CPPO:打破 LLM 强化学习里的均匀 token 信任域
CPPO 把 PPO 一刀切的裁剪阈值换成早 token 更严的裁剪加一条前缀漂移预算,把 Qwen3-30B-A3B-Base 的 AIME 从 49.23(DPPO)抬到 54.79。
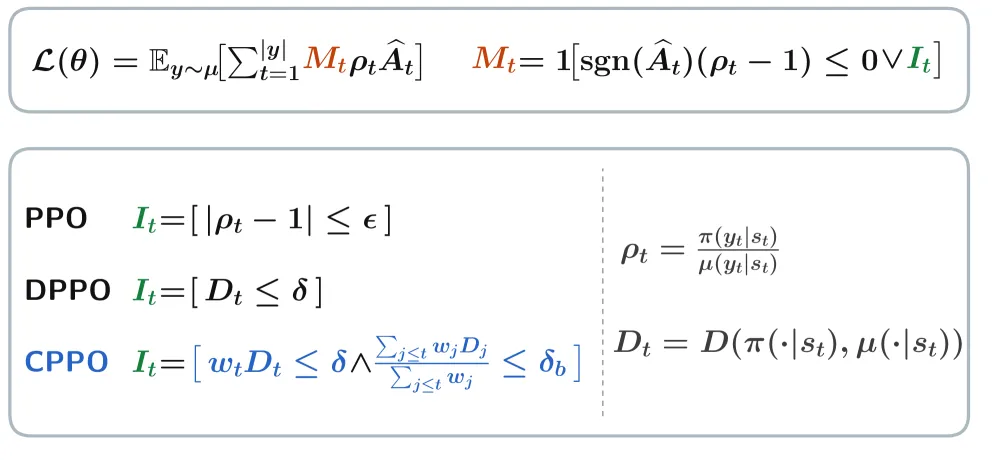
快速答案
CPPO(Cumulative Prefix-divergence Policy Optimization,累积前缀散度策略优化)是一条用于 LLM 强化学习的 token 级掩码规则,核心是不再把每个 token 的信任域当成一样大。它对靠前的 token 用更严的裁剪阈值,同时记一条”前缀已经漂了多远”的运行预算,预算花光就掩掉这次更新。在 AIME24/25/26 Avg@16 上,CPPO 在 Qwen3-30B-A3B-Base 拿到 54.79,DPPO 是 49.23(高 5.56),GRPO 38.19(高 16.6),在测试的四个模型配置上全部领先。提升是训练稳定性的结果,不是换了新目标:数据一样、奖励一样,只改裁剪规则。
为什么均匀裁剪是错的默认值
面向推理的 PPO 式强化学习(GRPO、DAPO 这类)用单一裁剪阈值把新策略拉回旧策略附近,而且对一条序列里的每个 token 一视同仁。这忽略了自回归生成真正出错的方式。思维链里靠前的一个错 token 会重新决定后面所有内容的条件分布,所以同样大小的逐 token 偏移,在第 5 个位置造成的破坏比第 500 个位置大得多。均匀阈值还没有记忆:它孤立地检查每个 token,从不问在此之前前缀已经漂了多远。CPPO 把这两个盲点叫自回归不对称和累积前缀漂移,图 2 的实测支持这个诊断:实测策略偏移在靠前位置确实更大、尾部更重,而那恰恰是均匀阈值相对最宽松的地方。
两个旋钮怎么工作
第一个旋钮是线性位置权重。token t 拿到权重 w_t,从第一个 token 的 1.0 线性降到末位的 w_min(默认 0.8),于是有效阈值 δ/w_t 在前面最紧、向序列尾部放松。第二个旋钮是累积前缀预算。规则维护一个加权的前缀散度运行和 S_t 和累积权重 W_t,token t 处的有效上限变成 min{δ, δ + δ_b·W_{t-1} − S_{t-1}}。说白了:每个 token 起步有正常额度 δ,但如果前面的 token 已经超支了前缀预算 δ_b,额度就缩水,一旦某 token 会把前缀推过预算允许的范围,它就被掩掉。所以一个 token 可能因为自己偏太多被杀,也可能因为它接在一个已经漂太远的前缀后面被杀。论文把这套解释成让每次更新对齐一个有限步长的策略改进上界,而不是拍脑袋的裁剪。
这是 Flow-DPPO 同一个作者群做的工作,那篇把 PPO 信任域搬进 flow-matching 生成;CPPO 是语言模型 RL 这一支,质疑的是 token 均匀这个假设。
关键结果
- Qwen3-30B-A3B-Base,AIME Avg@16: CPPO 54.79,DPPO 49.23(高 5.56),GRPO 38.19,MinPRO 48.12。这是头条数字,也是最大的领先幅度。
- 更小规模: CPPO 在 Qwen3-1.7B 上 31.88(最强基线 CISPO 28.82),1.7B-Base 12.78,8B-Base 31.11。四列全胜,对次优方法的领先分别是 3.06、0.91、1.39、5.56 分。
- 基线不弱: 对照里有 DPPO、MinPRO、CISPO、TRM-Max、TRM-Avg,比的是当前各种信任域变体,不是拿原始 PPO 当稻草人。
- 崩溃下更稳: CISPO 在 Qwen3-30B-A3B-Base 上直接崩了,CPPO 训得很干净,图 4 的曲线显示 CPPO 全程保持领先,而不是冲高再回落。
- 两个旋钮都在出力(图 5): 去掉前缀预算(只留位置权重)的 CPPO,和去掉位置权重(只留前缀预算)的 CPPO,各自仍胜过 DPPO;完整方法最好。哪个组件都不是摆设。
- 顺序本身有用,不只是数值(图 5): 把位置权重在 token 间打乱、数值不变,效果不如有序版本,这是最干净的证据,说明起作用的是对早 token 的侧重,而非仅仅把平均裁剪收紧。
局限与存疑
整个评测都是 Qwen3 上 AIME 系列的数学推理。没有代码、智能体或开放式生成的结果,所以”跨规模提升推理”是一个关于可验证奖励下竞赛数学的说法,不是通用 RLVR 的胜利。30B 那次是唯一的 MoE 结果,用了不同的 δ(0.2,稠密模型是 0.15),Base 模型还用了自适应的 δ_b,所以最大、最好引用的那个幅度,恰恰落在最不能直接横比的配置上。CPPO 还在共享阈值之外多加了两个超参(δ_b、w_min);论文说相邻取值都还能打,但换一个新模型家族时的调参成本是真实的,这里没测。
要不要上手
如果你已经在长链推理上跑 GRPO/DAPO/DPPO,又遇到训练不稳或天花板压不动,CPPO 试起来很便宜:它是同一个 loss 里换掉裁剪规则,不加奖励模型,不加数据。“对早 token 裁得更狠才是关键”这个消融结论,即便你不上整套机制,也是个有用的先验。如果你的任务是短步长、序列本来就短,自回归不对称这个前提就弱,收益大概率缩水,因为没那么长的前缀让早期错误去逐级放大。在等到一个非数学、更长步长的复现之前,别把 30B 那个幅度当成通用结论。
常见问题
CPPO 在 LLM 强化学习里是什么?
CPPO(累积前缀散度策略优化)是一条用于 PPO 式 LLM 强化学习的 token 级掩码规则。它用线性位置权重对早 token 裁得比晚 token 更严,并跟踪一条累积前缀散度预算,一旦条件前缀已经漂太远就掩掉该 token。在 Qwen3-30B-A3B-Base 上它达到 AIME Avg@16 54.79,DPPO 是 49.23。
为什么均匀的 token 级信任域在自回归 RL 里会失效?
因为靠前的一个错 token 会重新决定后面整条序列的条件分布,同样大小的逐 token 偏移在前面比在后面破坏更大,而均匀阈值对前缀已经漂了多远没有记忆。CPPO 的图 2 显示实测策略偏移在靠前位置更大、尾部更重,而那正是均匀裁剪相对最宽松的地方。
CPPO 里,位置权重和累积前缀预算哪个更重要?
两者都有贡献,谁都不多余。图 5 显示去掉任一个,仍能胜过 DPPO 基线,但两者都在的完整方法最好。最干净的信号是打乱测试:把位置权重数值保留但随机分配会变差,所以起作用的是早 token 的次序本身,不只是把平均裁剪收紧。
CPPO 在 AIME 上比 DPPO 和 GRPO 高多少?
在 Qwen3-30B-A3B-Base 的 AIME24/25/26 Avg@16 上,CPPO 54.79,DPPO 49.23(高 5.56),GRPO 38.19(高 16.6)。它在 Qwen3-1.7B(31.88)、1.7B-Base(12.78)、8B-Base(31.11)上也都赢,不过小规模的领先可能不到 1.5 分。
CPPO 是通用 RLVR 方法,还是目前只有数学?
目前证据上只有数学。所有报的数字都是 Qwen3 模型在可验证奖励下的 AIME 系列竞赛数学。机制本身与任务无关,但没有代码、智能体或开放式结果,所以通用 RLVR 的说法尚未验证。可以对照 N-GRPO 和 APPO,它们通常会在多个任务家族上验证后再被采用。
一句话:CPPO 表明你在序列的哪个位置收紧信任域,和收紧多少同样重要:对早 token 裁得更狠加一条前缀漂移预算,把 49.23 的 DPPO 跑成了 Qwen3-30B-A3B 上的 54.79。阅读 arXiv 原文。