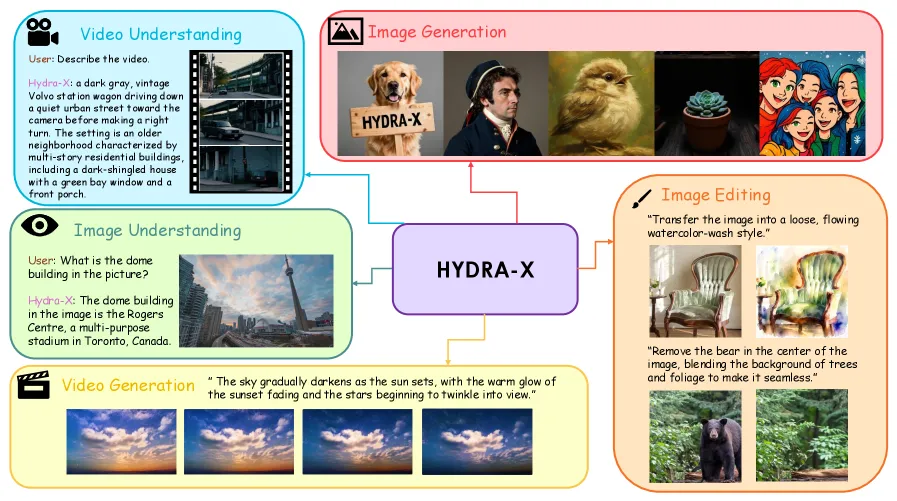
HYDRA-X: One Visual Tokenizer for Images and Video
HYDRA-X unifies image and video tokenization in one ViT; tubelet attention and hierarchical temporal patchify improve DAVIS rFVD to 11.19 and editing overall to 4.34.
Quick answer
HYDRA-X is a unified multimodal model built around one visual tokenizer for images and videos. The claim is architectural: image understanding, video understanding, image generation, video generation, and image editing should share a native ViT tokenizer rather than stitch together separate encoders. The most useful evidence comes from ablations. Tubelet attention plus hierarchical temporal patchify reaches DAVIS rFVD 11.19, better than full attention at 16.20 and causal attention at 14.05. For editing, source-target interaction inside the tokenizer raises reconstruction PSNR from 20.74 to 27.65 and ImgEdit from 2.80 to 3.20 in the controlled ablation.
The tokenizer is the argument
HYDRA-X starts from the belief that the visual tokenizer is not a boring adapter. If image and video are tokenized through different modules, the LLM has to reconcile mismatched representations. If a video tokenizer compresses time without semantic supervision, it may discard details that understanding needs. HYDRA-X keeps image and video in one ViT-based tokenizer and trains it for both reconstruction and semantic alignment.
The counterintuitive result is that less temporal attention works better. Full spatiotemporal attention sounds natural, but the ablation says it harms reconstruction. A 2-frame causal tubelet keeps local motion without mixing too much structure across frames. Hierarchical 2x2 temporal patchify also beats single-step 4x compression at the same ratio.
The Decompressor is used only during tokenizer training. It upsamples compressed video features back to frame rate so a video teacher can supervise them. At inference, the LLM still receives compact tokens. For editing, HYDRA-X routes source and target images as a length-2 clip so the tokenizer can align them before the LLM has to reason about the edit.
Key results
- On reconstruction ablation, the final design reaches ImageNet PSNR 31.73 and DAVIS PSNR 27.97, with DAVIS rFVD 11.19.
- Semantic distillation is necessary: removing it leaves MVBench at 29.8 and VideoMME at 27.4, while the video-teacher Decompressor setting reaches 45.4 and 45.0.
- Source-target interaction improves ImgEdit from 2.80 to 3.20 and source reconstruction PSNR from 20.74 to 27.65.
- On video understanding, the 7B HYDRA-X reports MVBench 59.1, Video-MME 60.0, LongVideoBench 59.5, and LVBench 30.0.
- On editing, HYDRA-X reports ImgEdit overall 4.34 and GEdit overall 7.17, beating listed unified baselines and BAGEL on the reported columns.
What builders should take from it
The practical takeaway is not to copy the headline number blindly. HYDRA-X is useful when a team can reproduce the paper’s setup and when the measured bottleneck matches its own product or research loop. The paper-specific evidence above tells builders where the gain comes from, what comparator was used, and which parts are still protocol-dependent. A good follow-up is to rerun the same idea on a local task distribution before treating it as a general capability upgrade.
The builder question is whether one tokenizer can reduce system complexity without flattening task-specific signal. HYDRA-X gives a plausible yes for editing and short video because the ablations connect architectural choices to PSNR, rFVD, ImgEdit, and video understanding metrics. It does not remove the need for specialized decoders or task losses.
Limits and open questions
HYDRA-X is a 7B unified system, so it should not be read as beating every specialized generation or video model. Dedicated and proprietary video models still lead some understanding metrics. The paper is strongest on the tokenizer design and ablation logic. Builders should care if they want one architecture to cover understanding, generation, and editing; they should wait for release details before assuming plug-and-play reproduction.
The missing evidence that would change the judgment is a broader external replication: more independent harnesses, clearer release artifacts, and stress tests designed by groups that did not build the method. Until then, the paper is best read as a strong directional result with a concrete evaluation surface.
FAQ
What is HYDRA-X?
HYDRA-X is a unified multimodal model that uses one ViT-based tokenizer for images and videos across understanding, generation, and editing tasks.
Why does HYDRA-X use tubelet attention?
The ablation shows full spatiotemporal attention worsens reconstruction. A 2-frame tubelet gives enough local temporal context while preserving per-frame structure.
How does HYDRA-X improve image editing?
It lets source and target images interact inside the tokenizer as a length-2 clip. In the ablation, that raises reconstruction PSNR from 20.74 to 27.65 and ImgEdit from 2.80 to 3.20.
One line: HYDRA-X matters because it makes the visual tokenizer carry image-video structure before the LLM sees the tokens. Read the original paper on arXiv.