Long Context · Efficient AI · Transformers
MiniMax Sparse Attention: 1M Context Without Dense Attention
MiniMax Sparse Attention keeps only 2,048 selected KV tokens per query group and reports 28.4x lower attention FLOPs plus 14.2x prefill speedup at 1M context.
Quick answer
MiniMax Sparse Attention (MSA) is a production-minded sparse attention design for million-token contexts. Instead of making every query attend to the full history, an Index Branch scores key-value blocks and selects 16 blocks of 128 tokens, so each query group attends to 2,048 KV tokens. The headline result is concrete: on the paper’s 109B native multimodal model, MSA reports 28.4x lower per-token attention FLOPs at 1M context, with 14.2x prefill and 7.6x decoding wall-clock speedups on H800, while benchmark quality stays close to dense GQA.
The mechanism: sparse attention that keeps the old stack
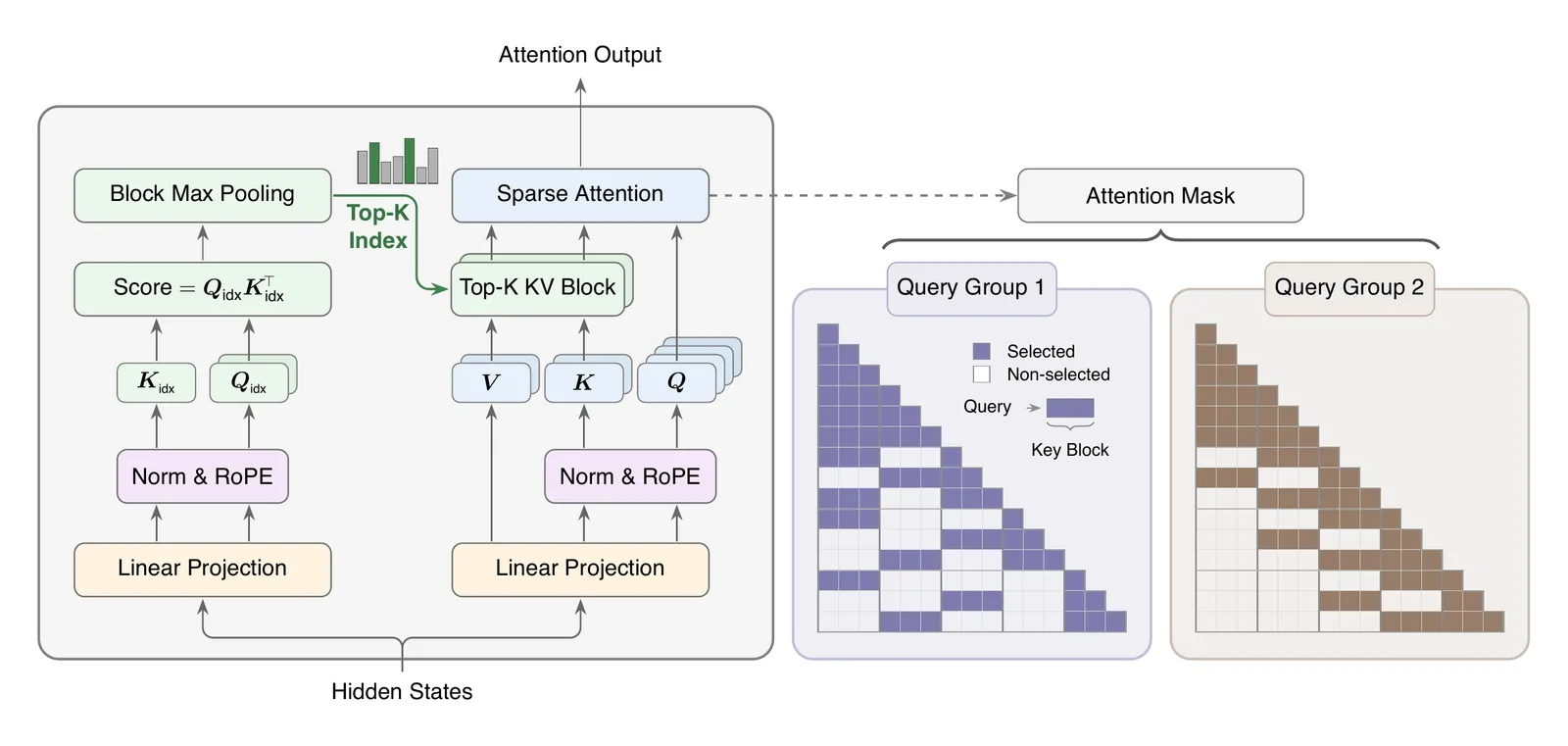
MSA is not a new sequence model. It keeps the softmax-attention path and changes which blocks enter that path. For each query and GQA group, a lightweight Index Branch scores visible key tokens, pools those scores to blocks, selects the top-k blocks, and always keeps the local block. The Main Branch then runs exact softmax attention over the selected blocks only.
That design choice matters. Many efficient-attention papers ask teams to accept a different architecture or a hard-to-serve kernel. MSA tries to preserve the shape of existing transformer infrastructure: GQA remains the backbone, the selected blocks are ordinary KV blocks, and the speed claim depends on a co-designed sparse kernel rather than only a complexity argument.
The training signal is also conservative. The Index Branch is trained with a KL objective that matches the distribution of the Main Branch over selected blocks, while gradients from the index path are detached from the main attention path. In plain terms, the indexer learns to imitate where full attention would spend probability mass without being allowed to destabilize the main model.
Why the 2,048-token budget is the real test
The strongest claim is not just “sparse is faster.” The paper fixes the selected budget at 16 blocks times 128 tokens, or 2,048 KV tokens, then asks whether long-context ability survives. That is a tight budget for 128K to 1M contexts. If it works, the method has a clearer deployment story than systems where sparsity shrinks only mildly as context grows.
The evidence is mixed in the useful way. MSA-CPT after long-context extension scores 45.93 overall on HELMET-128K versus 46.53 for full attention, a 0.60 point drop. On RULER-128K it scores 72.12 versus 72.00, essentially tied. The paper also reports benchmark-level variance: Rerank/RAG drops 2.10 points, while MK/MQ/MV improves 2.24 points. That looks like a real tradeoff, not a magic replacement.
Key results
- 1M context efficiency: MSA reports 28.4x lower per-token attention FLOPs than dense GQA at 1M context under the same query/KV head setup.
- Wall-clock speed: on H800, the co-designed kernel reaches 14.2x prefill speedup and 7.6x decoding speedup at 1M context.
- Fixed attention budget: each query and GQA group attends to 2,048 KV tokens, using 16 selected blocks of 128 tokens.
- General benchmarks: under a 3T-token training budget, MSA-PT is close to full attention on broad evaluations and sometimes better, including MMLU 67.2 versus 67.0 and GSM8K 77.7 versus 76.2.
- Long-context extension: MSA-CPT after 140B long-context tokens is near full attention on HELMET-128K and RULER-128K, with -0.60 and +0.12 overall deltas.
What builders should take from it
For model teams, the useful part is the conversion route. MSA-PT trains sparse from scratch, but MSA-CPT starts from a dense checkpoint and continues pretraining with sparse attention. That matters because most serious labs already have dense checkpoints and need a migration path, not a clean-room architecture.
For inference engineers, the warning is that FLOPs are not latency. The paper says the same thing indirectly: runtime speedups are much smaller than the 28.4x FLOPs reduction because sparse attention adds index construction, top-k selection, query gathering, reverse indexing, and load balancing. MSA is still fast in the reported setup, but the kernel is part of the result.
Limits and open questions
MSA is evaluated inside MiniMax’s own model and kernel stack. The paper releases an inference kernel, but the easiest reading is still “this worked in one highly engineered production environment.” Portability to other model sizes, GPU families, and serving systems remains an implementation question.
The second limit is retrieval shape. A 2,048-token selected budget is enough for many long-context tasks, but some tasks require combining many weak pieces of evidence across the context. Those are exactly the cases where top-k block selection can miss useful information without obvious failure signs. Aggregate HELMET and RULER scores are encouraging, but they do not fully replace adversarial evidence-integration tests.
FAQ
What is MiniMax Sparse Attention?
MiniMax Sparse Attention is a blockwise sparse attention method for GQA transformers. It uses a lightweight Index Branch to select top key-value blocks, then runs exact attention over those selected blocks instead of the full context.
How much faster is MiniMax Sparse Attention at 1M context?
The paper reports 28.4x lower per-token attention FLOPs at 1M context. With its H800 kernel, it reports 14.2x prefill speedup and 7.6x decoding speedup versus dense GQA.
Does MiniMax Sparse Attention lose long-context quality?
Not much on the reported benchmarks. After long-context extension, MSA-CPT is 0.60 points below full attention on HELMET-128K and 0.12 points above full attention on RULER-128K, though individual subsets move in both directions.
Why is the MSA Index Branch important?
The Index Branch is the router that makes sparsity selective rather than fixed. It scores KV blocks per query group, selects the top blocks, and lets the Main Branch run ordinary attention on a much smaller context.
One line: MSA is interesting because it turns million-token attention into a block-selection and kernel problem, not because it abolishes attention. Read the original paper on arXiv.