AI Agents · LLM Reasoning · Fine-Tuning & Adaptation · Reinforcement Learning
Self-Distilled Agentic RL: A Privileged Teacher Steering GRPO Per Token
SDAR adds a gated, token-level self-distillation signal from a skill-augmented teacher on top of GRPO, lifting multi-turn agents by up to +10.2 points on WebShop and +9.4 on ALFWorld for small Qwen models.
Quick answer
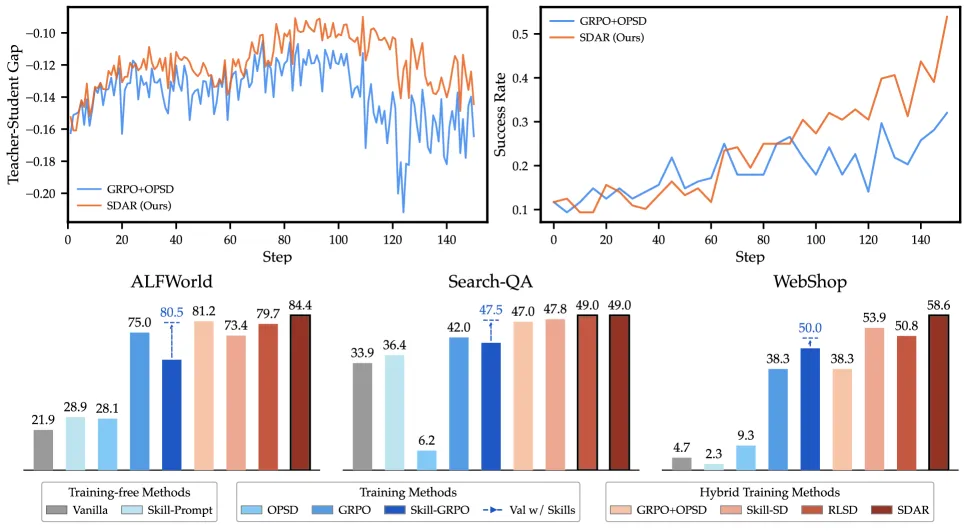
SDAR (Self-Distilled Agentic Reinforcement Learning) attaches a dense, token-level self-distillation signal to ordinary GRPO so multi-turn agents get gradient on every token, not just a sparse end-of-episode reward. A privileged “teacher” that sees retrieved skills guides the student policy, and a sigmoid gate decides per token how much to trust it. On Qwen2.5-3B-Instruct it lifts ALFWorld from 75.0% to 84.4% (+9.4), Search-QA from 36.4% to 43.4% (+7.0), and WebShop accuracy from 63.3% to 68.0%; the biggest single jump is +20.3 on WebShop for Qwen3-1.7B.
The sparse-reward problem in agentic RL
Training an LLM agent to do household tasks (ALFWorld), multi-hop search (Search-QA), or web shopping (WebShop) with GRPO runs into a brutal credit-assignment problem: the reward arrives only at the end of a long multi-turn trajectory, so the model gets one scalar to explain dozens of token-level decisions. Outcome-only RL is sample-hungry and unstable in exactly this regime. The obvious fix — distill from a stronger teacher — usually means a separate, more capable model, which is expensive and often unavailable.
How SDAR works
SDAR’s teacher is not a bigger model. It is the same policy given privileged context: relevant skills retrieved from past experience, which the student does not see at inference time. Because the teacher only differs by extra context, its per-token log-probabilities are a cheap, on-policy distillation target. The method, which the paper calls on-policy self-distillation (OPSD), is added as an auxiliary loss: L = L_GRPO + λ · L_SDAR, with RL kept as the primary objective and distillation as a gated helper rather than a replacement.
The key engineering move is the token-level gate. The authors found that naive self-distillation breaks in the multi-turn setting for two reasons: teacher-student drift compounds across turns, and — because skill retrieval is imperfect — more than 50% of tokens actually show a negative teacher-student log-prob gap, meaning the “teacher” is worse there. So a sigmoid gate over the gap Δₜ treats tokens asymmetrically: positive-gap tokens (teacher genuinely better) get stronger distillation, negative-gap tokens are softly attenuated. This is the difference between SDAR and just bolting KL-to-teacher onto GRPO.
Key results
All numbers are on success rate / accuracy, SDAR vs the GRPO baseline:
- Qwen2.5-3B-Instruct: ALFWorld 75.0% to 84.4% (+9.4), Search-QA 36.4% to 43.4% (+7.0), WebShop-Acc 63.3% to 68.0% (+4.7).
- Qwen2.5-7B-Instruct: ALFWorld 81.2% to 85.9% (+4.7), Search-QA 42.0% to 49.0% (+7.0), WebShop-Acc 72.6% to 82.8% (+10.2).
- Qwen3-1.7B-Instruct: ALFWorld 46.1% to 53.9% (+7.8), Search-QA 40.8% to 41.9% (+1.1), WebShop-Acc 38.3% to 58.6% (+20.3).
- Robust to retrieval quality: ALFWorld gains hold across retrieval tiers — UCB +5.6, keyword matching +4.7, even random retrieval +1.9 — so the gate, not perfect skills, is doing the work.
The honest read: gains are real and consistent but uneven. Search-QA improves the least (+1.1 on Qwen3-1.7B), and the headline +20.3 comes from a small model on one task where the baseline was weak (38.3%). The method helps most where there is the most room.
Why the gate is the real contribution
The interesting claim here is not “distillation helps RL” — that is old. It is that in multi-turn agentic RL, an ungated teacher signal hurts because the teacher is unreliable on a majority of tokens. SDAR’s evidence for the negative-gap statistic (over half of tokens) is what justifies asymmetric gating, and the random-retrieval ablation (+1.9 even when skills are noise) suggests the gate is salvaging a weak signal rather than relying on a strong one. That reframes self-distillation from “copy a better model” to “selectively trust a same-sized model that occasionally knows more.”
Limits and open questions
The teacher needs privileged skills at training time; the paper argues the policy internalizes this so there is no inference-time dependency, but that internalization is asserted more than stressed-tested. Hyperparameters matter: the reported sweet spot (β=5.0, λ=0.01) needs tuning, and gate activation stays under 50% in early training, so some distillation signal is left on the table. Everything is evaluated on Qwen2.5/Qwen3 models up to 7B and three benchmarks — no large-scale model, no coding or tool-use agents, no comparison against a genuinely stronger external teacher. Whether the same-model teacher trick beats simply distilling from a bigger model when one is available is left open.
FAQ
What is Self-Distilled Agentic Reinforcement Learning (SDAR)?
SDAR is a training method that adds an on-policy self-distillation loss to GRPO for multi-turn LLM agents. A teacher — the same policy given retrieved skills as privileged context — provides dense token-level guidance, gated per token by the teacher-student log-prob gap.
How much does SDAR improve over GRPO?
On Qwen2.5-3B-Instruct, SDAR adds +9.4 on ALFWorld, +7.0 on Search-QA, and +4.7 on WebShop accuracy. On Qwen2.5-7B it adds +10.2 on WebShop, and the largest single gain is +20.3 on WebShop for Qwen3-1.7B.
Why does SDAR use a token-level gate?
Because in multi-turn settings over 50% of tokens show a negative teacher-student gap — the teacher is actually worse there due to imperfect skill retrieval. The sigmoid gate amplifies distillation only where the teacher is genuinely better and attenuates it elsewhere.
Does SDAR need a bigger teacher model?
No. The teacher is the same model given privileged retrieved skills, making the distillation target cheap and on-policy. Gains even hold with random retrieval (+1.9 on ALFWorld), indicating the gating, not a stronger teacher, drives the improvement.
One line: keep GRPO in charge, add a same-sized teacher’s token-level advice, and gate it so you only copy the teacher where it’s actually right. Read the original paper on arXiv.