Echo-Memory:哪种记忆能让世界模型记住一个房间
镜头转回旧场景时,块状状态空间循环拿到 69.0 的开放域一致性分,无记忆基线只有 12.25;激进压缩与空间摘要几乎全军覆没。
快速答案
Echo-Memory 只问一个很窄的问题,并把它答得很干净:一个基于视频的动作世界模型,让镜头离开某个场景、过一会儿再转回来时,哪种记忆机制能让房间保持不变?京东探索研究院(Joy Future Academy)的团队把骨干网络、动作编码、数据和训练预算全部冻住,只替换记忆模块,于是分数差异来自记忆设计本身,而不是别的混杂因素。
核心结论:块状状态空间循环(block-wise state-space recurrence) 在开放域回访一致性上拿到 69.0(用 Qwen3-VL 当裁判、归一到 0–100),而完全无记忆的图生视频基线只有 12.25。原始上下文也很能打(存 20 帧时 58.63),但代价随帧数线性增长。真正出人意料的是失败的一侧:所谓「空间记忆」摘要居然比无记忆还差(6.00),激进的混合压缩更是塌到 9.00。
如果你在做交互式视频世界,最实用的一句话是:怎么把记忆「读回来」,比你存了多少更重要;那些看起来很聪明的压缩 / 空间设计,反而输给了朴实的基线。
动作世界模型要记住什么
动作世界模型是分段生成视频的:给它一个起始帧、一段文本提示、一串相机动作(这里是 12 维相对相机旋转+平移),它就往前推演。最难的情形是回访:镜头先转开、四处探索,再转回起点。没有记忆的模型会兴高采烈地脑补出一个全新房间。所谓「记忆」的全部意义,就是让返回那一帧和之前的样子对得上。
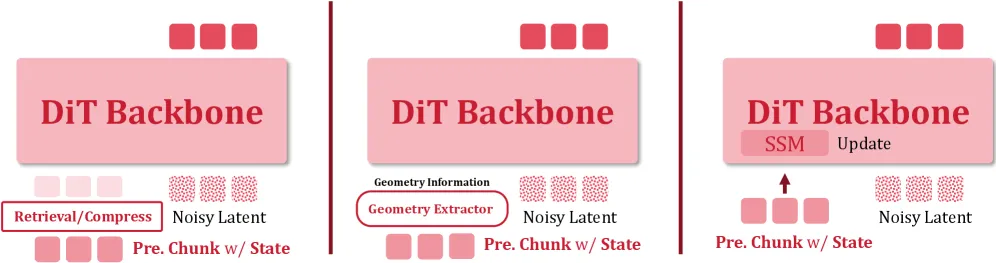
Echo-Memory 的贡献不是某个新模块,而是在统一平台上对四类记忆做受控对比:
- 原始上下文:直接回喂最近 K 帧(测了 K=1、5、20)。
- 压缩记忆:用权重压缩、长度缩减(r=2、r=4)或混合方式缩小存储。
- 空间记忆:学一个空间摘要,配不同读出路径(不注入、文本 KV 拼接、专用交叉注意力)。
- 状态空间循环:往前携带一个循环状态,分遗留混合版和块状版两种。
骨干是带逐帧 VAE 上下文表示的视频 Diffusion-Transformer;训练为 8 张 A100-80G、55k 步、81 帧、352×640 的片段。正是这个固定预算,让对比变得公平。
怎么判断「它真的记住了」
评测才是大多数论文略过、而 Echo-Memory 赢得信任的地方。它把两种情形分开:
- 重放(Replay):沿真值轨迹精确重跑,用 PSNR / SSIM / LPIPS 逐帧比对。这能抓像素漂移,但会奖励「照抄」的模型。
- 开放域返回:让镜头沿自由轨迹离开再回来,此时根本没有真值帧可比。于是用一个 VLM 裁判按
0.45·外观 + 0.25·存在 + 0.20·视角 + 0.10·场景的加权打语义一致性分,归一到 0–100。
这个开放域 VLM 分数才是真正能区分各机制的指标,作者也对它做了压力测试:换裁判模型后,各分数与 Qwen3-VL 基线的差距维持在 Δ=1.3–3.1 分,排序相关性 ρ≥0.93。所以这个排名不是某一个裁判的偏好。
关键结果
- 块状状态空间循环拿下开放域回访冠军:69.0 分,远高于无记忆图生视频基线的 12.25。
- 原始上下文是一个诚实的强基线:K=5 时 50.75,K=20 时 58.63。但代价随 K 增长,所以状态空间循环要赢的不只是质量,还有效率。
- 空间记忆竟不如无记忆:基线空间设计只有 6.00,低于朴素基线的 12.25。罪魁是它的读出路径:换成「不注入」升到 15.50,换成专用交叉注意力读出升到 17.12。瓶颈在读出,不在存储。
- 压缩很脆:权重压缩 22.38,长度缩减 r=4 达 43.25,但混合 r=4 塌到 9.00;压得越狠并不会优雅退化。
- 状态空间内部设计也很关键:遗留混合版 34.75,块状版 69.00,仅靠结构改动就接近翻倍。
- 在像素重放上,空间记忆的 PSNR 最好(13.60),语义返回分却最差(6.00),干净地说明了为什么不能只用 PSNR 评判回访一致性。
局限与存疑
这项研究是刻意做窄的,这既是它的长处,也是它的天花板。全部跑在 352×640、81 帧片段、固定 55k 步预算上。换成更高分辨率、更长时程或大得多的算力,排名未必成立,压缩方法到那时也许才配得上它的代价。开放域指标依赖 VLM 裁判;跨裁判一致性令人安心,但学习型裁判仍可能和生成器共享盲区。而且块状状态空间循环在这里夺冠,并不代表它摸到了上限:最高分也只有 69.0/100,回访一致性是被改善而非被解决。指望拿到一个即插即用记忆模块的人请注意:这是一项研究,不是产品发布,你得到的是清晰的排序和一套评测协议,而不是一个承诺「无限逼真世界」的调好的权重。
常见问题
Echo-Memory 推荐动作世界模型用哪种记忆机制?
块状状态空间循环是研究中最强的开放域返回机制,拿到 69.0 分,而无记忆图生视频基线只有 12.25。原始上下文(最高 58.63)是强但代价随帧数增长的替代方案;压缩与空间摘要设计大多表现不佳。
为什么 Echo-Memory 里的空间记忆还不如没有记忆?
因为瓶颈在读出路径,而不在存储表示。默认空间记忆读出只有 6.00,但换成「不注入」路径升到 15.50,换成专用交叉注意力读出升到 17.12,都高于模型自己的基线存储设计。
Echo-Memory 在没有真值帧的情况下怎么衡量回访一致性?
它用一个 VLM 裁判,按外观、存在、视角、场景的加权和打分并归一到 0–100。作者通过更换裁判模型来验证:各分数差距维持在 Δ=1.3–3.1 分,与 Qwen3-VL 参考的排序相关性 ρ≥0.93。