AI Agents · LLM Reasoning · Interpretability
DRIFT: Pinpointing Where Deep-Research Agents Go Wrong
TELBench asks models to find the span that broke a 12-step research trajectory. DRIFT audits claims against evidence, lifting macro-F1 to 54.91% with Claude-Sonnet-4.6, up to 30 points over raw inspection.
Quick answer
When a deep-research agent fails, a final-answer score tells you that it failed, not where. DRIFT is a claim-auditing pipeline that reads an agent’s full trajectory (searches, tool calls, evidence, intermediate reasoning) and points at the specific span where an unsupported or contradicted claim poisons the answer. On the paper’s new TELBench (1,000 trajectories, ~11.95 semantic spans each), DRIFT with Claude-Sonnet-4.6 reaches 54.91% macro-F1 for span-level error localization, up to 30 percentage points above feeding the raw trajectory to the same model and asking it to spot the mistake.
The honest framing: even the best number here is below 55% F1, and first-error accuracy tops out at 24.10%. This is a hard, freshly-defined problem, not a solved one. The value is the benchmark and the decomposition, not a finished error detector.
The problem: outcome scores hide the failure point
Deep-research agents run long. A single GAIA or BrowseComp task can stretch across a dozen search-read-reason-act cycles before producing an answer. Standard evaluation checks only the last token: right or wrong. That tells a developer nothing actionable. Was the first query malformed? Did the agent hallucinate a date? Did it cite a real page but misread the number? Did an early wrong turn cascade?
The paper reframes debugging as span-level error localization: given a trajectory cut into semantic spans, identify which spans contain a harmful error. “Harmful” is the key qualifier. Exploratory dead-ends and failed-but-recovered queries are normal agent behavior and should not be flagged. The target is the span where a bad claim becomes load-bearing for the final, wrong answer.
Inside TELBench
The authors collected 2,790 raw trajectories across 2 agent frameworks (MiroFlow, OAgent), 3 backbone models (GPT-5, Gemini-2.5-Pro, Claude-Sonnet-4.5), and 3 benchmarks (GAIA-val, XBench, BrowseComp-test, downsampled to 200 tasks each, ~465 tasks total). Raw logs were normalized into semantic spans, then experts reviewed candidate harmful spans with LLM assistance. The result: TELBench, 1,000 verified instances (600 easy / 400 hard).
The error schema is the part worth keeping even if you ignore DRIFT itself: 18 primary faults in 6 families, namely Constraint Handling, Search & Retrieval, Evidence Grounding, Entity Mapping, Information Processing, and Process Control. This is a usable vocabulary for agent failure analysis. Mechanism analysis shows errors are not uniformly distributed across the trajectory; they cluster at certain operation stages, which is itself a useful prior for anyone building agent monitors.
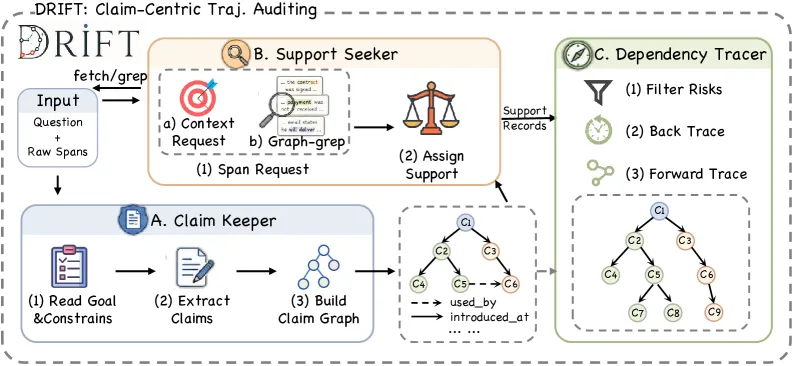
How DRIFT works
DRIFT doesn’t ask a model “where’s the bug?” in one shot. It decomposes the audit into three stages:
- Claim Keeper builds a ledger of every claim the agent introduces: when it appears, what it depends on, where it gets reused, its type, and its status.
- Support Seeker takes each consequential claim and assigns a support label by checking it against trajectory evidence: direct support, weak support, missing, or conflicting.
- Dependency Tracer finds the harmful spans by tracing which risky claims actually become commitments on the path to the final answer.
The insight is that a span is only worth flagging if a weakly-grounded or contradicted claim made there propagates into the answer. Auditing grounding rather than plausibility is what separates this from naive prompting. That distinction is the whole point.
Key results
- 54.91% macro-F1 overall, best configuration (Claude-Sonnet-4.6 + DRIFT). Easy split 60.00%, hard split 47.28%.
- Up to 30 percentage points macro-F1 gain over the bare baseline (the same model reading the raw trajectory directly).
- First-error accuracy peaks at 24.10%. Locating the span where things first went wrong is markedly harder than flagging any harmful span.
- Models evaluated span Qwen-series, GPT-5.4, DeepSeek-V3.2, Claude-Sonnet-4.6, and Gemini-2.5-Pro; agentic baselines included Codex and Claude Code reading trajectories directly.
- Ablations confirm each DRIFT module (claim ledger, support verification, dependency tracing) contributes, and the paper reports an accuracy-vs-cost trade-off since the multi-stage audit is more expensive than one-shot prompting.
Limits and open questions
The ceiling is low. Sub-55% F1 and ~24% first-error accuracy mean DRIFT is a research baseline, not a drop-in CI check for production agents. You cannot yet trust it to silently gate a release. TELBench is also bounded to the trajectories of a handful of frameworks and models on three QA-style benchmarks; whether the 18-fault taxonomy transfers to coding agents, long-horizon tool use, or multi-agent systems is untested. The expert-plus-LLM annotation process, while careful, bakes in judgment about what counts as “harmful,” and the multi-stage pipeline’s token cost is non-trivial. Anyone who only ships English single-agent QA pipelines may find the taxonomy more valuable than the detector.
FAQ
What is the difference between TELBench and DRIFT?
TELBench is the benchmark: 1,000 annotated deep-research agent trajectories with harmful error spans labeled, drawn from MiroFlow and OAgent runs on GAIA, XBench, and BrowseComp. DRIFT is the method the authors propose to solve it: a three-stage claim-auditing pipeline (Claim Keeper, Support Seeker, Dependency Tracer) that scores up to 30 points higher than feeding the raw trajectory to a model.
How good is DRIFT at finding agent errors?
On TELBench, DRIFT with Claude-Sonnet-4.6 reaches 54.91% macro-F1 for span-level localization and 24.10% accuracy at pinpointing the first error. Strong relative to baselines, but well short of reliable. Treat it as a debugging aid and a research target, not a verified release gate.
Why is span-level error localization hard for deep-research agents?
A trajectory averages ~12 semantic spans, and agents normally explore dead-ends and failed queries that are not errors. The task is to find the one span where an unsupported or contradictory claim becomes load-bearing for the wrong final answer. Distinguishing harmful errors from healthy exploration is exactly where one-shot prompting falls short.