SkillAdaptor:让 LLM 智能体自己改写技能库
SkillAdaptor 不动模型权重,只从失败轨迹里改写技能库,WebShop 分数 +2.3、PinchBench +1.5,提升真实但有限。
快速答案
SkillAdaptor 是一种免训练的智能体改进方法:它不微调模型,而是直接编辑智能体的技能库(一组可检索的自然语言技能)。任务失败时,它先找出真正出错的那一步,把责任归到对应的技能上,改写这条技能(或新写一条),然后只有在重跑后分数更高时才保留这次修改。整个过程中骨干模型保持冻结。
要说实话:提升是真的,但幅度不大。三个基准上最好的增量分别是 WebShop 分数 +2.3(GLM-5)、WebShop 成功率 +1.7%(Kimi-K2.5)、PinchBench 平均分 +1.5(GLM-5)、Claw-Eval 平均分 +1.8(Kimi-K2.5)。这是一块低成本的可靠性补丁,不是质变。
SkillAdaptor 怎么改技能库
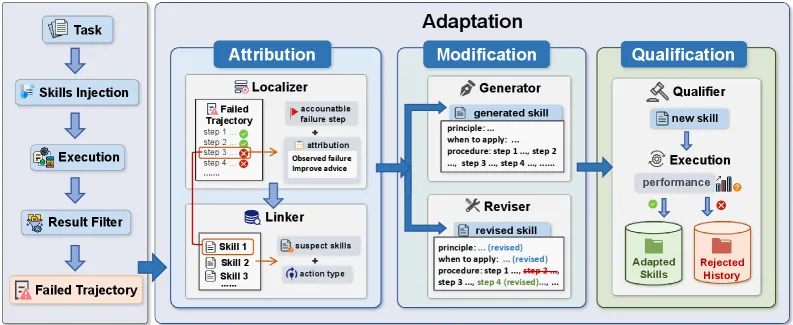
整个闭环分三个阶段,最关键的设计是:任何修改在”自己证明有用”之前都不会被采纳。
- 归因(Attribution)。 一个 Localizer 扫描失败轨迹,锁定第一个可纠正的故障步。它不是任务表面崩掉的那一步,而是最早一个”换个动作就能改变结局”的点。随后 Linker 把责任以权重形式分摊到候选技能上,并决定是改写已有技能还是新建技能。
- 修改(Modification)。 Modifier 要么改写权重最高的技能(修订模式),要么从定位到的上下文里合成一条新技能(生成模式)。语义相似度过滤器会拦掉近乎重复的技能,避免技能库膨胀。
- 验收(Qualification)。 每一条候选修改都会在当前技能集(K)和候选集(K+)下各重跑一次,只有性能提升时才接受,论文的接受规则是 Δ≥0。
推理阶段,冻结的 LLM 只需按嵌入相似度加重排检索相关技能,然后执行。所有”学习”都沉淀在可编辑的自然语言技能里,这也正是它能跨骨干模型迁移的原因。
为什么”冻结骨干”才是重点
这篇工作真正的赌注,是干脆完全不碰权重。让智能体从自己的失败里微调,需要梯度、训练栈,以及一个你被允许更新的模型。而面对 GPT-5.2 这类闭源 API 模型,这些条件一个都没有。把骨干冻结、把所有适配放进可检索的技能库,SkillAdaptor 在 Kimi-K2.5、GLM-5、GPT-5.2 上都能照常工作。这是它的实用价值所在:它只是一层外壳,不需要重训练流水线。
“第一故障步定位”是真正出力的部分。大多数”从失败中学习”的智能体循环,是把整段坏轨迹塞回上下文,寄希望于模型自我纠错。而定位最早的因果错误、再把责任挂到具体技能上,是更锐利的信号;Δ≥0 的验收门则保证技能库在多轮迭代后不会逐渐退化成垃圾。
关键结果
- WebShop: 相对冻结骨干 +2.3 分(GLM-5),成功率 +1.7%(Kimi-K2.5)。
- PinchBench: 平均分百分比 +1.5(GLM-5)。
- Claw-Eval: 平均分 +1.8(Kimi-K2.5)。
- 对比 EvoSkill(WebShop):SkillAdaptor 在 Kimi-K2.5 上拿到 41.6 分,EvoSkill 为 40.4,领先,但只领先约一分。
- 论文还报告了逐轮的接受写入数与收益,以及交互步数、输入 token 统计,至少把成本一面摆出来量化,而不是藏起来。
三个基准上的共同模式是稳定的个位数低位提升。“跨骨干都稳定”是更有说服力的故事;幅度本身则很克制。
局限与存疑
作者对失效场景说得很坦诚。SkillAdaptor 在失败能暴露可观测的中间信号、且所需工具依赖可用时最有效。一旦反馈稀疏或延迟,或者智能体需要的外部接口干脆缺失,方法就会变弱。这是个有分量的提醒,因为那些缺乏可观测性的硬环境,恰恰是智能体最容易翻车的地方。
采用前还要掂量两点。其一,评测只覆盖三个公开基准,没有长期部署验证,所以技能库在野外跑过上千轮后会怎样,我们并不知道。其二,单任务成本是实打实的:验收阶段要在两套技能集下各重跑一次候选修改,被接受的更新执行量大约翻倍。如果你跑的是廉价高并发任务,这点开销可能直接吃掉那 +1.5 分的收益。
谁可以跳过:如果你的智能体失败本就是稠密奖励、权重可调、工具齐全,那你有更便宜的路(直接微调)。SkillAdaptor 的价值,恰恰在骨干被冻结、且失败可读这种特定情形下才兑现。
常见问题
SkillAdaptor 会微调 LLM 吗?
不会。SkillAdaptor 从不更新模型权重,骨干始终冻结。所有适配都通过编辑一个自然语言技能库完成,智能体在推理时检索这些技能,这也是它能跑在 GPT-5.2 这类闭源模型上的原因。
SkillAdaptor 到底能提升多少性能?
幅度不大但稳定。最好的结果是 WebShop 分数 +2.3、WebShop 成功率 +1.7%、PinchBench +1.5、Claw-Eval +1.8(均相对冻结骨干)。它是个位数低位的可靠性补丁,不是大跨越。
SkillAdaptor 和”把失败轨迹塞回上下文重放”有何不同?
它不是把整段失败轨迹喂回模型,而是定位第一个可纠正的故障步,把责任归到具体技能,改写该技能,并且只有当重跑分数不降(Δ≥0)时才接受这次修改。