ACE-Ego-0:把人类第一视角视频和机器人数据统一进 VLA 预训练
ACE-Ego-0 用 6000 多小时数据做 VLA 预训练,把机器人轨迹和转成伪动作的人类第一视角视频混在一起。六个真机双臂任务平均 78.3%,高于 pi-0.5 的 71.7%。
快速答案
ACE-Ego-0 是一个视觉-语言-动作(VLA)模型,在 6013 小时的混合数据池上预训练:4534 小时机器人演示,加上 1479 小时人类第一视角视频转成的机器人形态伪动作。在六个真机双臂任务(ARX 平台)上平均成功率 78.3%,高于 pi-0.5 的 71.7%,GR00T-N1.7 只有 35.6%。在 RoboCasa GR1 TableTop 仿真基准上拿到 72.8%。头条不是人类视频管线本身:数据消融里,加入人类视频把 RoboCasa 从 68.3%(纯机器人)抬到 72.8%,涨 4.5 分;而真正最关键的单一组件是那套可靠性加权损失,它负责不让带噪的人类信号污染训练,去掉它会掉 3.6 分。
它要解决的数据规模问题
采集机器人轨迹又慢又贵,VLA 预训练长期缺具身数据。人类第一视角视频又多又便宜,但人手和机器人夹爪处在不同动作空间、不同本体,而且人类视频根本没有记录动作。ACE-Ego-0 赌的是:可以从人类视频里恢复出能用的伪动作,把它和机器人数据倒进同一个预训练池,前提是告诉模型每个来源有多可信。
有意思的是它对可靠性的诚实。重建出来的人手姿态,对手往哪移很准,对手怎么转、夹爪开没开就很弱。所以模型被训成:位置上信人类视频,旋转和夹爪状态上几乎无视它。
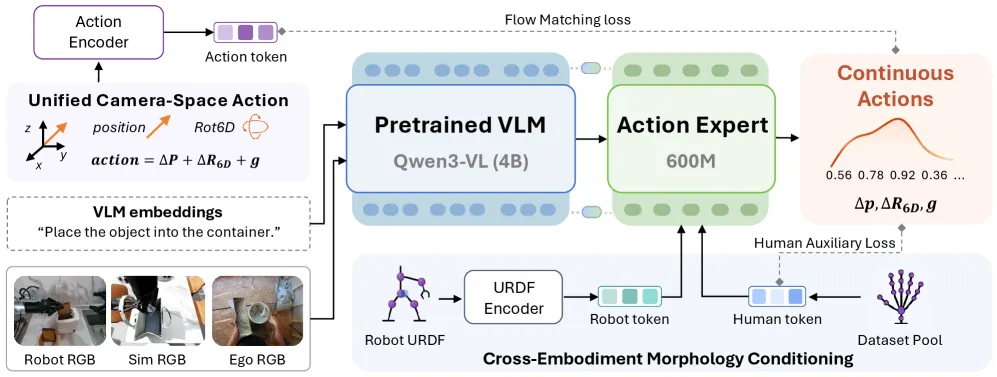
人类和机器人数据怎么统一
三层对齐把两种来源压进一个标准格式:
- 空间: 机器人末端执行器位姿和重建出的人类手腕轨迹,都表达在头部相机坐标系里。对人来说手腕就是末端执行器,手的朝向由手掌平面推出,拇指到掌心的距离当夹爪代理,归一化到机器人的行程范围。输出是 22 维双臂向量(每臂 11 维:3 维位置、6 维朝向、夹爪、活动标志)。
- 结构: 每种本体用一个形态 token 描述。机器人用 URDF 图编码(关节、限位、链条),人类数据集用学出来的代理嵌入。这些 token 只去条件化动作专家,从不进入共享的视觉-语言主干,所以形态信息不会混进感知特征。
- 时间: 动作块按物理时长切(2 秒),不按步数切,这样 30 Hz 的人类片段和 10 Hz 的机器人日志描述的是同一段真实时间。H_d = round(f_d x T*)。
视频转动作是个五级漏斗:筛选第一视角片段,过滤到操作片段,用 SAM3 跟踪加 HaMeR 姿态估计重建 3D 手,把 MANO 姿态参数化成相机坐标系伪动作,再丢掉含 NaN、没动作或有跳变伪影的片段。
为什么可靠性加权扛起了结果
伪动作是带噪的,要是当成传感器日志去硬训,会把锚在机器人上的目标带坏。ACE-Ego-0 用一个逐通道、逐步的权重 W。通道先验很直接:位置通道权重 1.0,旋转和夹爪 0.001。也就是说人类视频教模型往哪移,在朝向和抓取上基本被静音。在这之上,步权重再压低那些跳变或加加速度大的帧。人类辅助损失是用 W 缩放的 Huber 损失,以 lambda = 0.1 加到机器人主流匹配损失上。
这正是消融里回报最高的组件。去掉这套可靠性加权的人类辅助损失,RoboCasa 从 72.8% 掉到 69.2%,跌 3.6 分,比去掉形态 token(1.9)或时间对齐分块(1.1)都大。便宜的人类视频确实有用,但前提是训练把它当成弱的位置先验,而非真值。
关键结果
- 真机平均(6 个 ARX 双臂任务,每个任务 30 次试验): ACE-Ego-0 78.3%,pi-0.5 71.7%(+6.6),GR00T-N1.7 35.6%(+42.7)。按图 5(a),ACE-Ego-0 在六个任务上全部领先或打平。GR00T 在动态任务上差距巨大:扫方块 73.3% 对 6.7%,舀咖啡 83.3% 对 36.7%,装鞋 60.0% 对 10.0%。
- RoboCasa GR1 TableTop(24 任务,各 50 次): 平均 72.8%,高于 DIAL(70.2%)、JoyAI-RA(63.2%)、GR00T-N1.6(47.6%)。
- RoboTwin 2.0(50 任务): 简单 91.12% / 困难 90.62%,微胜 JoyAI-RA(90.48 / 89.28),明显高于 pi-0.5(82.74 / 76.76)。
- 数据消融: 机器人+人类 72.8%,纯机器人 68.3%(人类视频 +4.5),纯 Qwen 无具身预训练 65.4%。
- 组件消融: 可靠性加权人类损失值 3.6 分,是单组件里最大的。
- 数据稀缺微调: 扫方块任务只给 34 条机器人演示(工作区 0.062 平方米)时,加 419 条覆盖 0.296 平方米(广 4.8 倍)的人类片段,成功率从 10% 升到 40%。人类视频补上了机器人遥操作没碰到的工作区域。
怎么读这些对比
真机上比 GR00T-N1.7 高 42.7 分是最响的数字,也最容易读偏。GR00T 是通用模型,没针对这套 ARX 双臂配置专门调过,而单一硬件平台、六个任务本就是很窄的切片。更公平的信号是比 pi-0.5 高的 6.6 分,这是一个同级强基线;还有固定架构下人类视频带来 +4.5 的受控数据消融。把 ACE-Ego-0 当成”过滤后的人类视频是桌面操作的有用位置先验”的证据,别当成通用 VLA 前沿的证明。“每个任务都领先”的说法也要再看一眼:取茶任务上 ACE-Ego-0 只是和 pi-0.5 打平(各 86.7%,这里人类视频没带来增益),而在扫方块和叠碗上它比 pi-0.5 只多一次试验(73.3% 对 70.0%、80.0% 对 76.7%),按 30 次的分母完全落在噪声里。对 pi-0.5 的胜在平均上是真的,但逐任务看很薄。
局限与存疑
评测只覆盖桌面操作;移动操作、全身人形、可变形物体都没测。预训练池里没有灵巧手、力、力矩数据,而这恰恰是接触密集任务需要的。伪动作管线自己承认的弱点就是旋转和精细手指动作,模型靠把旋转权重设成 0.001 把这点遮过去,所以人类视频对朝向学习几乎没贡献。6000 小时预训练没报 token、墙钟或算力开销,所以这套配方在小预算下是否可行未知。4 倍那条数据稀缺结果是单任务、分母只有 10 次,10% 到 40% 即 1/10 到 4/10,鼓舞人但统计上很薄。
常见问题
ACE-Ego-0 里人类视频到底加了多少?
在受控的 RoboCasa 消融里,加入人类第一视角视频把成功率从 68.3%(纯机器人)抬到 72.8%,同一架构下涨 4.5 分。在刻意制造的数据稀缺微调里(扫方块,34 条机器人演示),加 419 条人类片段把成功率从 10% 提到 40%。收益是真的,但在机器人数据稀疏时最大,因为人类视频覆盖了机器人演示漏掉的工作区域。
ACE-Ego-0 在真机上能赢 pi-0.5 和 GR00T 吗?
六个真机双臂 ARX 任务上,ACE-Ego-0 平均 78.3%,pi-0.5 71.7%(+6.6),GR00T-N1.7 35.6%(+42.7),按图 5(a) 它在六个任务上全部领先或打平。不过胜面很薄:取茶任务上它只是和 pi-0.5 打平(各 86.7%),而扫方块(73.3% 对 70.0%)和叠碗(80.0% 对 76.7%)上的领先只是 30 次里多一次。和 GR00T 差距大,部分是因为 GR00T 是通用模型,没为这个具体平台调过。这类模型的背景可参见 VLA 主题。
ACE-Ego-0 为什么要压低人类视频里的旋转?
重建的人手姿态在手的位置上可靠,在朝向和夹爪状态上很弱。ACE-Ego-0 把通道权重设成位置 1.0、旋转和夹爪 0.001,所以人类视频教模型往哪移,对怎么转、怎么抓几乎不贡献。去掉这套可靠性加权,RoboCasa 掉 3.6 分,是单项消融里最大的跌幅。
ACE-Ego-0 用什么数据训练?
一个 6013 小时的混合池:4534 多小时机器人演示(AgiBot Alpha/Beta 1937 小时、Galaxea R1Lite、RoboCasa、Galbot 自采 1800 多小时),加 1479 小时人类第一视角视频(EgoDex 776.8 小时、Xperience-10M 435.7 小时、Ego4D、EgoExo4D、EPIC-KITCHENS-100、HOI4D)。人类片段在混入前先转成相机坐标系伪动作。
这里的人类视频思路跟以前的 VLA 工作比新在哪?
用人类视频做操作并不新,新在统一配方:一个共享的 22 维标准动作空间、不碰主干只条件化动作专家的形态 token、时间对齐分块、逐通道可靠性加权。它建立在 pi-0 这类流匹配动作专家和更广的 机器人学 VLA 预训练路线上,而不是提出新主干。
一句话:ACE-Ego-0 表明过滤后的人类第一视角视频是 VLA 预训练里可用的位置先验(RoboCasa +4.5,真机平均 78.3%),但收益取决于把带噪的旋转和夹爪信号静音的可靠性加权。阅读 arXiv 原文。