DRIFT:精准定位深度研究 Agent 错在哪一步
TELBench 让模型在十余步的研究轨迹里找出坏掉的那一段。DRIFT 用主张对证据的审计法,把 span 级宏 F1 推到 54.91%,比直接喂原始轨迹最高高出 30 个百分点。
快速答案
深度研究 Agent 失败时,最终答案的对错只能告诉你”它错了”,却不告诉你”错在哪一步”。DRIFT 是一套主张审计流水线:它读完 Agent 的完整轨迹(搜索、工具调用、证据、中间推理),然后指出究竟是哪一段(span)里某个无依据或被反驳的主张污染了最终答案。在本文新提出的 TELBench(1000 条轨迹,每条平均约 11.95 个语义 span)上,DRIFT 搭配 Claude-Sonnet-4.6 取得 54.91% 的宏 F1,比把原始轨迹直接丢给同一模型让它找错,最高高出 30 个百分点。
但要说实话:即便最好的成绩也不到 55% F1,而”第一个错误”的定位准确率最高只有 24.10%。这是一个刚被定义、远未解决的硬问题。它的真正价值在于这套基准和错误分解框架,而不是一个成品级的错误检测器。
问题:结果分数掩盖了出错点
深度研究 Agent 的轨迹很长。一道 GAIA 或 BrowseComp 任务,往往要经过十几轮”搜索—阅读—推理—行动”才给出答案。而标准评测只看最后一个 token:对或错。这对开发者毫无可操作性。是第一次检索就写错了?是 Agent 编造了一个日期?是引用了真实页面却读错了数字?还是早期一个错误一路滚雪球?
本文把调试重新定义为 span 级错误定位:给定一条切成语义 span 的轨迹,找出哪些 span 含有”有害错误”。“有害”是关键限定词。探索性的死胡同、失败但被纠正的查询,都是 Agent 的正常行为,不应被标记。目标只锁定那一段:坏主张在此变成支撑最终错误答案的承重墙。
走进 TELBench
作者跨 2 个 Agent 框架(MiroFlow、OAgent)、3 个骨干模型(GPT-5、Gemini-2.5-Pro、Claude-Sonnet-4.5)和 3 个基准(GAIA-val、XBench、BrowseComp-test,各下采样到 200 任务,合计约 465 任务)收集了 2790 条原始轨迹。原始日志被规整成语义 span,再由专家在 LLM 辅助下审核候选有害 span。最终得到 TELBench:1000 条经验证的实例(600 条简单 / 400 条困难)。
错误体系是即便不用 DRIFT 也值得保留的部分:6 大类、18 种主要错误:约束处理、检索召回、证据落地、实体映射、信息处理、流程控制。这是一套可直接复用的 Agent 失败分析词表。机理分析还显示,错误并非均匀分布在轨迹各处,而是聚集在特定操作阶段。这本身就是给 Agent 监控系统的一个有用先验。
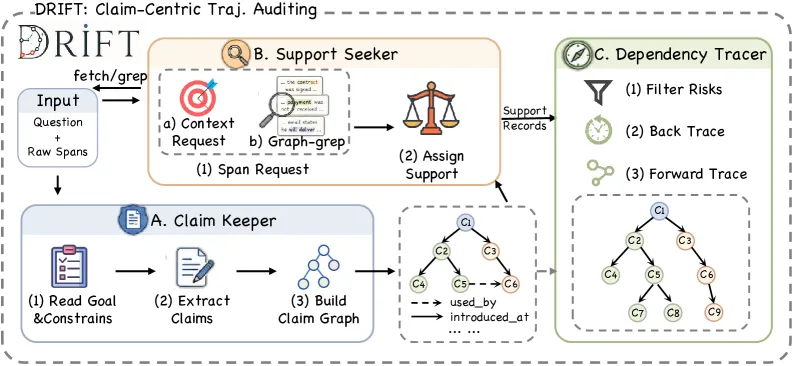
DRIFT 怎么运作
DRIFT 不会一句”哪里有 bug?”就甩给模型,而是把审计拆成三步:
- Claim Keeper(主张登记):给 Agent 提出的每条主张建账,记下它何时出现、依赖什么、在哪被复用、属于什么类型、当前状态。
- Support Seeker(支撑核验):对每条”有后果的”主张,对照轨迹证据贴上支撑标签,分为直接支撑、弱支撑、缺失、还是冲突。
- Dependency Tracer(依赖追踪):追踪哪些有风险的主张真正变成了通往最终答案的承诺,从而锁定有害 span。
核心洞见在于:一个 span 值得被标记,前提是它里头那条弱依据或被反驳的主张真的传导进了答案。审计的是”是否有证据落地”,而非”听起来是否合理”。这正是它跟朴素提示拉开差距的地方。
关键结果
- 整体宏 F1 54.91%,最佳配置(Claude-Sonnet-4.6 + DRIFT)。简单子集 60.00%,困难子集 47.28%。
- 相比裸基线(同一模型直接读原始轨迹),宏 F1 最高提升 30 个百分点。
- 第一个错误的定位准确率峰值仅 24.10%。锁定”最早出错的那一段”,比标出”任意一段有害 span”难得多。
- 受测模型涵盖 Qwen 系列、GPT-5.4、DeepSeek-V3.2、Claude-Sonnet-4.6、Gemini-2.5-Pro;Agent 类基线包括直接读轨迹的 Codex 与 Claude Code。
- 消融实验确认 DRIFT 三个模块(主张账本、支撑核验、依赖追踪)各有贡献;论文也指出多阶段审计比一次性提示更贵,存在准确率与成本的权衡。
局限与存疑
天花板偏低。不到 55% 的 F1、约 24% 的首错准确率,意味着 DRIFT 现在是研究基线,而非能直接接入生产 Agent 的 CI 卡口。你还不能让它默默地把关上线。TELBench 也只覆盖少数几个框架和模型在三个问答类基准上的轨迹;这套 18 类错误体系能否迁移到编程 Agent、长程工具使用或多 Agent 系统,尚未验证。专家加 LLM 的标注流程虽然谨慎,但”什么算有害”的判断已被固化进数据;多阶段流水线的 token 成本也不容忽视。如果你只做英文单 Agent 问答管线,这套错误词表的价值可能高于检测器本身。
常见问题
TELBench 和 DRIFT 是什么关系?
TELBench 是基准:1000 条标注好有害错误 span 的深度研究 Agent 轨迹,来自 MiroFlow、OAgent 在 GAIA、XBench、BrowseComp 上的运行。DRIFT 是作者提出的解法:一套三阶段主张审计流水线(主张登记、支撑核验、依赖追踪),得分比直接喂原始轨迹给模型最高高出 30 个百分点。
DRIFT 找 Agent 错误到底准不准?
在 TELBench 上,DRIFT 搭配 Claude-Sonnet-4.6 取得 54.91% 的 span 级宏 F1,定位首个错误的准确率为 24.10%。相对基线表现亮眼,但绝对水平离”可靠”还很远。把它当调试辅助和研究目标,而非已验证的上线卡口。
为什么深度研究 Agent 的 span 级错误定位这么难?
一条轨迹平均约 12 个语义 span,而 Agent 本来就会走死胡同、发失败查询,这些都不是错误。任务是找出那唯一一段:某个无依据或矛盾的主张在此成为支撑错误答案的承重墙。把”有害错误”和”健康探索”区分开,恰恰是一次性提示最容易翻车的地方。