Reinforcement Learning · Fine-Tuning & Adaptation · Interpretability
Why Multi-Domain RL Forgets, and How a Math Refresh Heals It
When you RL-tune an LLM across math, code, QA, and writing in sequence, math drops from 66.49 to 57.66 even though gradients look orthogonal. A short math refresh pulls it back to 66.04 without wrecking the other three.
Quick answer
Sequential RL post-training on an LLM degrades earlier skills, and the usual story (catastrophic forgetting, global gradient conflict) is wrong about why. This paper trains Qwen3-4B-Thinking through Math then Code then QA then Creative Writing and watches Math collapse from a peak of 66.49 down to 57.66, even though full-model gradients between domains are nearly orthogonal. The real culprit is a second-order damage term that concentrates in a small shared “conflict subspace” of the network’s active computation routes. The payoff: a short Math refresh at the end recovers Math to 66.04 while the other three domains barely move, average score rising 64.25 to 66.39.
If you do multi-domain RL and have written off interference as unavoidable forgetting, this gives you a mechanism and a cheap fix. If you only ever train one domain, you can skip it.
The orthogonal-gradient paradox
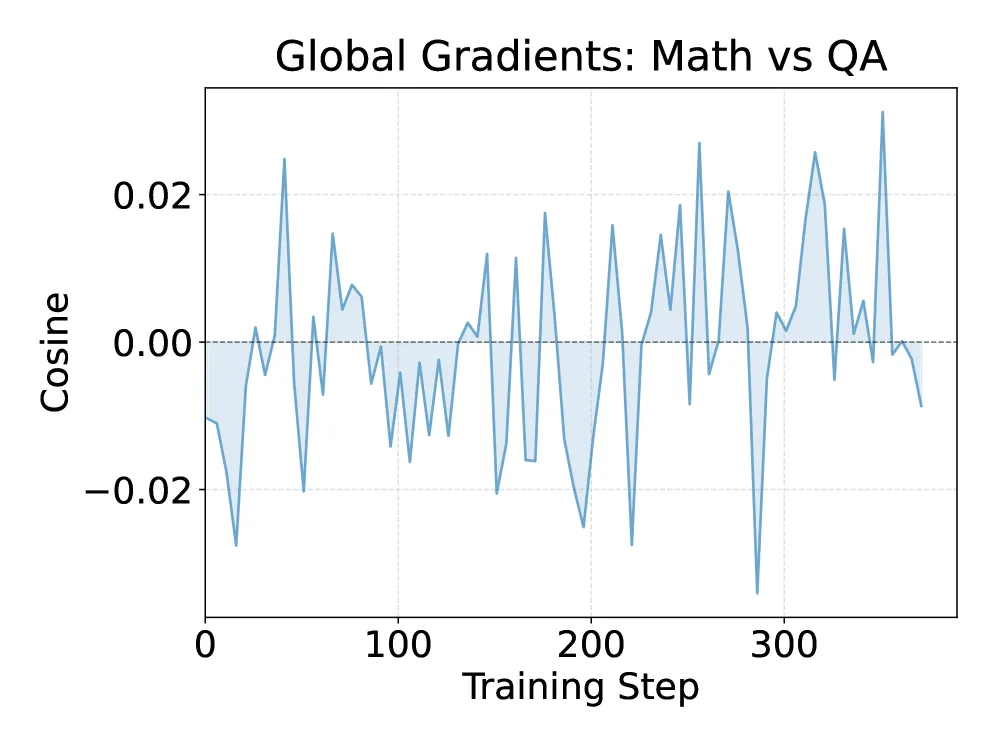
The standard intuition says two tasks conflict when their gradients point in opposing directions, so if gradients are orthogonal, training one should not hurt the other. The authors measure the global gradient cosine between Math and QA and find it sits near zero, the textbook “no conflict” condition. Yet interference is still substantial.
Figure 1 resolves the paradox by decomposing the gradient relationship by module. Globally the cosine is ~0, but at the attention and MLP level there exist a most conflicting module and a most synergistic module whose effects nearly cancel in the global average. Interference is not absent; it is hidden by aggregation. Whether two domains help or hurt each other is decided locally, on specific computation routes, not by a single full-model dot product.
What single-domain RL actually changes
Before theorizing about conflict, the paper characterizes what an RL update even does to the weights. Two empirical facts anchor everything:
- The edits are sparse and tiny. For each single-domain expert, 77% to 89% of parameters change by less than 10⁻⁷ in absolute value, and relative changes stay below 10⁻³. RL post-training is a scalpel, not a hammer.
- The changed neurons barely overlap, but the active ones do. The Jaccard overlap of top-changed neurons across any domain pair is below 0.19, so each domain edits a mostly different sparse set. But the active neurons (the routes that actually fire during inference) overlap heavily for the three reasoning domains (Math, Code, QA).
That gap is the whole point. Domains write to different places yet read through shared routes. Two updates can be sparse and almost disjoint in where they edit and still collide on a route they both depend on. Whether they act synergistically or destructively on that shared route comes down to update direction.
The local perturbation model
The theory treats later-domain training as a small perturbation around the parameters of an earlier domain. Expanding the earlier domain’s loss to second order, the first-order term is governed by the (near-orthogonal) gradients and is small, so the dominant harm is a second-order damage term built from the curvature interacting with the update direction. Under the measured sparse-route structure, this term does not spread across the whole parameter space; it concentrates in a low-dimensional shared conflict subspace spanned by the routes the domains co-activate.
This is a satisfying explanation because it reconciles the contradiction: gradients can be orthogonal (small first-order term) while damage is large (second-order term on a shared low-rank subspace). It also makes the damage addressable. If harm lives in a few dimensions, you should be able to surgically undo it.
The authors test exactly that with a conflict-subspace rollback. Rolling back just 2% of MLP neurons selected by a route-conflict criterion recovers 20.4% of lost Math (59.90 to 61.25) while QA moves only −0.06. Extending the rollback to 32% of joint MLP and attention components recovers 73.6% of the loss. Damage really is concentrated where the theory says it is.
Key results
- Sequential forgetting is real and large. Across Math to Code to QA to CW, Math runs 59.63 to 66.49 (after its own RL) to 59.90 to 57.66; Code drifts 52.67 to 50.47; CW climbs to 86.52 as the last-trained domain.
- A short Math refresh is a near-free undo. Re-running brief Math RL at the end lifts Math 57.66 to 66.04, with Code 50.47 to 51.05, QA 62.34 to 62.49, and CW 86.52 to 85.96. Average score: 64.25 to 66.39.
- Targeted rollback confirms the conflict subspace. 2% MLP-neuron rollback → 20.4% Math recovery with QA at −0.06; 32% joint rollback → 73.6% recovery. Damage is low-dimensional and localized.
- Scale of evidence. All measured on Qwen3-4B-Thinking-2507, with Qwen3-235B-A22B-Instruct-2507 as the LLM judge for creative writing.
Limits and open questions
The whole study rides on a single 4B model in one domain ordering (Math→Code→QA→CW). Whether the conflict subspace stays low-dimensional at 70B+, with more domains, or under a different curriculum is untested. The “later-domain harms earlier-domain” pattern may also behave differently when the earlier domain is creative writing rather than math. The refresh fix is also a re-exposure to data, so it sits closer to rehearsal than to a parameter-space surgery; the rollback experiments are the cleaner test of the theory but recover less. Finally, the second-order analysis assumes a small perturbation, which is honest for these tiny sparse edits but may break for aggressive RL with large policy shifts. Treat the numbers as a clean existence proof of the mechanism, not a deployment recipe.
FAQ
Why does multi-domain RL hurt earlier domains if the gradients are orthogonal?
Because orthogonal global gradients only zero out the first-order interference term. The damage in this paper is a second-order term (curvature times update direction) that concentrates in a low-dimensional subspace of computation routes the domains share. Module-level conflict and synergy cancel in the global cosine but not in the actual loss.
Does the Math refresh in this paper just retrain from scratch?
No. It is a short additional RL pass on Math after the full Math→Code→QA→CW sequence. It recovers Math from 57.66 to 66.04 while Code, QA, and CW shift by less than a point, so it behaves like selective recovery rather than full retraining or blunt rehearsal.
Can I fix interference without any extra data, using the conflict subspace directly?
Partially. Rolling back 2% of MLP neurons on the conflict subspace recovers 20.4% of lost Math, and a 32% joint MLP+attention rollback reaches 73.6%. Both are data-free, but recover less than the refresh. It is the strongest evidence the damage is localized, but not yet a complete fix on its own.