WASH:平均 3 个大模型就能洗掉文本水印
把 3 个独立大模型的输出分布做平均,水印检测 z 分数从 5-304 直接掉到 2 以下,WASH 还给出了 O(1/根号N) 的误差证明。
快速答案
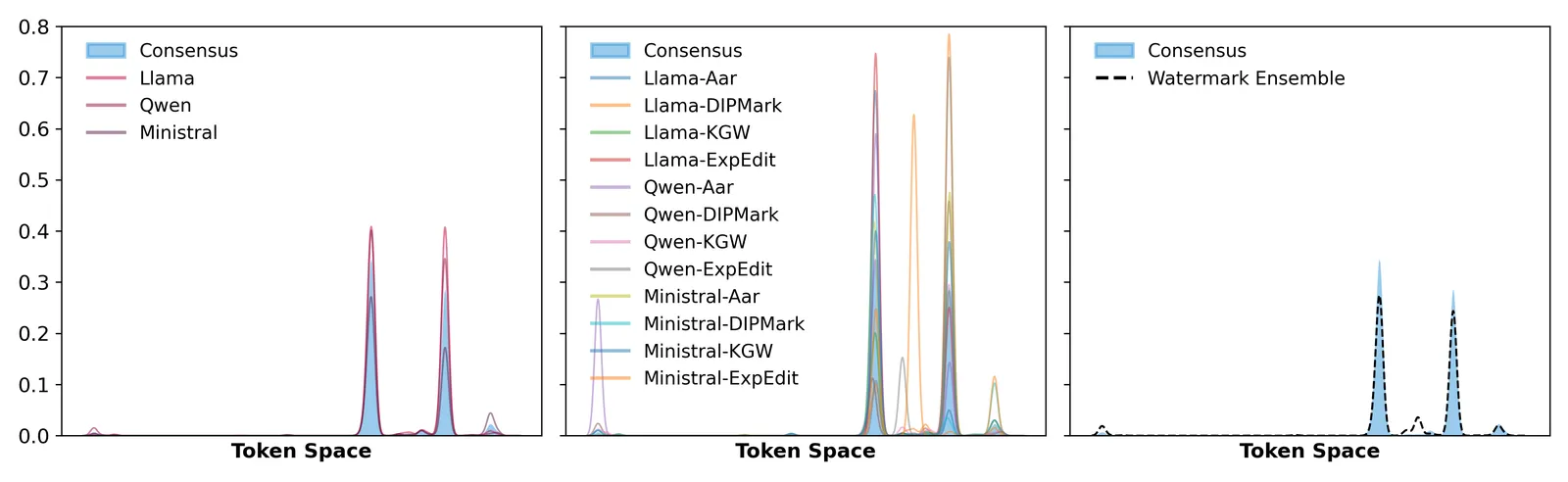
只要把 3 个独立大模型的下一词概率分布取平均,水印检测的 z 分数就会从 5 到 304 的区间被压到 2 以下,远低于常用的检测阈值 4。这就是 WASH(Watermark Attenuation via Statistical Hybridisation,基于统计混合的水印衰减)的核心结论。这套攻击不需要水印密钥、不需要重新训练任何模型,甚至不需要知道对方用的是哪种水印方案。
它的洞见简单到有点令人尴尬。水印的工作原理,是按密钥方向把模型输出分布从”诚实分布”上推开一点。而在竞争市场里,OpenAI、Google、某个开源模型,各自往自己独立的方向推。把这些独立的扰动一平均,它们就互相抵消了,就像独立噪声平均后趋近于零一样。WASH 把这个思路落到异构模型上,并在六种水印方案、三个 8B 级别大模型上验证了它确实成立。
如果你在做基于水印的来源溯源或”这段文字是不是 AI 写的”检测,这篇论文就是一个你绕不开的威胁模型。如果你只部署单一模型,今天这套攻击对你不适用。但多模型路由的趋势,正在让这份安全感越来越薄。
线性集成为什么能抵消水印
分布式水印会在干净的共识分布 p* 上叠加一个扰动 p_i,检测器随后去找这个特定扰动留下的统计指纹。WASH 的主张是:如果你查询 N 个扰动方向相互统计独立的提供方,那么它们分布的简单平均会收敛回 p*。
论文证明了这一点:集成平均能在二阶误差项范围内恢复共识分布,收敛速率为 O(1/根号N)。说人话就是:检测器赖以工作的一阶水印信号被平均掉了,只剩一个随模型数增加而缩小的小残差。这也是为什么”3 到 5 个模型”就够,而不需要”几十个”:主导项一上来就死掉了,后面 FAQ 会解释为什么不必再加更多。
真正的难点不在数学,而在于让异构模型真的”可以被平均”。不同大模型的词表和分词器都不一样,概率向量根本对不齐,不能直接相加。这才是工程上的硬骨头。
WASH 内部:对齐错位的词表
WASH 解决两个现实障碍:Qwen3-8B、Llama-3.1-8B、Ministral3-8B 这类模型之间的词表错位与分词差异。当候选词落在共享词表之外时,粗暴平均会失效。WASH 用一种”流畅度感知路由”:对这些超出共享词表的区域交给专精模型处理,而不是用零质量的空槽去污染平均结果。
回报是,WASH 不只是一个攻击的概念验证,它生成的文本是流畅可用的。论文报告生成质量相比竞争性混合方法提升 27.5%,在长序列生成上比那个最强基线快约 6 倍,整体只比单模型解码多 1.0 到 2.4 倍开销。这个开销画像很关键:一个慢 50 倍的攻击在现实中没人会用,而 1-2 倍的开销才是真实攻击者会去跑的东西。
关键结果
- z 分数从 5-304 塌到 2 以下。 加水印的单模型基线检测 z 分数横跨 5.245 到 304.022;WASH 在 N=3 时把它压到约 0.059-1.732,N=5 时进一步压到近零的 0.079-0.461。检测阈值是 4,WASH 稳稳落在它之下。
- 5% 误报率下命中率跌破 50%。 在固定 5% 误报率下,真阳性率从 83.5-95.9%(加水印)降到 WASH(N=5)的 11.3-42.8%,检测基本退化成抛硬币甚至更差。
- 六种方案,全军覆没。 攻击对 AAR、DIPMark、ITS-Edit、KGW、Exp-Edit、Water-Bag 都奏效,既包括流行的绿名单家族(KGW),也包括分布偏移 / 编辑型方案。
- 质量高 27.5%、速度快 6 倍,均相对最强混合基线,开销为单模型的 1.0-2.4 倍。
局限与存疑
整套攻击押在一个假设上:各提供方的水印扰动统计独立。如果两家用了共享水印密钥,或采用了某种协调一致的行业标准,扰动就会相关、就不会抵消——二阶误差项也就不再是主导项。论文的威胁模型是”独立提供方的竞争市场”,这在今天是现实的,但恰恰也是一个协调标准的组织可以反过来破解它的地方。
其次,实验全部在 8B 规模、三个模型家族上完成。当被集成的模型实力悬殊时(一个前沿大模型和几个弱模型平均),独立性假设和质量增益是否还成立,我不会想当然地认为能平滑迁移。把一个弱模型平均进来,可能会以三个同级模型不会出现的方式拖低质量。
第三,这针对的是分布式水印。那些在词分布之外运作的语义水印或后处理水印不在射程内,论文也没声称能打穿它们。
常见问题
WASH 没有密钥怎么去掉大模型水印?
WASH 完全不碰水印密钥。它把 3-5 个各自独立加了水印的模型的输出概率分布做平均。由于每家的水印是往独立方向扰动分布,平均会抵消一阶信号,把干净分布恢复到 O(1/根号N) 的误差内,从而把检测 z 分数压到阈值 4 以下。
为什么只要 3-5 个模型就能干掉水印?
收敛速率虽是 O(1/根号N),但关键在于:检测器精确测试的那个一阶水印项,在独立平均下会立刻抵消,只剩一个不断缩小的二阶残差。所以 3 个模型就已经把 z 分数压到 2 以下;再加到 N=5 只是进一步收紧残差,而非严格必需。
WASH 能打穿所有文本水印吗?
在这篇论文里,WASH 在三个 8B 大模型上攻破了全部六种被测分布式方案(AAR、DIPMark、ITS-Edit、KGW、Exp-Edit、Water-Bag)。它明确针对分布扰动型水印,并不声称能击败语义水印或协调一致的共享密钥水印——打穿那些会违背它的独立性假设。