Multimodal Models · Text-to-Image · Diffusion Models
Representation Forcing: Unified Multimodal Models Without a VAE
Representation Forcing drops the frozen VAE from unified multimodal models. RF-Pixel predicts visual representation tokens before pixels, hits 0.84 GenEval, and lifts MMMU by 4.3 points over its VAE variant.
Quick answer
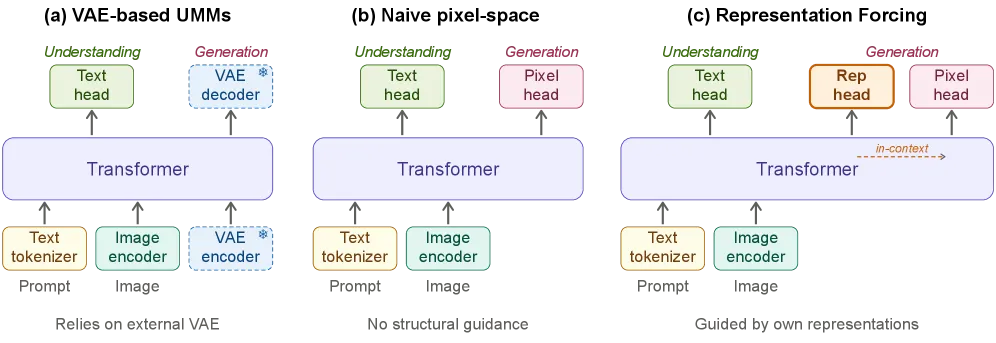
Representation Forcing (RF) builds a unified image-understanding-and-generation model that needs no frozen, separately pretrained VAE. Instead of decoding pixels from an external latent space, RF-Pixel autoregressively predicts visual representation tokens first, keeps them in context, and then runs pixel diffusion inside the same backbone. It reaches 0.84 overall on GenEval (0.88 with an LLM prompt rewriter) — matching VAE-based unified models on generation — while scoring 54.2 on MMMU for understanding, 4.3 points above the same architecture trained on VAE latents.
The VAE bottleneck this removes
Most unified multimodal models bolt generation onto an understanding backbone by reusing a frozen VAE: text-to-image diffusion runs in a latent space that some other model learned for reconstruction, not for semantics. That latent space is a bottleneck. It was optimized to compress pixels, so it discards the high-level structure a perception model actually wants, and because it is frozen, the unified model cannot reshape it. The result is the recurring complaint about unified models — generation works, but the shared representation is worse for understanding than a dedicated encoder would be.
RF’s claim is that you do not need the external latent space at all. If the model can predict good visual representations as a native capability, those predictions can carry the semantic load that a VAE latent was standing in for, and pixels can be generated directly from them.
How RF-Pixel works
The architecture is a mixture-of-transformers: shared self-attention layers, but tokens are routed to three modality-specific feed-forward experts — one for understanding, one for representation prediction, one for pixel generation. Generation proceeds in two stages within one forward pass. The decoder first autoregressively emits visual representation tokens, then those tokens stay in the context window and condition a flow-matching (x-prediction) objective that produces pixels. Training mixes three losses: cross-entropy on text tokens, cross-entropy on representation tokens, and the flow-matching loss on pixels.
The conceptual move worth naming: “representation forcing” forces the model to commit to a semantic plan (the representation tokens) before it paints pixels, the same way teacher forcing commits a language model to the next token. Because those tokens are reused for understanding too, generation and perception share one representation that the model itself shaped, not one inherited from a reconstruction-trained VAE.
Key results
- GenEval overall 0.84, and 0.88 with an LLM rewriter — ahead of Show-o2 (0.76), Janus-Pro-7B (0.80), and BAGEL (0.82) as reported.
- MMMU understanding hits 54.2 for the Pixel+RF model, a 4.3-point gain over the VAE+RF variant at 49.6 — the cleanest evidence that dropping the VAE helps perception, not just generation.
- DPG-Bench overall 84.15, trailing dedicated text-to-image systems Seedream 3.0 (88.27) and Qwen-Image (88.32), which is the honest gap: RF matches unified peers, not the best generation-only models.
- The paper also reports on HalluBench, MME, BLINK, RealWorldQA, AI2D, DocVQA, and ChartQA, positioning RF as a broad understanding model rather than a narrow generator.
Why it matters now
Unified multimodal models are the live race in 2026, and the frozen-VAE design is the part everyone copied without loving it. RF is the first serious argument that the external generative latent space is optional — that a single backbone can learn representations good enough to both generate from and understand with. If it holds up at larger scale, it simplifies the entire pipeline: no separate VAE to pretrain, host, and keep in sync, and one representation to improve instead of two latent spaces to reconcile.
Limits and open questions
The generation gap is real and unhidden: 84.15 on DPG-Bench versus ~88 for the best dedicated text-to-image models means RF buys architectural cleanliness, not state-of-the-art image quality. The headline understanding win is measured against the same architecture on VAE latents, which is the fair ablation but also a friendly baseline — it shows RF beats its own VAE variant, not that it beats the strongest understanding-only encoders. Predicting representation tokens before every image adds an autoregressive stage and likely raises inference cost versus latent-space diffusion, and the paper’s scale is modest next to frontier closed systems, so whether the no-VAE bet survives at production scale is still open.
FAQ
What is Representation Forcing in unified multimodal models?
Representation Forcing (RF) is a training technique where the model autoregressively predicts visual representation tokens before generating pixels, and reuses those tokens in context to drive pixel diffusion within one backbone — removing the frozen VAE that other unified models depend on.
How does RF-Pixel compare to Janus-Pro and BAGEL on GenEval?
RF-Pixel reports 0.84 overall on GenEval (0.88 with an LLM rewriter), ahead of Janus-Pro-7B at 0.80 and BAGEL at 0.82, while matching VAE-based unified models on generation overall.
Does removing the VAE actually help image understanding?
Yes, by the paper’s ablation: the Pixel+RF model scores 54.2 on MMMU versus 49.6 for the same architecture trained on VAE latents, a 4.3-point gain, indicating the model-native representation carries more useful semantics than a frozen reconstruction latent.
Is RF-Pixel state of the art for text-to-image generation?
No. On DPG-Bench it scores 84.15, behind dedicated text-to-image systems like Seedream 3.0 (88.27) and Qwen-Image (88.32). RF matches unified peers, not the best generation-only models.
One line: predict the representation, then the pixels — and you can throw away the VAE. Read the original paper on arXiv.