Long Context · Reinforcement Learning · LLM Reasoning
LongTraceRL: Harder Distractors and Rubric Rewards for Long-Context RL
Tsinghua's LongTraceRL mines distractors from real search-agent trajectories and adds entity-level rubric rewards, lifting a Qwen3-4B reasoner from 53.3 to 59.0 average across five long-context benchmarks (+5.7).
Quick answer
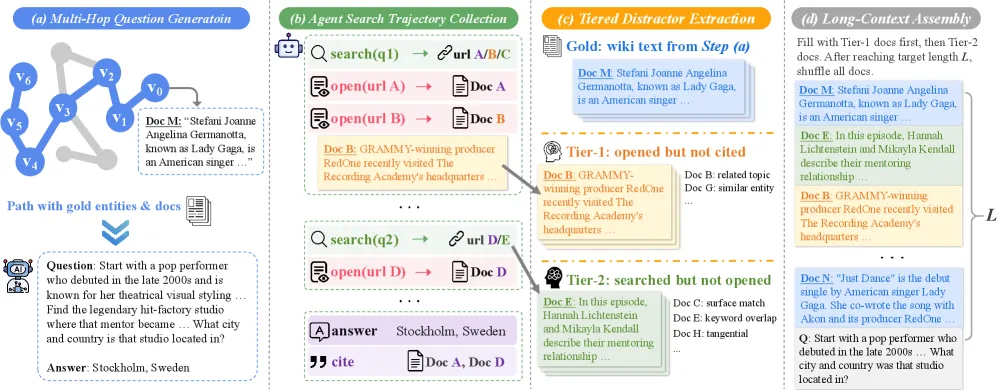
LongTraceRL is a reinforcement-learning recipe for long-context reasoning that fixes two weak points in the standard RLVR setup: the distractor documents are too easy, and the reward only checks the final answer. Both fixes come from one source, the trajectories of a search agent solving multi-hop questions. Documents the agent read but did not cite become hard distractors; the entities it had to chain through become a process-level reward signal.
The payoff, on Qwen3-4B-Thinking-2507: the five-benchmark average rises from 53.3 to 59.0 (+5.7). The biggest single jumps are on retrieval-heavy tasks, MRCR +9.6 and AA-LCR +8.6, exactly where “needle hidden in confusing context” is the bottleneck. It is a focused, well-motivated method rather than a new architecture, and the gains are real but uneven across benchmarks.
How the tiered distractors are built
The core insight is that a search agent already does the work of finding what is plausibly-relevant-but-wrong. When an agent answers a multi-hop question over Wikipedia, it issues searches, opens some documents, reads them, and cites a few. LongTraceRL turns that behavior into a difficulty signal:
- Tier-1 (high confusability): documents the agent opened and read but ultimately did not cite. These passed a relevance filter strong enough to make a capable agent click, so they are genuinely confusing: topically adjacent and entity-overlapping, but not the gold evidence.
- Tier-2 (low confusability): documents that showed up in search results but the agent never opened. Surface-level relevant, easy to dismiss.
Stuffing the training context with Tier-1 documents produces problems that are much harder than the usual practice of padding with randomly sampled passages. Random padding teaches a model to ignore obviously-unrelated text. Tier-1 padding forces it to discriminate between two passages that both look like the answer, which is the whole game in long-context QA.
Why the rubric reward matters
Outcome-only rewards have a known failure mode: a model can guess the right final answer while skipping or fabricating the intermediate reasoning, and RLVR happily reinforces that. LongTraceRL adds a rubric reward that scores entity recall along the reasoning chain. The gold entities are the ones the search agent actually had to traverse to reach the answer, so they form a checkable set of waypoints.
The reward is simple: the fraction of gold entities that appear in the model’s response. Critically, it is applied positive-only, so the rubric bonus is given only when the final answer is already correct. This is the design choice that earns its keep. If you rewarded entity mentions on wrong answers too, the model would learn to spray gold entities into the text to farm reward without actually reasoning. Gating the bonus on a correct outcome blocks that hack. Training runs the whole thing through GRPO with a composite reward that blends outcome and rubric terms, weighted by a single coefficient.
Key results
Lead with the numbers, all on Qwen3-4B-Thinking-2507 unless noted:
- Average across five benchmarks: 53.3 to 59.0 (+5.7).
- MRCR: 36.2 to 45.8 (+9.6), the largest gain, on multi-round coreference retrieval.
- AA-LCR: 33.2 to 41.8 (+8.6), expert-crafted ~100K-token questions.
- LongReason: 78.5 to 83.8 (+5.3).
- FRAMES: 76.7 to 79.5 (+2.8) and LongBench v2: 41.7 to 44.1 (+2.4), the smaller cases where the baseline was already strong.
- Scaling holds across model sizes: Qwen3-30B-A3B-Thinking-2507 rises 60.5 to 63.7, and DeepSeek-R1-0528-Qwen3-8B improves 42.7 to 43.8.
- Ablation: dropping the rubric reward (GRPO with tiered distractors only) lands at 53.7 versus 59.0 with rubric at the chosen mixing weight, isolating the rubric reward’s contribution.
The pattern is consistent. Gains are largest where the task is dominated by finding the right needle among confusable distractors (MRCR, AA-LCR), and smallest where the baseline is already high (FRAMES, LongBench v2).
Limits and open questions
The honest scope is narrow. The training data is built from KILT Wikipedia knowledge graphs, so question diversity is encyclopedic, multi-hop factual QA, not code, math, or domain-specialist long documents. Whether the same distractor-mining trick transfers to non-Wikipedia corpora is untested.
Everything also rides on the search agent’s quality. The distractor tiers and the gold-entity set are defined by what one particular agent read and cited; a weaker agent produces easier distractors and a noisier rubric, a stronger one the opposite. That makes the method somewhat self-referential: the supervision signal inherits the agent’s blind spots. The DeepSeek-R1-8B gain (+1.1) is also notably smaller than the 4B and 30B Qwen gains, hinting that the recipe is best tuned to the Qwen3-Thinking family it was developed on. Anyone with long contexts that are not entity-dense Wikipedia QA should treat the headline +5.7 as an upper bound, not a promise.
FAQ
What is the difference between LongTraceRL’s tiered distractors and normal RLVR negative sampling?
Standard RLVR pads the context with randomly sampled passages, which are usually easy to rule out. LongTraceRL instead uses documents a search agent read but did not cite (Tier-1), passages relevant enough to fool a capable reader. This produces a harder, more realistic discrimination task than random padding.
How does the LongTraceRL rubric reward avoid reward hacking?
The rubric reward scores how many gold entities appear in the response, but it is applied positive-only: the bonus is granted only when the final answer is already correct. A model cannot game it by dumping entities into a wrong answer, because wrong answers receive zero rubric credit.
Does LongTraceRL only work on small models?
No. The gains span scales: +5.7 average on Qwen3-4B-Thinking, and +3.2 (60.5 to 63.7) on the 30B-A3B MoE model. The improvement on DeepSeek-R1-0528-Qwen3-8B is smaller (+1.1), suggesting the recipe is best matched to the Qwen3-Thinking family it was tuned on.