MemDreamer:用分层图记忆理解长视频
MemDreamer 把长视频问答变成在三层图记忆上的智能体检索,LVBench 从 78.2 升到 90.7(+12.5),推理只读约 6K token,不是 24 万到 78 万。
快速答案
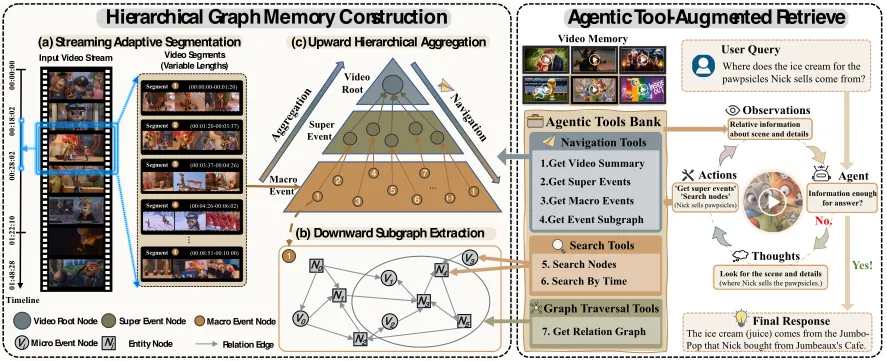
MemDreamer 是一个免训练框架,让 VLM 不再一次性读完整段长视频。一个感知模型把视频流式地写进三层图记忆(Video Root、Super Event、Macro Event,叶子层是实体与微事件子图),另一个推理模型通过七个检索工具,在这份文本记忆上跑 Observation-Reason-Action 循环来回答问题。在 LVBench 上它拿 90.7,而同一个 Gemini-3.1-Pro 端到端跑只有 78.2,差 12.5 分,离人类专家还差 3.7 分。推理模型每次只看约 5.9K 到 6.3K token,端到端 VLM 要吞 24 万到 78 万,差不多砍掉 40 倍。这份提升归功于记忆结构和检索脚手架,不是换了更大或重新训练过的模型。
长视频为什么压垮耦合式 VLM
一段两小时视频按 1 FPS 采样会产生超过 160 万 token,超出当前所有上下文上限,所以耦合式 VLM 只能猛抽帧,然后让答案淹没在噪声里。论文指出 token 进了上下文后有两个失效点:注意力被稀释,以及”中间内容丢失”效应,两者都会掏空长程推理。这里的解法是让推理模型根本看不到原始视频。感知离线跑一遍,写出一份紧凑的文本记忆;推理在线时只在这份记忆上跑。
三层图记忆
记忆按由粗到细构建,且全程是纯文本,检索时不再回看原始帧。流式自适应分段器按语义边界切分(10 分钟滑动窗口),不是固定 30 秒切块,得到自洽的 Macro Event。每个 Macro Event 向下展开成一张局部子图,节点是实体和微事件,用三类边连起来:空间属性边、主谓宾边、时序因果边。系统再向上聚合:Macro Event 聚成 Super Event,收敛到单个 Video Root 摘要。图的拓扑才是关键。消融把它退回扁平切块存储,分数掉到 77.4;只加因果时序边能回到 84.8,只加层级能回到 86.3。完整的分层图拿到 90.7,说明层级和边修的是不同失效点,叠加生效。
这沿着把智能体记忆做成图结构(而非扁平日志)的大方向走,文本智能体上的相关探索见 记忆是重构出来的,不是检索出来的。MemDreamer 让这套结构承载视频的时空与因果信息。
是智能体检索,不靠向量匹配
推理模型拿到七个工具,分三组:层级导航(取摘要、取 Super/Macro Event、取子图)、精确搜索(语义节点搜索、按时间搜索)、图遍历(沿关系边走)。它跑一个迭代循环,工具调用上限 12 轮,凑齐证据就停。这个设计的意义在跟更便宜的基线对比时才显出来:静态向量匹配只有 70.5,完整智能体工具集是 90.7,差 20.2 分。换成把整张图塞进上下文(“Full Memory”),对摘要有帮助(81.3),但推理题上崩到 72.7,因为未筛选的结构带来拓扑噪声。在工具集消融里,图遍历是单项最大涨幅(+6.6),因为沿实体和因果边的多跳链能答出”跨事件推理”的问题,扁平语义召回答不出来。这跟 重新思考检索、别只看语义相似度 是同一条教训:相似的片段不等于相关的片段。
关键结果
- LVBench: Gemini-3.1-Pro 同时做感知和推理拿 90.7,同一模型端到端只有 78.2(+12.5),离人类专家还差 3.7 分。
- LongVideoBench / Video-MME(长)/ EgoSchema: 92.9(+14.3)、91.0(+14.0)、92.1(+11.8),四个基准都报为新 SOTA。
- 开源底座: Qwen3-VL-235B-A22B-Thinking 从端到端的 63.6 升到框架内的 84.8(+21.2),说明 harness 对偏弱的推理模型帮助更大。
- 上下文开销: 推理窗口装 5.9K 到 6.3K token,整段视频吞入要 24 万到 78 万,约省 40 倍;感知阶段本身用 40.3K。
- 推理相关性: 八个模型上,AIME2025 与 LVBench 在端到端下的 Pearson 相关只有 0.702(p=0.052,不显著),在 MemDreamer 下升到 0.897(p < 0.01)。
- 换感知模型很省: 感知在 Gemini-2.5-Pro 和 3.1-Pro 之间换,LVBench 最终分只动 0.4 到 1.4 分,因为感知只处理 10 分钟以内的短片段。
怎么读这个头条数字
“即插即用”没说错,但容易读过头。90.7 这个结果让 Gemini-3.1-Pro 同时当感知和推理引擎,所以这不是小模型打赢前沿模型,而是前沿模型在你不再逼它一次读完整段视频后表现更好。论文做的公平对比是同一模型端到端 vs 同一模型放进 MemDreamer,这条轴上 +12.5 干净。更有意思的是相关性结果:耦合范式下模型的推理水平几乎预测不了它的长视频分数,而 MemDreamer 让两者对上了。这把长视频的进展重新定位成检索与记忆问题,而非感知问题。同样的解耦直觉,用在整段视频理解而非记忆工具上,见 Watch, Remember, Reason。
局限与存疑
论文没有专门的局限章节,对一个零件这么多的智能体系统,这本身就是个信号。最大的缺口是感知端的成本账:构建记忆要让一个强 VLM 完整流式跑一遍(LVBench 上每段视频 40.3K 感知上下文),论文只报了那个很薄的推理窗口,没报前期构建账单,所以”2% 上下文”说的是推理,不是总工作量。两个阶段都没有墙钟或费用数字,也没测记忆构建错误怎么传播:一整张错的子图会悄悄给准确率封顶,而感知没写进去的东西智能体再也找不回来。锚定 3.7 分差距的人类专家基线也没交代来源。工具轮数(12)、搜索 top-k、嵌入模型都是调过的旋钮。而且这里每个基准都是精选视频问答,框架在大规模开放式摘要、在记忆需要实时更新的流式在线场景下都还没测过。
常见问题
MemDreamer 需要重新训练底座 VLM 吗?
不需要。MemDreamer 是即插即用、免训练的框架。它把现有 VLM 包进一个感知阶段(构建图记忆)和一个推理阶段(在记忆上检索)。LVBench 从 78.2 到 90.7 的提升完全来自记忆结构和智能体检索循环,两个角色用的都是同一套 Gemini-3.1-Pro 权重。
MemDreamer 为什么用 2% 上下文就能在 LVBench 拿 90.7?
推理模型根本不吞原始视频。它通过检索工具读一份紧凑的文本记忆,每次只装约 5.9K 到 6.3K token,而端到端整段视频吞入要 24 万到 78 万,约省 40 倍。“2%“指的是推理阶段的上下文,不含构建记忆的那次感知遍历。
MemDreamer 里智能体检索为什么胜过向量搜索?
消融里静态向量匹配只有 70.5,完整智能体工具集是 90.7,差 20.2 分。单轮语义召回会找到视觉相似但跟问题没有因果联系的片段,而且不能自我纠错。迭代工具循环,尤其是沿因果边的图遍历(单项工具最大涨幅 +6.6),能顺着逻辑链走,扁平相似度搜索追不上。
MemDreamer 报的推理与长视频性能相关性是什么?
八个模型上,AIME2025 推理分数与 LVBench 在端到端吞入下的 Pearson 相关为 0.702(p=0.052),在 MemDreamer 下为 0.897(p < 0.01)。解读是:原始长视频 token 挡住了模型用自己的推理能力,解耦把这条联系恢复了,所以越强的推理模型从框架里拿到的收益越大。
MemDreamer 用了哪些基准和底座模型?
四个长视频基准:LVBench(103 段视频,30 分钟到 2 小时)、LongVideoBench、Video-MME 长视频切分、EgoSchema。感知用 Gemini-3.1-Pro;推理引擎评测了 Gemini-2.5-Pro、Gemini-3.1-Pro 和开源的 Qwen3-VL-235B-A22B-Thinking,嵌入用 Qwen3-Embedding,工具预算 12 轮。
一句话:MemDreamer 表明长视频理解的卡点在你怎么存、怎么取这段视频,不在原始上下文长度,不重训就把 78.2 的 LVBench 底座变成 90.7。阅读 arXiv 原文。