Reinforcement Learning · LLM Reasoning · Language Models
CPPO: Beyond Uniform Token-Level Trust Regions in LLM RL
CPPO replaces PPO's one-size threshold with stricter early-token clipping and a running prefix-divergence budget, lifting Qwen3-30B-A3B-Base AIME from 49.23 (DPPO) to 54.79.
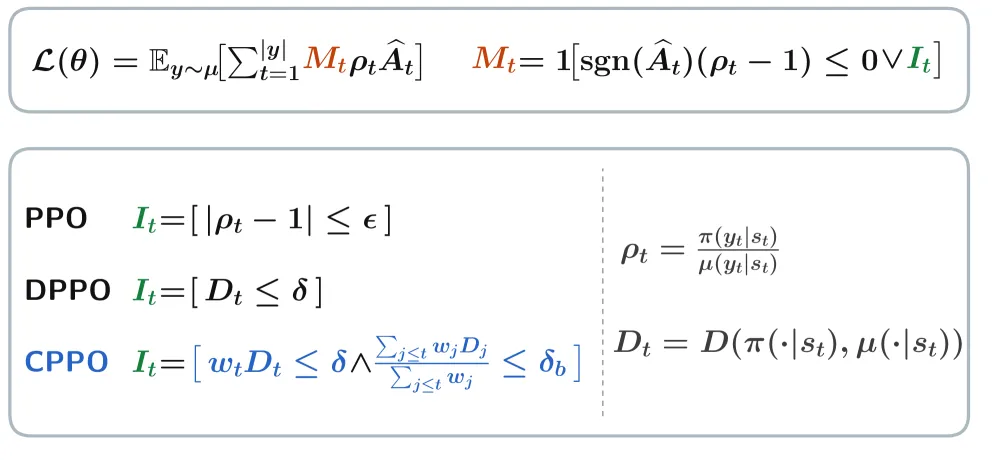
Quick answer
CPPO (Cumulative Prefix-divergence Policy Optimization) is a token-level masking rule for LLM reinforcement learning that stops treating every token’s trust region as equal. It applies a stricter clipping threshold to early tokens and tracks a running budget of how far the prefix has already drifted, masking an update once that budget is spent. On AIME24/25/26 Avg@16, CPPO reaches 54.79 on Qwen3-30B-A3B-Base against 49.23 for DPPO (+5.56) and 38.19 for GRPO (+16.6), and it leads on all four model settings tested. The gain is a training-stability story, not a new objective: same data, same reward, only the clip rule changes.
Why a uniform clip is the wrong default
PPO-style RL for reasoning (GRPO, DAPO and friends) keeps the new policy close to the old one with a single clip threshold applied identically to every token in a sequence. That ignores how autoregressive generation actually breaks. A wrong token early in a chain of thought re-conditions everything after it, so the same per-token deviation does more damage at position 5 than at position 500. A uniform threshold also has no memory: it checks each token in isolation and never asks how far the prefix has already wandered before this point. CPPO names these two blind spots autoregressive asymmetry and cumulative prefix drift, and the figure-2 measurements back the diagnosis — measured policy deviation really is larger and heavier-tailed at early positions, which is exactly where a flat threshold is most permissive in relative terms.
How the two knobs work
The first knob is a linear position weight. Token t gets weight w_t that decays from 1.0 at the first token to w_min (default 0.8) at the last, so the effective threshold δ/w_t is tightest early and loosens toward the end of the sequence. The second knob is the cumulative prefix budget. The rule keeps a weighted running sum of prefix divergence S_t and a cumulative weight W_t, and the effective ceiling at token t becomes min{δ, δ + δ_b·W_{t-1} − S_{t-1}}. Plain English: each token starts with the normal allowance δ, but if earlier tokens already overspent the prefix budget δ_b, the allowance shrinks, and a token is masked once it would push the prefix past what the budget permits. So a token can be killed either for deviating too much on its own or for arriving after a prefix that has already drifted too far. The paper frames this as aligning each update with a finite-horizon policy-improvement bound rather than a heuristic clip.
This is the same author group behind Flow-DPPO, which carries a PPO trust region into flow-matching generation; CPPO is the language-model-RL sibling that questions the token-uniform assumption instead.
Key results
- Qwen3-30B-A3B-Base, AIME Avg@16: CPPO 54.79 vs DPPO 49.23 (+5.56), GRPO 38.19, MinPRO 48.12. This is the headline and the largest margin.
- Smaller scales: CPPO 31.88 on Qwen3-1.7B (vs 28.82 best baseline CISPO), 12.78 on 1.7B-Base, 31.11 on 8B-Base. It wins all four columns, with margins over the second-best method of 3.06, 0.91, 1.39 and 5.56 points.
- Baselines are not weak: the comparison set includes DPPO, MinPRO, CISPO, TRM-Max and TRM-Avg, so this is measured against current trust-region variants, not a vanilla-PPO strawman.
- Stability under collapse: CISPO collapses outright on Qwen3-30B-A3B-Base while CPPO trains cleanly, and the Figure 4 curves show CPPO holding its lead across the whole run rather than spiking and reverting.
- Both knobs pull their weight (Figure 5): CPPO without the prefix budget (position weights only) and CPPO without position weights (prefix budget only) each still beat DPPO; the full method is best. Neither component is dead weight.
- Ordering itself helps, beyond tighter clipping (Figure 5): shuffling the position weights across tokens while keeping the same threshold values underperforms the ordered schedule, which is the cleanest evidence that the early-token emphasis is what helps, beyond a tighter average clip.
Limits and open questions
The entire evaluation is AIME-family math reasoning on Qwen3 models. There is no coding, agentic, or open-ended generation result, so “improves reasoning across model scales” is a claim about competition math under verifiable rewards, not a general RLVR win. The 30B run is the only MoE result and uses a different δ (0.2 vs 0.15 for dense models) and an adaptive δ_b for Base models, so the largest, most quotable margin sits on the least directly-comparable configuration. CPPO also adds two hyperparameters (δ_b, w_min) on top of the shared threshold; the paper reports neighboring values stay competitive, but tuning cost on a new model family is real and unmeasured here.
Should you adopt it
If you already run GRPO/DAPO/DPPO on long-chain reasoning and see instability or a stubborn ceiling, CPPO is cheap to try: it is a clip-rule swap inside the same loss, no extra reward model, no new data. The ablation that masking early tokens harder is what moves the needle is a useful prior even if you do not adopt the full machinery. If your task is short-horizon or your sequences are short, the autoregressive-asymmetry premise is weaker and the gains will likely shrink, because there is less prefix for early errors to compound through. Wait for a non-math, longer-horizon reproduction before treating the 30B margin as a general result.
FAQ
What is CPPO in LLM reinforcement learning?
CPPO (Cumulative Prefix-divergence Policy Optimization) is a token-level masking rule for PPO-style LLM RL. It clips early tokens more strictly than late ones using a linear position weight, and tracks a cumulative prefix-divergence budget so a token is masked once the conditioning prefix has already drifted too far. On Qwen3-30B-A3B-Base it reaches 54.79 AIME Avg@16 vs 49.23 for DPPO.
Why does a uniform token-level trust region fail in autoregressive RL?
Because a wrong early token re-conditions the whole rest of the sequence, so an identical per-token deviation does more damage early than late, and a flat threshold has no memory of how far the prefix has already drifted. CPPO’s Figure 2 shows measured policy deviation is larger and heavier-tailed at early positions, which is exactly where a uniform clip is most permissive in relative terms.
In CPPO, does the position weight or the cumulative prefix budget matter more?
Both contribute and neither is redundant. Figure 5 shows that removing either one still beats the DPPO baseline, but the full method with both is best. The cleanest signal is the shuffle test: randomizing the position weights while keeping their values hurts, so the early-token ordering itself is doing work, not just a tighter average clip.
How much does CPPO beat DPPO and GRPO on AIME?
On Qwen3-30B-A3B-Base AIME24/25/26 Avg@16, CPPO scores 54.79 versus 49.23 for DPPO (+5.56) and 38.19 for GRPO (+16.6). It also wins on Qwen3-1.7B (31.88), 1.7B-Base (12.78) and 8B-Base (31.11), though smaller-scale margins can be under 1.5 points.
Is CPPO a general RLVR method or math-only so far?
So far it is math-only in evidence. Every reported number is AIME-family competition math on Qwen3 models under verifiable rewards. The mechanism is task-agnostic, but there is no coding, agentic, or open-ended result, so treat general-RLVR claims as untested. Compare with how N-GRPO and APPO are validated across task families before adoption.
One line: CPPO shows that where in a sequence you tighten the trust region matters as much as how much — stricter early-token clipping plus a prefix-drift budget turns a 49.23 DPPO run into 54.79 on Qwen3-30B-A3B. Read the original paper on arXiv.