AI Agents · Retrieval-Augmented Generation · LLM Reasoning
SearchSwarm: Delegation Intelligence for Deep Research
SearchSwarm fine-tunes Tongyi DeepResearch-30B-A3B on harness-generated delegation trajectories, lifting BrowseComp from 43.4 to 68.1 and topping every 30B-A3B model on four deep-research benchmarks.
Quick answer
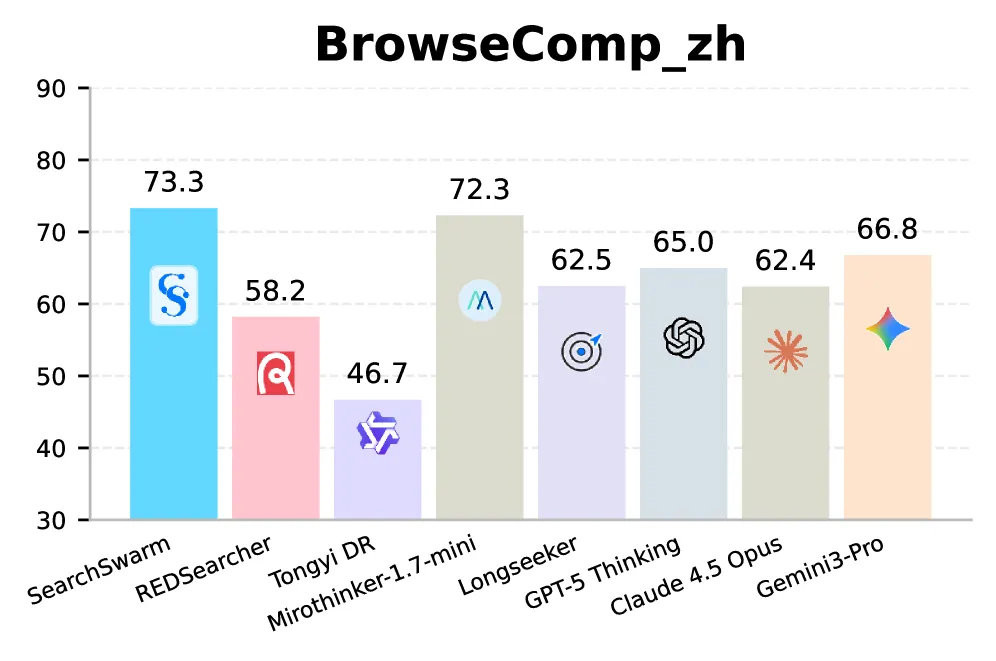
SearchSwarm is a 30B-A3B deep-research model that learns to delegate subtasks to subagents instead of doing every search itself. It scores 68.1 on BrowseComp, 73.3 on BrowseComp-ZH, 82.5 on GAIA, and 80.8 on xbench-DeepSearch, the best numbers among open-source models at the same scale. The gain is from training, not the base model: its base, Tongyi DeepResearch-30B-A3B, scores 43.4 on BrowseComp, so fine-tuning adds 24.7 points. Running the same delegation harness on the untrained base produces no change at all, because the base model never calls the subagent tool.
What delegation intelligence means here
A long deep-research task fills the context window with search results and page dumps. The usual fixes are passive: summarize history once it gets too long, or drop old tool outputs by a fixed rule. SearchSwarm uses an active alternative. A main agent decomposes the task up front, dispatches bounded subtasks to subagents through a call_sub_agent tool, and gets back only a short report. Each subagent runs in its own context, so the main agent’s window stays small while the work scales.
The paper calls the missing skill delegation intelligence: deciding when to split a task, how to scope each subtask, how to brief a subagent, and how to fold returned results back into the plan. That skill is not free. It needs training data that shows correct delegation decisions, and natural text almost never contains explicit multi-agent coordination. The paper’s core move is generating that data instead of scraping it.
How the harness and training work
The harness is a set of inference-time rules that push the main agent toward good delegation. It exposes call_sub_agent for parallel dispatch, requires the main agent to brief each subagent with both the task and the reason it matters, and forces subagents to return citations so the main agent can verify claims. The main agent keeps an independent view of overall progress and uses direct tool calls mostly to check subagent conclusions.
Running this harness produces trajectories. The team filters those trajectories down to ones that encode correct decisions about when to decompose, how to scope, and how to brief, then uses them as supervised fine-tuning data on Tongyi DeepResearch-30B-A3B. The result is a model that delegates from its own weights rather than needing the harness scaffolding to behave.
Key results
- BrowseComp: 68.1 for SearchSwarm vs 43.4 for its base Tongyi DeepResearch, a 24.7-point jump. It edges out MiroThinker-1.7-mini (67.9), the prior best 30B-A3B model.
- BrowseComp-ZH, GAIA, xbench: 73.3, 82.5, and 80.8, best in the 30B-A3B class on all three.
- Harness alone does nothing: applying the harness to the untrained base (“Tongyi DR Swarm”) never triggers
call_sub_agent, so it behaves exactly like the plain base model. Delegation has to be trained in. - Harness ablation (DeepSeek V3.2, 200-question BrowseComp subset): base framework 47.7, base plus a bare delegation tool 50.0 (+2.3), full harness 57.7 (+10.0). Most of the lift comes from the briefing and citation rules, not the tool itself.
- Open-ended generalization: on four long-form benchmarks SearchSwarm averages 64.2 vs 50.0 for its base (+14.2), despite training only on short-answer queries. ScholarQA-v2 rises 32.7 points.
- Single-agent transfer: with
call_sub_agentdisabled, SearchSwarm still beats its base on a 200-question BrowseComp subset (52.0 vs 43.5) and BrowseComp-ZH (53.3 vs 46.5), so the decomposition habit survives without the delegation tool.
How to read the comparisons
The headline 68.1 sits next to much larger models, and SearchSwarm matches DeepSeek V3.2 (671B-A37B, 67.6) and beats GPT-5.2-Thinking (65.8) on BrowseComp. Treat this as a scale-for-scale claim, not a frontier claim. SearchSwarm runs with context management (the delegation itself counts as compression), so the fair peer set is the starred, context-managed entries. On GAIA it trails Step-3.5-Flash (84.5), and on the open-ended set it sits behind Dr.Tulu (65.6). The honest reading is that a well-trained 30B-A3B can punch above its weight class on these specific benchmarks, with the gain owned by the training data and harness, not by a bigger base.
Limits and open questions
The base-model swap is the strongest evidence but also a caveat: the same data fine-tuned on Qwen3-30B-A3B-Thinking reaches 66.5 on a 200-question BrowseComp subset, which is encouraging, yet that is a subset, not the full 1266-question benchmark, so it is not directly comparable to the 68.1 headline. The paper reports no token, wall-clock, or dollar cost for running parallel subagents, so the efficiency of delegation versus a single long context is asserted rather than measured. Subagent count, search budget per subtask, and the Serper plus Jina tool stack all shape the scores, and pulling those levers could move results in either direction. Reproducibility hinges on the promised release of harness, weights, and data; without the filtering recipe, the “correct delegation trajectories” are hard to rebuild.
FAQ
What is SearchSwarm and who built it?
SearchSwarm is a 30B-A3B deep-research model from Ant Group with Tsinghua, Peking, and Renmin University collaborators. It fine-tunes Tongyi DeepResearch on synthetic delegation trajectories so a main agent learns to dispatch subtasks to subagents via a call_sub_agent tool, reaching 68.1 on BrowseComp.
Does SearchSwarm beat its base model Tongyi DeepResearch?
Yes, by a wide margin. SearchSwarm scores 68.1 on BrowseComp against 43.4 for Tongyi DeepResearch, a 24.7-point gain, and improves on every one of the four short-answer benchmarks plus the open-ended set.
Does the SearchSwarm harness work alone, without training?
No. Running the harness on the untrained Tongyi DeepResearch base never invokes the subagent tool, so it scores the same as the plain base. The delegation behavior only appears after supervised fine-tuning on the harness-generated trajectories.
Is SearchSwarm a multi-agent system or a single model?
Both, depending on the setting. At inference it runs as a main agent plus parallel subagents, but the delegation skill lives in one set of fine-tuned weights. With the subagent tool disabled, the same single model still outperforms its base, so the training transfers to a single-agent setup.
How much of the gain comes from the harness versus the model?
In the DeepSeek V3.2 ablation, adding only the bare delegation tool lifts a 200-question BrowseComp subset by 2.3 points, while the full harness adds 10.0. The briefing and citation rules carry most of the harness lift, and the fine-tuning is what makes a model use delegation at all.
One line: SearchSwarm shows that delegation intelligence can be synthesized as training data and baked into a 30B-A3B model, turning a 43.4 BrowseComp base into a 68.1 result without a bigger model. Read the original paper on arXiv.