机器人不止需要 VLA 和世界模型:四个缺失的接口
来自 ETH、斯坦福、TU Darmstadt 与 IIT 的立场论文主张:堆大 VLA 和世界模型不够,机器人真正缺的是把无标注人类与视频行为转成可训练监督信号的四个数据接口。
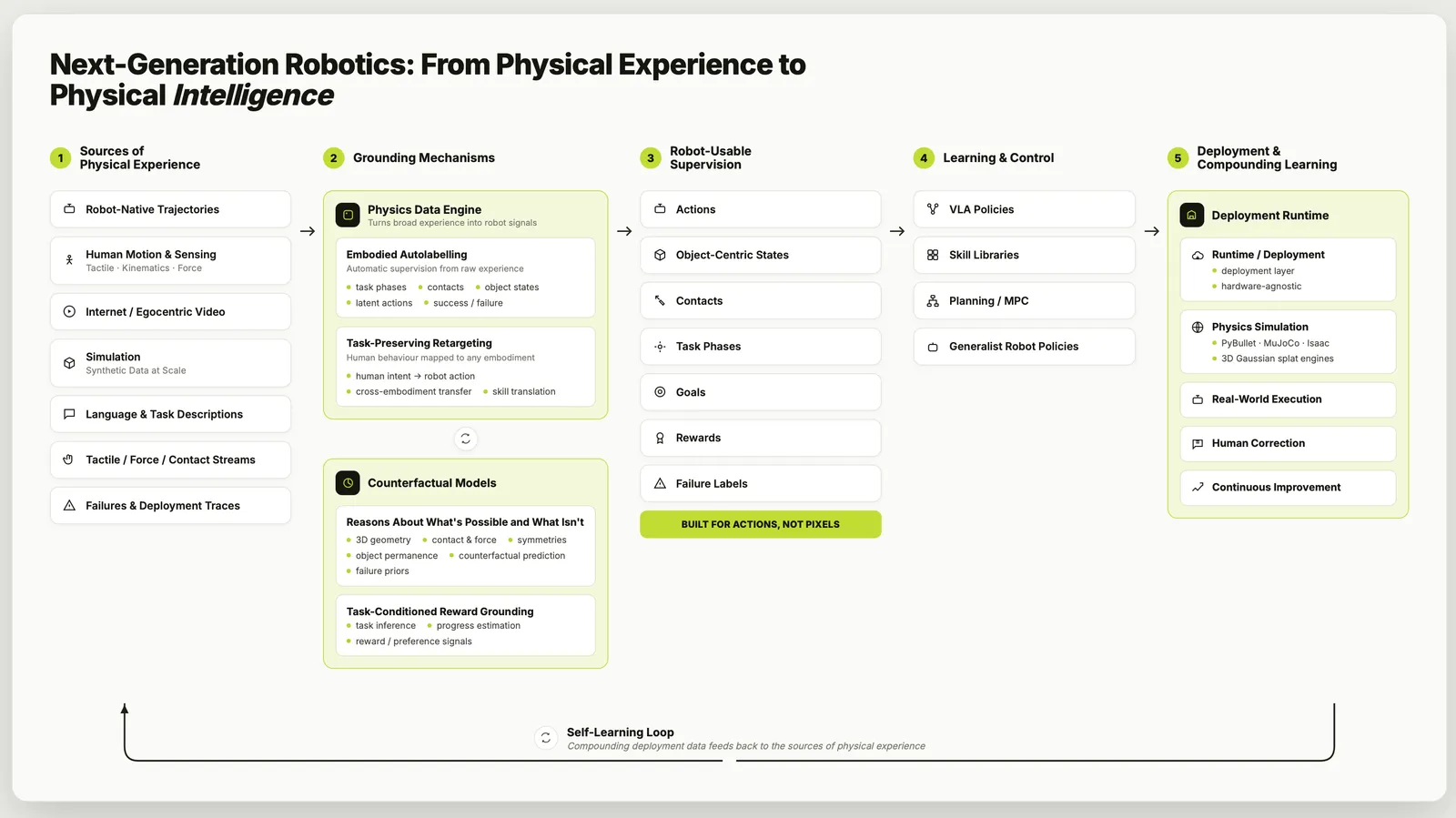
快速答案
观点很直接:只靠把视觉-语言-动作(VLA)模型做大、再叠一个世界模型,造不出通用机器人,因为真正的瓶颈是数据,不是策略规模。论文点名四个缺失件——数据接口、具身接口、世界模型接口、奖励接口——它们负责把世界上海量却没有动作标签的行为数据(人类动作、互联网视频、仿真回放)转成机器人策略真正能训练的监督信号。这是一份研究议程而非系统,所以没有基准数字;它的贡献在于诊断问题和提出这套「四接口」框架。
为什么「把 VLA 做大」会撞墙
机器人学习当下的主流配方是:采更多遥操作演示、训更大的 VLA 模型,然后指望泛化自己冒出来——这正是语言模型那套规模化故事。作者的核心主张是:这个类比不成立。语言模型能在万亿级文本上规模化,是因为文本本身就带着监督信号;而机器人没有可比的语料——遥操作演示又慢又贵、且绑死在特定本体上,你没法靠爬网页把数据集放大十倍。
与此同时,网络上确实满是行为数据:有人做饭、有人组装家具、有人失败又恢复——但这些画面没有机器人动作标签、没有任务切分、也没有奖励信号。VLA 模型无法直接吃进去。于是这个领域在最关键的维度上算力充足、数据匮乏,而在上面再加一个世界模型,也修不好底层的标注缺口。
四个接口
论文的主干是四个「接口」——每个都是把原始行为映射成策略可学之物的函数:
- 数据接口 —— 给无结构行为自动打标。把原始视频或回放转成已标注的轨迹:推断任务是什么、如何切分成步骤、哪里发生接触、哪里失败,而不是一堆像素。
- 具身接口 —— 把人类动作重定向到机器人动作。人手和平行夹爪不是同一种形态;这个接口把观察到的人类(或其它机器人)动作映射到目标机器人的动作空间,让跨本体数据能迁移。
- 世界模型接口 —— 有物理根基的 3D 推理。不是预测像素的视频模型,而是尊重接触、刚体动力学和 3D 几何的表示,让预测的回放在物理上可用,而非只是看起来像样。
- 奖励接口 —— 从视频和语言里推断任务进度与成败。大多数互联网行为没有奖励;这个接口从观察中读出「任务在推进吗 / 成功了吗」,为强化学习和离线方法供给信号。
诚实地讲:这四者并非四个独立模块,而是同一目标的四种重新表述——让非机器人数据变得可训练。真正的新意在于这套分类法,以及它的坚持:限速步是标注缺口,不是策略架构。
关键结果
没有定量结果——这是一篇立场论文,假装有数字反而是误导。它给出的是:
- 四个被命名的接口(数据、具身、世界模型、奖励),作为一份清单,界定通用机器人数据管线必须产出什么。
- 一份综述,横跨机器人基础模型、跨本体数据集、从视频学习、世界模型和奖励建模,统一挂在这套分类法之下。
- **一句值得引用的论点:**核心瓶颈是「缺少把世界上海量无结构行为数据转成有根基机器人监督信号的机制」——即缺监督,而非缺规模。
这里的分量来自作者阵容而非任何指标:Marco Hutter(ETH)、Mac Schwager(斯坦福)、Jan Peters(TU Darmstadt)、Arash Ajoudani、Cesar Cadena 都是机器人学习领域的资深研究者,所以即便没有实验,这个框架也有说服力。
局限与存疑
绕不开的局限是:什么都没被证明。每个接口听起来都合理,但每个也都是论文没解决的开放难题——自动打标、动作重定向、有物理根基的世界模型、学习型奖励,各有公认的失败模式(标签噪声、形态差异、仿真到现实、奖励黑客),议程列出了它们却没给出解法。质疑者可以合理地说:这套四接口划分,不过是把社区本就在做的工作整齐地重贴了标签;而真正需要举证的命题——把这些接口接起来是否真比多采机器人数据更强——被完全留给了未来工作。如果你想要下周就能落地的方法,可以跳过;如果你想要一张清晰的地图、看懂当前机器人规模化为何停滞,它很有用。
常见问题
《机器人不止需要 VLA 和世界模型》到底在主张什么?
主张通用机器人的瓶颈是数据监督,而非策略规模。把 VLA 做大、再加世界模型,并没有解决核心问题——把无标注的人类与视频行为转成可训练的机器人监督信号,论文把这归结为四个缺失的接口。
论文里的四个接口是什么?
数据接口(给无结构行为自动打标)、具身接口(把人类动作重定向到机器人动作)、世界模型接口(有物理根基的 3D 推理)、奖励接口(从视频和语言推断任务进度与成败)。四者合起来把非机器人行为数据转成策略可用的监督。
这篇论文有用数字打败任何 VLA 基线吗?
没有。它是一篇带综述和研究议程的立场论文,不是实证系统,所以不报告任何基准成绩。它的价值在于诊断与分类,而非刷出某个最优结果。
谁写的,为什么值得读?
作者包括 Marco Hutter(ETH)、Mac Schwager(斯坦福)、Jan Peters(TU Darmstadt)和 Arash Ajoudani 等机器人学习领域的资深研究者,这正是这篇 VLA 批评即便没发布模型也值得一读的原因。
一句话:机器人泛化是数据监督问题,解法是四个让人类与互联网行为变得可训练的接口,而不是更大的 VLA。阅读 arXiv 原文。