Reinforcement Learning · Diffusion Models · Text-to-Image
Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching
Flow-DPPO swaps PPO ratio clipping for an exact per-step Gaussian KL term, lifting GenEval2 to 48.1 on SD3.5 (vs 39.9 for Flow-GRPO) while cutting policy drift roughly 4x.
Quick answer
Flow-DPPO is an online RL objective for flow-matching image generators that throws out PPO-style ratio clipping and replaces it with an exact KL divergence computed per denoising step. On Stable Diffusion 3.5 Medium it reaches 48.1 GenEval2 under multi-reward training, against 39.9 for Flow-GRPO-style ratio clipping and 44.6 for Flow-CPS. On FLUX2-klein-base-9B it hits 57.7 vs 46.8 for Flow-GRPO. The reward is higher and the drift is smaller: policy KL is 0.17 (×10⁻³) on FLUX2 single-reward, where Flow-GRPO sits at 0.77.
Why ratio clipping is the wrong tool for flow models
PPO controls how far each update moves the policy by clipping the probability ratio between the new and old policy. That ratio is a single-sample Monte Carlo estimate of the divergence between the two policies. In an LLM you get one such ratio per token and the noise averages out across a long sequence. In a flow model the “action” at each denoising step is a continuous Gaussian sample, and you have one sample per step, so the ratio is a high-variance proxy for a quantity you could compute in closed form.
The authors’ observation is that you don’t need to estimate the divergence at all. Each per-step policy in a flow model is Gaussian with a known mean and variance, so the KL between old and new policy is just ||μ_old − μ_θ||² / (2σ²). That is exact, deterministic, and computed from the two forward passes the optimizer already runs. Ratio clipping spends its variance budget approximating something the model hands you for free.
How the divergence proximal term works
Flow-DPPO uses the closed-form per-step KL as a proximal constraint instead of a clip. The non-obvious piece is the asymmetric mask. A naive KL penalty blocks any update once divergence crosses a threshold, including updates that pull the policy back toward the old one. Flow-DPPO only blocks a gradient when two conditions hold at once: the update moves away from the old policy, and divergence already exceeds the threshold. Corrective updates toward the old policy are never blocked.
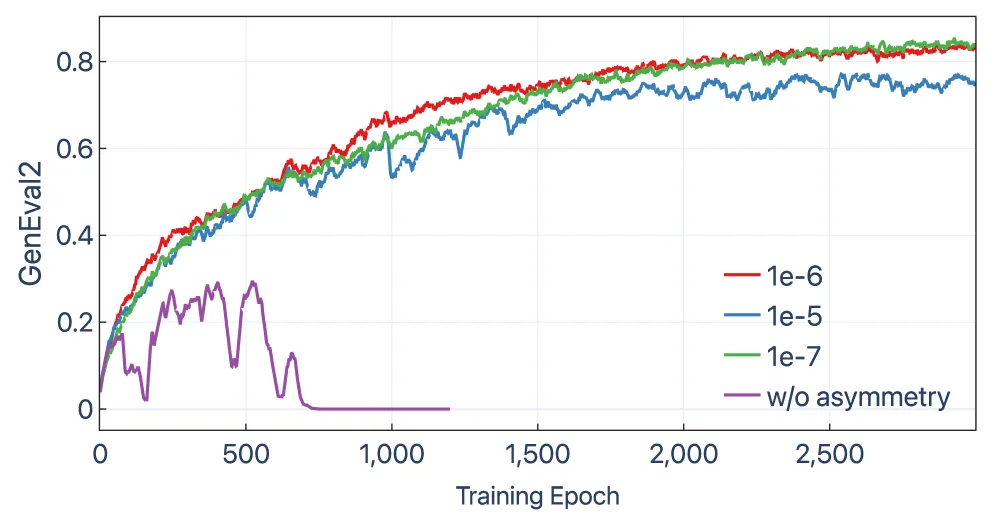
This asymmetry is load-bearing, not a tuning nicety. The ablation on SD3.5 shows that without it, GenEval2 climbs to about 0.3 early and then collapses to zero, while the asymmetric version converges smoothly across learning rates from 1e-7 to 1e-5. A symmetric KL constraint traps the policy on the wrong side of the threshold; the directional mask lets it walk back.
Key results
- GenEval2, SD3.5-Medium, multi-reward: Flow-DPPO 48.1 vs Flow-GRPO 39.9, Flow-CPS 44.6, GRPO-Guard 47.8. The combined Flow-DPPO+CPS reaches 51.6, the best single number in the table.
- GenEval2, FLUX2-klein-base-9B, multi-reward: Flow-DPPO 57.7 vs Flow-GRPO 46.8, Flow-CPS 47.1, GRPO-Guard 49.0. Here plain Flow-DPPO beats the +CPS combo (55.2).
- Policy drift (KL ×10⁻³): FLUX2 single-reward 0.17 for Flow-DPPO vs 0.77 for Flow-GRPO; SD3.5 multi-reward 2.49 vs 3.81. Lower drift is the direct evidence that the exact-KL constraint is steadier than clipping.
- Catastrophic forgetting: out-of-domain metrics degrade less. On FLUX2 multi-reward Flow-DPPO posts PickScore 25.76 / CLIP 0.282 / HPSv2 0.368, ahead of Flow-GRPO’s 25.61 / 0.277 / 0.357, so the in-domain reward gain does not come at the cost of general image quality.
- Asymmetric masking ablation: removing the directional mask makes SD3.5 training collapse to 0 GenEval2; keeping it gives stable convergence. This is the clearest single piece of evidence that the mask, not just the KL form, is what makes the method work.
- Multi-epoch reuse (G64-I2): Flow-DPPO keeps improving with sample reuse where Flow-GRPO and Flow-CPS plateau or degrade, which matters because sample reuse is how you cut the cost of online RL on a 9B image model.
What the headline does not prove
The best number in the paper, 51.6 GenEval2, is Flow-DPPO+CPS, a combination of Flow-DPPO with an existing technique, not Flow-DPPO alone. On SD3.5 the combo wins; on FLUX2 plain Flow-DPPO actually wins, so “Flow-DPPO scores 51.6” is the wrong takeaway. Read the two columns separately.
The title says “image/video,” but every reported number is text-to-image (GenEval2, PickScore, CLIP, HPSv2) on SD3.5, FLUX.1-dev, and FLUX2. There is no video benchmark in the paper. The Gaussian per-step argument should transfer to video flow models, but that is an expectation, not a measured result here. If you came for video RL numbers, this paper does not have them yet.
The method shares its lineage with token-level trust-region work from the same group; the token-level trust region in LLM RL paper makes the parallel argument that a single global clip is too blunt, and it is the natural predecessor to read alongside this. Flow-DPPO is also adjacent to on-policy distillation for the same model family, covered in Flow-OPD.
Limits and open questions
The exact KL relies on the per-step policy being Gaussian, which holds for the SDE sampler the paper uses but is an assumption about the sampler, not a universal property of flow models. The threshold and the asymmetric mask add hyperparameters; the paper shows stable training across three learning rates but does not sweep the threshold itself. There is no compute or wall-clock comparison against Flow-GRPO, so “exact and free” describes the divergence term, not the end-to-end training cost. And the strongest combined result leans on CPS, so part of the gain is borrowed from a method Flow-DPPO is supposed to replace. Reproducibility depends on the released code at Tencent-Hunyuan/UniRL.
FAQ
How does Flow-DPPO compare to Flow-GRPO on GenEval2?
On SD3.5-Medium with multi-reward training, Flow-DPPO scores 48.1 GenEval2 versus 39.9 for Flow-GRPO, an 8.2-point gap. On FLUX2-klein-base-9B it is 57.7 versus 46.8. Flow-DPPO also keeps policy KL lower (0.17 vs 0.77 ×10⁻³ on FLUX2 single-reward), so the reward gain comes with less drift from the pretrained model.
Why is ratio clipping ill-suited for flow matching models?
The PPO probability ratio is a single-sample Monte Carlo estimate of the divergence between old and new policy. A flow model produces one continuous Gaussian sample per denoising step, so the ratio is a high-variance proxy. Because each per-step policy is Gaussian, Flow-DPPO instead computes the KL in closed form as ||μ_old − μ_θ||² / (2σ²), which is exact and uses forward passes the optimizer already runs.
Is Flow-DPPO+CPS the same as Flow-DPPO?
No. Flow-DPPO+CPS combines Flow-DPPO with the existing CPS technique. The 51.6 GenEval2 headline on SD3.5 is the combo, not Flow-DPPO alone (48.1). On FLUX2 the combo (55.2) is actually worse than plain Flow-DPPO (57.7), so the two should be read as separate configurations.
Does Flow-DPPO train on video or only text-to-image?
Only text-to-image in the reported experiments. Every benchmark (GenEval2, PickScore, CLIP, HPSv2) runs on SD3.5, FLUX.1-dev, and FLUX2 image generators. Despite the “image/video” framing in the title, the paper contains no video benchmark; the Gaussian per-step argument is expected to extend to video but is not measured.
What does the asymmetric masking ablation show?
Removing the directional mask makes SD3.5 training collapse to 0 GenEval2 after an early bump to about 0.3, while keeping it gives smooth convergence across learning rates. The mask only blocks updates that move away from the old policy past the divergence threshold, never updates that pull back toward it. It is the component that actually stabilizes training, not just the exact-KL form.
One line: Flow-DPPO replaces a noisy single-sample clip with a free, exact per-step KL plus a directional mask, getting 48.1 GenEval2 on SD3.5 against 39.9 for Flow-GRPO at roughly a quarter of the policy drift. Read the original paper on arXiv.