Diffusion Language Models · Language Models
LLaDA: An 8B Diffusion Language Model That Rivals LLaMA3
LLaDA trains an 8B language model by masked diffusion instead of next-token prediction, matches LLaMA3 8B in in-context learning, hits 70.7 on GSM8K, and beats GPT-4o on the reversal-curse poem task.
Quick answer
LLaDA is an 8B-parameter language model that drops next-token prediction entirely and instead generates text by reversing a masking process — the same idea behind image diffusion, adapted to discrete tokens. Trained from scratch on 2.3 trillion tokens, it matches LLaMA3 8B on in-context learning, scores 70.7 on GSM8K (vs LLaMA3 8B’s 53.1), reaches 65.9 on MMLU (vs 65.4), and — most striking — beats GPT-4o on a reversal poem-completion task (42.4% vs 34.3%), a weakness autoregressive models have never cleanly solved. It is the first credible evidence that the “LLM = autoregressive” assumption is a choice, not a law.
How a diffusion LLM actually works
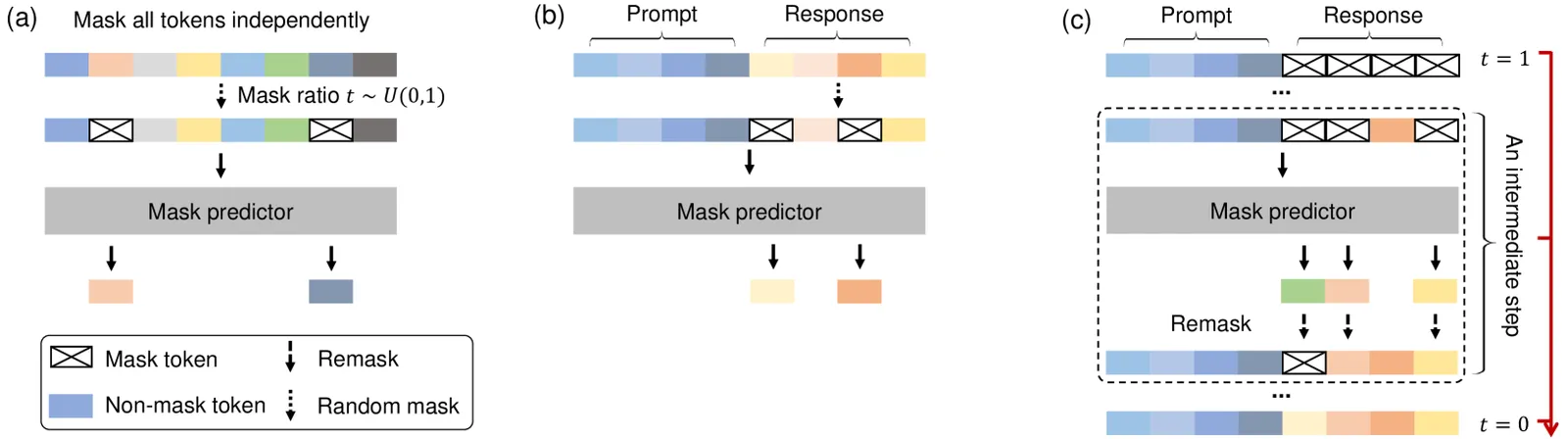
An autoregressive model writes left to right: predict token i from tokens 1…i−1. LLaDA never does that. It defines a forward masking process that, at a random ratio t between 0 and 1, independently replaces each token with a [MASK]. A plain Transformer — the mask predictor — is trained to recover all the masked tokens at once. At generation time you start from a fully masked sequence and run the process in reverse: predict, keep the confident tokens, re-mask the rest, repeat over a fixed number of steps until nothing is masked.
The training objective is not the autoregressive likelihood; it is a lower bound on the log-likelihood of a masked diffusion. That distinction matters because it means LLaDA is a principled generative model with a real likelihood, not a heuristic — the authors lean on this to argue diffusion should scale, and then show it does.
Key results
- GSM8K (math, 4-shot): 70.7 for LLaDA 8B Base vs 53.1 for LLaMA3 8B Base — a large, not marginal, gap in LLaDA’s favor.
- MMLU (5-shot): 65.9 vs 65.4 — effectively tied with LLaMA3 8B.
- Reversal curse: LLaDA 8B Instruct hits 42.4% on a reversal poem-completion task vs GPT-4o’s 34.3%. Because masking is symmetric, LLaDA has no built-in left-to-right bias, so “complete this backwards” is not structurally harder for it.
- Token efficiency: it reaches LLaMA3-comparable quality on 2.3T training tokens against LLaMA3’s reported 15T, using 0.13M H800 GPU-hours.
- Scaling: across compute scales LLaDA tracks the authors’ self-built autoregressive baselines closely, beating them on MMLU and GSM8K — the headline claim is competitive scaling, not just one strong checkpoint.
What’s genuinely new versus prior diffusion-LM work
Discrete diffusion for text is not new; what was missing was scale and a fair fight. Earlier masked or discrete diffusion language models topped out far below 1B parameters and were never trained on a frontier-scale token budget, so nobody could say whether the approach broke at 8B. LLaDA is the first to push a pure masked-diffusion LLM to 8B from scratch and put it head-to-head with a same-recipe autoregressive baseline. The reversal-curse result is the cleanest demonstration of the structural payoff: it is not that LLaDA is smarter, it is that the bidirectional objective removes a failure mode autoregressive models inherit by construction.
Limits and open questions
The honest caveat is inference. LLaDA generates over a fixed number of denoising steps, and quality trades off against step count — there is no cheap one-pass decode and no mature KV-cache analog, so per-token cost and latency are real concerns versus a tuned autoregressive serving stack. The instruct model still trails LLaMA3 8B Instruct on several chat/instruction benchmarks (the gaps are small but present), partly because the post-training recipe is far less mature than the years of RLHF poured into autoregressive models. Variable-length and open-ended generation are awkward when you sample into a fixed-size masked canvas. And “competitive with LLaMA3 8B” is the ceiling shown here, not a lead — this is a proof of viability at 8B, not yet a reason to switch production stacks.
Why it matters now
For most of the LLM era, “language model” silently meant “autoregressive transformer.” LLaDA is the strongest single data point that this is an engineering default, not a hard requirement — a non-autoregressive model can hold its own at 8B on the same benchmarks. That reopens design space the field had stopped exploring: parallel multi-token generation, native bidirectional context, and controllable infilling. The reversal-curse win is the kind of qualitative difference that justifies the detour, and it lands just as diffusion-LM follow-ups (block-wise variants, MoE diffusion LLMs) start appearing — LLaDA is the reference point they all cite.
FAQ
What is LLaDA?
LLaDA (Large Language Diffusion with mAsking) is an 8B-parameter language model that generates text by reversing a token-masking diffusion process instead of predicting the next token left to right. It was trained from scratch on 2.3 trillion tokens.
How does LLaDA compare to LLaMA3 8B?
On in-context learning it is competitive: 65.9 vs 65.4 on MMLU and 70.7 vs 53.1 on GSM8K for the base models, despite training on fewer tokens (2.3T vs 15T). The instruction-tuned LLaDA still trails LLaMA3 8B Instruct slightly on some chat benchmarks.
How does LLaDA break the reversal curse?
Its training masks tokens symmetrically with no left-to-right ordering, so predicting earlier tokens from later ones is not structurally harder. On a reversal poem-completion task LLaDA 8B Instruct scores 42.4% vs GPT-4o’s 34.3%.
Is LLaDA faster than an autoregressive model?
Not necessarily. It generates over a fixed number of denoising steps, and output quality depends on that step count, so inference cost and latency are a known weak point rather than a speedup.
Why does a diffusion language model matter?
It shows core LLM capabilities do not inherently depend on autoregressive modeling, reopening non-autoregressive design choices like parallel generation and bidirectional context at a scale people actually use.
One line: a masked-diffusion 8B model can match an autoregressive 8B and even fix the reversal curse — but pays for it at inference time. Read the original paper on arXiv.