Vision-Language-Action · Robotics
Robots Need More than VLA and World Models: Four Missing Interfaces
A position paper from ETH Zurich, Stanford and TU Darmstadt argues scaling VLA and world models is not enough — robots need four interfaces to turn unstructured human and video behaviour into grounded supervision.
Quick answer
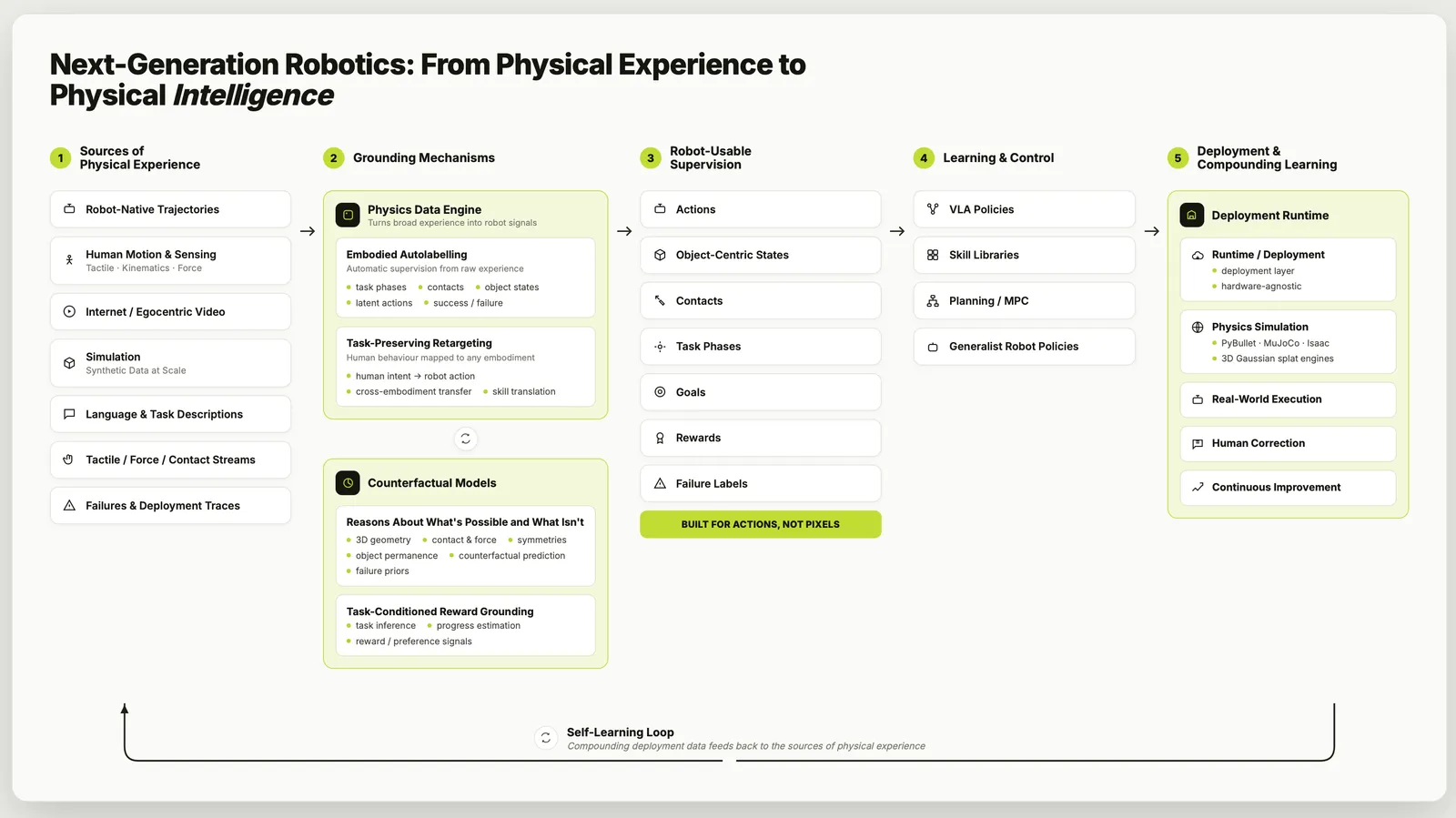
The argument is blunt: scaling Vision-Language-Action (VLA) models and stacking on world models will not produce generalist robots, because the real bottleneck is data, not policy size. The paper names four missing pieces — data, embodiment, world-model, and reward interfaces — that convert the world’s abundant but action-less behaviour data (human motion, internet video, simulation rollouts) into supervision a robot policy can actually train on. It is a research agenda, not a system, so there are no benchmark numbers; the contribution is the diagnosis and the four-interface framing.
Why “just scale VLA” hits a wall
The dominant recipe in robot learning is to collect more teleoperated robot demonstrations, train a bigger VLA model, and hope generalisation falls out — the same scaling story that worked for language. The authors’ core claim is that this analogy breaks. Language models scale on trillions of tokens of text that already carry the supervision signal. Robotics has no comparable corpus: teleoperated demonstrations are slow, expensive, and embodiment-specific, so you cannot simply 10x the dataset by scraping the web.
Meanwhile the web is full of behaviour — people cooking, assembling furniture, failing and recovering — but that footage has no robot action labels, no task boundaries, and no reward signal. A VLA model cannot ingest it directly. So the field is compute-rich and data-poor in exactly the dimension that matters, and adding a world model on top does not fix the labelling problem underneath.
The four interfaces
The paper’s spine is four “interfaces” — each a function that maps raw behaviour into something a policy can learn from:
- Data interface — autolabelling unstructured behaviour. Take raw video or rollouts and infer the task, the segmentation into steps, the contacts, and the failures, so the clip becomes a labelled trajectory rather than pixels.
- Embodiment interface — retargeting human motion to robot actions. A human hand and a parallel gripper are not the same morphology; this interface maps observed human (or other-robot) motion onto the target robot’s action space so cross-embodiment data transfers.
- World-model interface — physics-grounded 3D reasoning. Not a pixel-prediction video model, but a representation that respects contact, rigid-body dynamics and 3D geometry, so predicted rollouts are physically usable rather than plausible-looking.
- Reward interface — inferring task progress and success from video and language. Most internet behaviour has no reward; this interface reads “is the task progressing / did it succeed” out of observation, supplying the signal RL and offline methods need.
The honest reading: these are not four independent modules but four re-framings of the same goal — make non-robot data trainable. The novelty is the taxonomy and the insistence that the labelling gap, not the policy architecture, is the limiting reagent.
Key results
There are no quantitative results — this is a position paper, and pretending otherwise would misrepresent it. What it delivers instead:
- Four named interfaces (data, embodiment, world-model, reward) as a checklist for what a generalist robot data pipeline must produce.
- A survey spanning robot foundation models, cross-embodiment datasets, learning-from-video, world models, and reward modelling, organised under that taxonomy.
- A thesis sentence worth quoting: the central bottleneck is “the absence of mechanisms that convert the world’s abundant unstructured behavioural data into grounded robot supervision” — i.e. supervision, not scale.
The strength here is the author list rather than any metric: Marco Hutter (ETH Zurich), Mac Schwager (Stanford), Jan Peters (TU Darmstadt), Arash Ajoudani and Cesar Cadena are senior robotics-learning people, so the framing carries weight even without experiments.
Limits and open questions
The unavoidable limit is that nothing is demonstrated. Each interface is plausible and each is also an open research problem the paper does not solve — autolabelling, retargeting, physics-grounded world models and learned reward all have known failure modes (label noise, morphology gaps, sim-to-real, reward hacking) that the agenda lists but does not resolve. A skeptic can fairly say the four-interface split is a tidy relabelling of work the community already pursues, and the burden of proof — that wiring these interfaces together actually beats just collecting more robot data — is left entirely to future work. If you want a method to implement next week, skip it; if you want a clear map of why current robot scaling stalls, it is a useful one.
FAQ
What does “Robots Need More than VLA and World Models” actually argue?
That generalist robots are bottlenecked by data supervision, not by policy size. Scaling VLA models and adding world models leaves the core problem — turning unlabelled human and video behaviour into trainable robot supervision — unsolved, which the paper frames as four missing interfaces.
What are the four interfaces in the paper?
Data (autolabel unstructured behaviour), embodiment (retarget human motion to robot actions), world-model (physics-grounded 3D reasoning), and reward (infer task progress and success from video and language). Together they convert non-robot behaviour data into supervision a policy can use.
Does the paper beat any VLA baseline with numbers?
No. It is a position paper with a survey and a research agenda, not an empirical system, so it reports no benchmark scores. Its value is the diagnosis and taxonomy, not a state-of-the-art result.
Who wrote it and why does it matter?
Authors include Marco Hutter (ETH Zurich), Mac Schwager (Stanford), Jan Peters (TU Darmstadt) and Arash Ajoudani — senior robot-learning researchers — which is why this VLA critique is worth reading even though it ships no model.
One line: robot generalisation is a data-supervision problem, and the fix is four interfaces that make human and internet behaviour trainable — not a bigger VLA. Read the original paper on arXiv.