ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
ARIS is an open-source autonomous-research harness pairing a Claude-family executor with a GPT-family reviewer to attack the failure it calls 'plausible unsupported success', with 65+ skills and a three-stage audit.
Quick answer
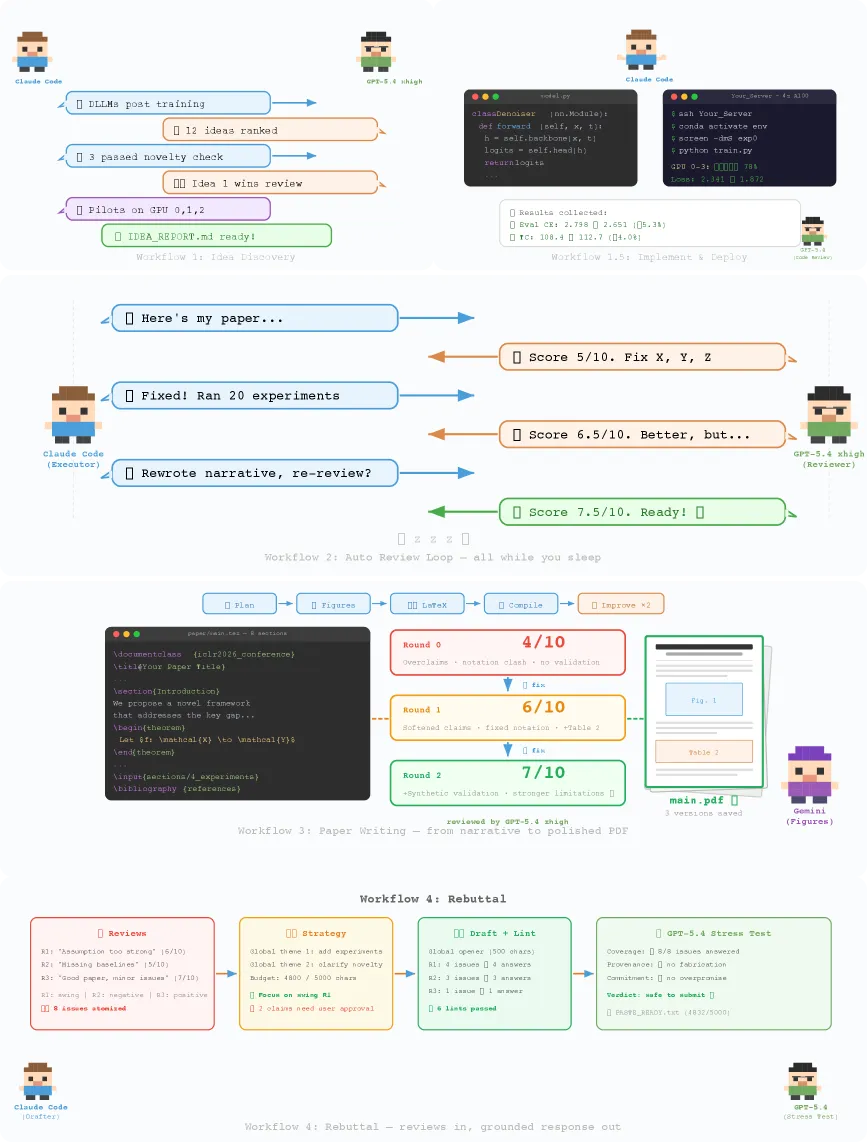
ARIS is an open-source harness for running research workflows autonomously, and its one real idea is targeting a specific failure mode the authors name “plausible unsupported success” — when a long-horizon agent does not crash but quietly produces claims it never verified. ARIS attacks this by making adversarial review the default: a Claude-family executor model is paired with a reviewer from a different family (GPT, Gemini, GLM, MiniMax, Kimi, or DeepSeek) that critiques and forces revision of intermediate results. The system ships over 65 reusable Markdown-defined skills, five end-to-end workflows, and a three-stage evidence-to-claim audit.
The failure mode ARIS is built around
The interesting framing here is what counts as failure. Most agent-reliability work worries about visible breakdowns — the loop crashes, the tool errors, the model gets stuck. ARIS argues the dangerous case is the opposite: the run completes, the paper looks finished, and the conclusions are unsupported. The authors call this “plausible unsupported success,” and it is harder to catch precisely because nothing looks broken. An autonomous research agent that fabricates a clean result is worse than one that fails loudly, because a human downstream will trust the polished artifact. Everything in ARIS is organized around making that quiet failure expensive to reach.
Cross-model adversarial collaboration
The core mechanism is that the executor and the reviewer come from different model families on purpose. The default pairing is a Claude executor with a GPT reviewer (wired through Codex MCP and an “Oracle” MCP), and the reviewer’s job is to attack intermediate outputs rather than rubber-stamp them. The bet is that two models from the same family share blind spots and will agree too readily; a cross-family critic is more likely to flag a hallucinated citation or an unsupported leap. This is a sensible instinct, though it is an engineering choice the paper presents as a default configuration, not a measured ablation — the harness is described more than it is benchmarked.
What is actually in the harness
ARIS is structured in three layers. The execution layer holds the skills — more than 65 reusable Markdown files plus model integrations, a persistent research wiki, and deterministic figure generation. The orchestration layer defines five workflows: idea discovery, an experiment bridge, an auto-review loop, paper writing, and rebuttal, each with adjustable “effort” settings. The assurance layer is where the adversarial idea becomes concrete: a three-stage evidence-to-claim audit (experiment-integrity audit, result-to-claim mapping, and a paper-claim audit), a five-pass scientific-editing pipeline, mathematical proof checks, citation audits, and visual inspection of the rendered PDF. It is portable across executors — the paper reports it tested on Claude Code, Codex CLI, and Cursor, with three more adapted.
Key results
ARIS is a systems-and-tooling paper, not a benchmark paper, so its evidence is descriptive rather than a leaderboard. The concrete numbers it reports:
- Over 65 reusable Markdown-defined skills in the execution layer, plus 30+ community-contributed skills.
- Five end-to-end workflows — idea discovery, experiment bridge, auto-review loop, paper writing, rebuttal.
- A three-stage evidence-to-claim audit and a five-pass scientific-editing pipeline.
- An illustrative overnight run that ran four review-revision rounds, raised the reviewer score from 5.0 to 7.5 out of 10, and launched 20+ GPU experiments.
- Tested on three executor platforms (Claude Code, Codex CLI, Cursor) with three more adapted, and a default executor/reviewer pairing drawing on six+ reviewer models (GPT-5.4, Gemini, GLM, MiniMax, Kimi, DeepSeek).
The 5.0-to-7.5 figure is a single anecdotal run scored by the system’s own reviewer model, not an external benchmark — read it as a demo, not proof.
Why this matters now
Autonomous “research while you sleep” agents are having a moment, and most of them optimize for finishing the task. ARIS is one of the few that treats the finished-but-wrong output as the primary enemy and builds plumbing specifically to catch it. Whether or not the cross-model trick holds up under scrutiny, the framing — that the real risk in long-horizon agents is confident-looking unsupported output, not crashes — is the part worth taking away, and the harness is open source so the assurance layer can be reused independently.
Limits and open questions
The honest gap is evidence. ARIS describes an architecture and reports one illustrative overnight run; it does not provide a controlled study showing the adversarial reviewer measurably reduces unsupported claims versus a single-model baseline. The headline 5.0-to-7.5 improvement is graded by an LLM reviewer inside the same system, so it is circular as a quality metric. The authors are explicit about the ceiling: “Aris cannot guarantee that any output is correct, novel, or scientifically sound” — the audits lower the rate of bad output, they do not certify good output. Running a Claude executor plus a separate GPT-family reviewer across multiple workflows is also expensive, and the paper does not quantify that cost. Anyone hoping for a turnkey paper generator should reset expectations: this is an instrumented, human-in-the-loop scaffold, not an autopilot.
FAQ
What problem does ARIS solve?
ARIS targets “plausible unsupported success” — the case where an autonomous research agent completes a run and produces a polished, finished-looking artifact whose claims were never actually verified. It adds an assurance layer of audits and adversarial review to make that quiet failure harder to reach.
How does ARIS use adversarial collaboration?
ARIS pairs an executor model (Claude family by default) with a reviewer from a different model family (GPT, Gemini, GLM, MiniMax, Kimi, or DeepSeek). The reviewer critiques intermediate results and forces revision, on the bet that a cross-family critic catches blind spots a same-family model would share.
Is ARIS open source and which tools does it run on?
Yes — ARIS is released as an open-source harness and was tested on three executor platforms: Claude Code, Codex CLI, and Cursor, with three more adapted. It ships over 65 Markdown-defined skills plus 30-plus community-contributed ones.
Does ARIS guarantee correct research output?
No. The authors state plainly that ARIS cannot guarantee any output is correct, novel, or scientifically sound. Its three-stage evidence audit and five-pass editing lower the chance of unsupported claims but do not certify that results are right.
One line: ARIS bets that a cross-family reviewer attacking your agent’s work is the cheapest defense against confident-but-wrong autonomous research. Read the original paper on arXiv.