World Models · Video Generation · Agent Memory
Echo-Memory: Which Memory Lets a World Model Remember a Room?
When a camera revisits an old spot, block-wise state-space recurrence scored 69.0 open-domain VLM consistency vs 12.25 for the no-memory baseline; aggressive compression and spatial summaries mostly collapsed.
Quick answer
Echo-Memory asks one narrow question and answers it cleanly: when a video-based action world model drives its camera away from a scene and later returns, which memory mechanism keeps the room the same? The team from JD’s Joy Future Academy freezes everything (backbone, action encoding, data, training budget) and swaps only the memory module, so the score differences come from memory design, not confounders.
The headline: a block-wise state-space recurrence reached 69.0 on their open-domain revisit consistency score (a Qwen3-VL judge rescaled to 0–100), versus 12.25 for the image-to-video baseline with no memory. Raw context helps a lot too (58.63 at 20 stored frames), but it scales linearly in cost. The surprises are on the failure side: a “spatial memory” summary scored worse than no memory at all (6.00), and aggressive hybrid compression collapsed to 9.00.
If you build interactive video worlds, the practical takeaway is that how you read memory back matters more than how much you store, and the clever-looking compressed/spatial designs underperformed the boring baselines.
What an action world model has to remember
An action world model generates video in segments: you give it a start frame, a text prompt, and a sequence of camera actions (here a 12-dimensional relative camera rotation+translation), and it rolls forward. The hard case is revisit: the camera pans away, explores, then comes back to where it started. A model with no memory happily hallucinates a brand-new room. The whole point of “memory” is to make the return frame match what was there before.
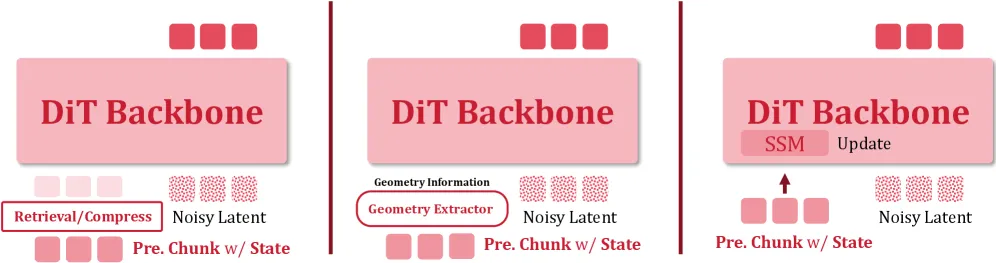
Echo-Memory’s contribution is not a single new module but a controlled comparison across four memory families on a shared rig:
- Raw context: just feed back the last K frames (tested at K=1, 5, 20).
- Compression-based memory: shrink stored context via weight-only summaries, length reduction (r=2, r=4), or hybrids.
- Spatial memory: a learned spatial summary with different read-out paths (inject-none, text-KV concat, dedicated cross-attention).
- State-space recurrence: carry a recurrent state forward, in a legacy hybrid form and a block-wise form.
The backbone is a video Diffusion-Transformer with a per-frame VAE context representation; training is 55k steps on 8 A100-80G GPUs over 81-frame, 352×640 segments. That fixed budget is what makes the comparison fair.
How they measure “did it remember?”
The evaluation is the part most papers skip, and it is where Echo-Memory earns trust. They separate two regimes:
- Replay: re-run the exact ground-truth trajectory and compare frames with PSNR / SSIM / LPIPS. This catches pixel drift but rewards models that just copy.
- Open-domain return: send the camera off on a free trajectory and back, where there is no ground-truth frame to diff against. Here a VLM judge scores semantic consistency as
0.45·appearance + 0.25·presence + 0.20·view + 0.10·scene, rescaled to 0–100.
That open-domain VLM score is the metric that actually distinguishes the mechanisms, and the authors stress-test it: swapping the judge model kept agreement within Δ=1.3–3.1 points of the Qwen3-VL baseline, with rank correlation ρ≥0.93. So the ranking is not an artifact of one judge.
Key results
- Block-wise state-space recurrence wins open-domain revisit: 69.0 VLM score, far above the 12.25 no-memory I2V baseline.
- Raw context is a strong, honest baseline: 50.75 at K=5, 58.63 at K=20. But cost grows with K, so it is the thing state-space recurrence has to beat on efficiency, not just quality.
- Spatial memory underperformed no memory: the baseline spatial design scored 6.00, below the 12.25 plain baseline. Its read-out path was the culprit: switching from the default to inject-none lifted it to 15.50 and a dedicated cross-attention read-out to 17.12. Read-out, not storage, was the bottleneck.
- Compression is fragile: weight-only got 22.38, length-reduction r=4 reached 43.25, but the hybrid r=4 collapsed to 9.00. More aggressive compression did not degrade gracefully.
- State-space design matters internally too: the legacy hybrid recurrence scored 34.75 versus 69.00 for block-wise, nearly 2x from a structural change alone.
- On pixel replay, spatial memory posted the best PSNR (13.60) while scoring worst on semantic return (6.00), a clean illustration of why you cannot judge revisit consistency by PSNR alone.
Limits and open questions
The study is deliberately narrow, and that is both its strength and its ceiling. Everything runs at 352×640 on 81-frame segments with a fixed 55k-step budget. The rankings may not survive at higher resolution, longer horizons, or much larger training compute, where compression methods might finally earn their cost. The open-domain metric leans on a VLM judge; the cross-judge agreement is reassuring but a learned judge can still share blind spots with the generator. And “block-wise state-space recurrence” winning here does not tell you the absolute ceiling. Even the best score is 69.0/100, so revisit consistency is improved, not solved. Anyone hoping for a drop-in memory module should note this is a study, not a product release; you get a clear ranking and an evaluation protocol, not a tuned checkpoint promising photorealistic infinite worlds.
FAQ
What memory mechanism does Echo-Memory recommend for action world models?
Block-wise state-space recurrence is the strongest open-domain return mechanism in the study, scoring 69.0 versus 12.25 for a no-memory image-to-video baseline. Raw context (up to 58.63) is the strong but cost-scaling alternative; compression and spatial-summary designs mostly underperformed.
Why did spatial memory in Echo-Memory do worse than no memory?
Because the read-out path, not the stored representation, was the bottleneck. The default spatial-memory read-out scored 6.00, but swapping to an inject-none path raised it to 15.50 and a dedicated cross-attention read-out to 17.12. Both sit above the model’s own baseline storage design.
How does Echo-Memory measure revisit consistency without a ground-truth frame?
It uses a VLM judge that scores appearance, presence, view, and scene agreement as a weighted sum rescaled to 0–100. The authors validated it by swapping judge models, finding agreement within Δ=1.3–3.1 points and rank correlation ρ≥0.93 against the Qwen3-VL reference.