长上下文 · 高效 AI · Transformer
MiniMax Sparse Attention:百万上下文稀疏注意力
MSA 让每个查询组只看 2048 个被选中的 KV token,在 1M 上下文报告 28.4 倍注意力 FLOPs 降低、14.2 倍 prefill 加速。
快速答案
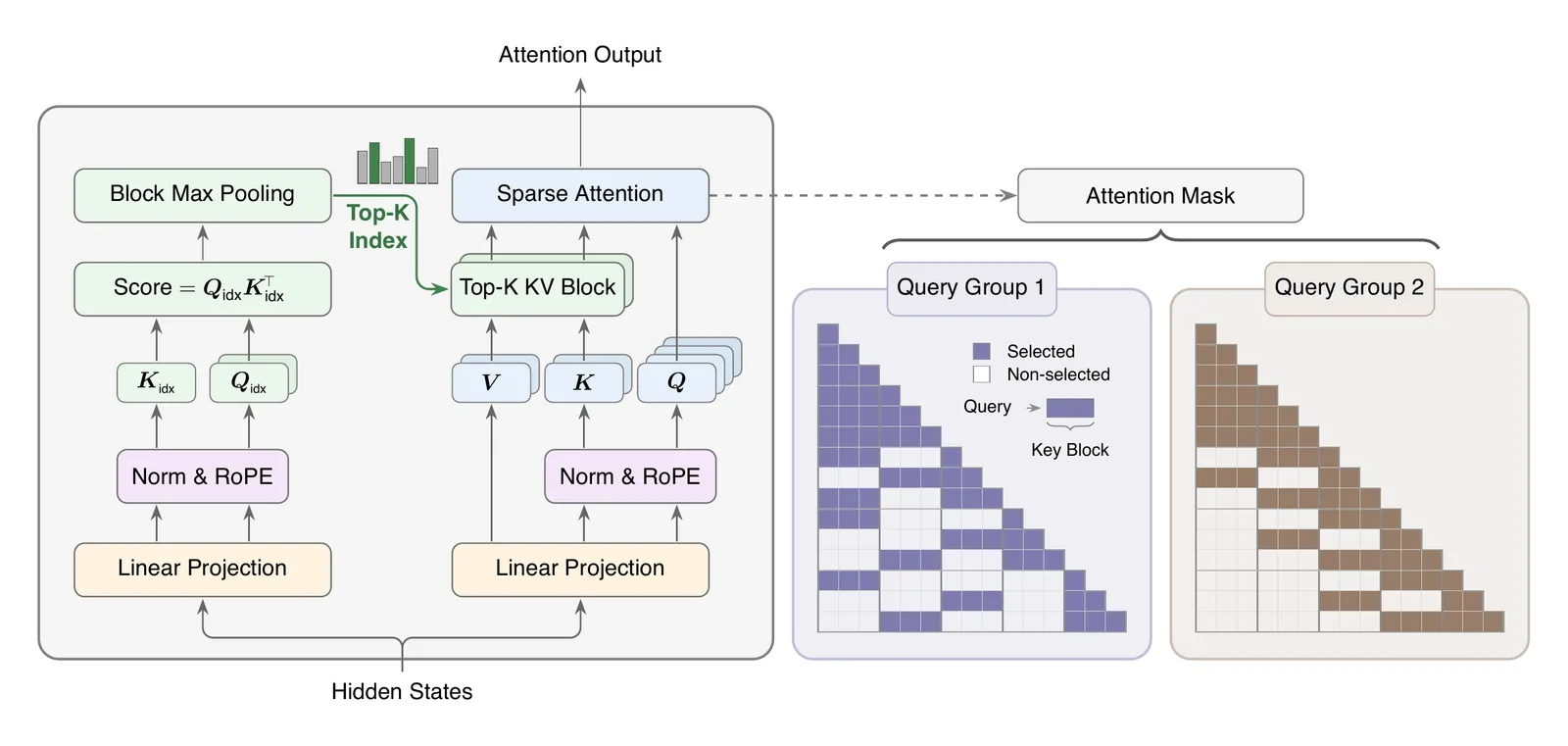
MiniMax Sparse Attention(MSA)是一套面向百万 token 上下文的稀疏注意力设计。它不是把 Transformer 换成新架构,而是在 GQA 上加一个轻量 Index Branch,为每个 query 和 GQA group 选择少量 KV block,再让 Main Branch 只在这些 block 上做精确 softmax attention。最关键数字是:在论文中的 109B 原生多模态模型上,MSA 在 1M 上下文把每 token 注意力 FLOPs 降低 28.4 倍,在 H800 上实现 14.2 倍 prefill 和 7.6 倍 decoding 墙钟加速,同时长上下文质量接近 dense GQA。
机制:保留注意力,只改进入注意力的内容
MSA 的核心不是「不要注意力」,而是「不要看全部历史」。Index Branch 会给可见 KV token 打分,聚合到 block 级别,每个 group 选 top-k block,并强制保留最近的 local block。Main Branch 仍然执行普通注意力,只是输入变成被选中的 block。
这个选择很工程化。很多高效注意力方案需要重写模型结构或接受难以部署的 kernel。MSA 尽量复用现有 GQA 和 KV cache 体系,把问题压成两个部分:路由哪些 block,以及如何让稀疏 block attention 真正在 GPU 上快起来。
训练也相对保守。Index Branch 通过 KL loss 学 Main Branch 在所选 block 上的分布,并且把 index 路径对主 attention 的梯度断开。也就是说,它学习「full attention 大概会看哪里」,但不让这个辅助路由器把主模型训练搅乱。
2048 个 KV token 是真正压力测试
论文最值得看的地方不是「稀疏更快」,而是它把预算固定得很紧:16 个 block 乘以 128 token,每个 query group 只看 2048 个 KV token。对 128K、1M 上下文来说,这是一个很小的窗口。如果质量还能保住,部署意义就比轻微稀疏更大。
结果不是完美无损,但足够有说服力。长上下文扩展后,MSA-CPT 在 HELMET-128K overall 为 45.93,full attention 为 46.53,低 0.60 点;在 RULER-128K overall 为 72.12,full attention 为 72.00,基本持平。分项有涨有跌:Rerank/RAG 低 2.10 点,MK/MQ/MV 高 2.24 点。这更像真实取舍,不是宣传式「零损失」。
关键结果
- 1M 上下文效率: 在相同 head 配置下,MSA 相比 dense GQA 报告 28.4 倍每 token 注意力 FLOPs 降低。
- 墙钟速度: H800 上配合专用 kernel,1M 上下文 prefill 加速 14.2 倍,decode 加速 7.6 倍。
- 固定预算: 每个 query group 只选 16 个 128-token block,即 2048 个 KV token。
- 通用能力: 3T token 训练预算下,MSA-PT 在 MMLU 67.2 vs full 67.0,GSM8K 77.7 vs 76.2,没有出现系统性崩塌。
- 长上下文: 140B long-context 继续训练后,MSA-CPT 在 HELMET-128K 低 0.60 点,在 RULER-128K 高 0.12 点。
对工程团队的意义
对模型团队来说,MSA-CPT 比 MSA-PT 更实际。很多团队已经有 dense checkpoint,真正需要的是把已有模型迁到稀疏注意力的路线,而不是从零重训。
对推理团队来说,要警惕 FLOPs 和延迟不是一回事。论文也承认,稀疏 attention 会引入 index 构造、top-k、query gathering、反向索引和负载均衡开销。所以 28.4 倍 FLOPs 降低不会等于 28.4 倍延迟降低。MSA 的亮点是把 kernel 一起做了,不是只写复杂度公式。
局限与存疑
MSA 的证据主要来自 MiniMax 自己的模型和 kernel 栈。论文释放了推理 kernel,但不同模型大小、不同 GPU、不同 serving 系统能否复现同样收益,仍然是工程问题。
第二个风险是证据分布。2048-token block budget 对许多长上下文任务够用,但对需要整合大量弱证据的任务可能不够。平均分接近 full attention 很好,但不能替代专门的多证据、对抗式长上下文测试。
常见问题
MiniMax Sparse Attention 方法是什么?
MSA 是一种块级稀疏注意力方法。它用轻量 Index Branch 选择关键 KV block,再让 Main Branch 只在这些 block 上做普通注意力。
MiniMax Sparse Attention 在 1M 上下文结果有多快?
论文报告 1M 上下文下每 token 注意力 FLOPs 降低 28.4 倍;在 H800 上,prefill 加速 14.2 倍,decoding 加速 7.6 倍。
MiniMax Sparse Attention 结果会损失长上下文能力吗?
在论文测试中损失很小。MSA-CPT 在 HELMET-128K overall 比 full attention 低 0.60 点,在 RULER-128K overall 高 0.12 点,但具体分项仍有波动。
MiniMax Sparse Attention 架构里的 Index Branch 为什么重要?
Index Branch 决定每个 query group 应该看哪些 KV block。没有这个路由器,稀疏模式只能是固定规则,很难同时兼顾长上下文检索和通用能力。
一句话:MSA 的价值在于把百万上下文 attention 变成 block 选择和 kernel 工程问题,而不是宣称注意力本身已经过时。阅读 arXiv 原文。