Vision Foundation Models · Transformers
ZipSplat: Fewer Gaussians, Better Splats
ZipSplat predicts 3D Gaussians from k-means scene tokens instead of one per pixel, hitting 24.14 PSNR on DL3DV with 249K Gaussians vs YoNoSplat's 22.01 at 1.2M, all pose-free.
Quick answer
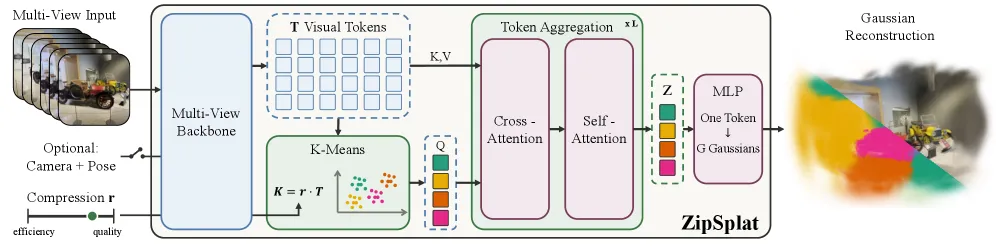
ZipSplat is a feed-forward 3D Gaussian Splatting model that decides how many Gaussians a scene needs from its content, not from how many input pixels you fed it. It clusters dense visual tokens with k-means into a small set of scene tokens, then decodes each token into a group of 32 Gaussians with free 3D positions. On DL3DV with 24 input views it reaches 24.14 PSNR using 249K Gaussians, against YoNoSplat’s 22.01 at 1.2M and DA3’s 21.69 at 6.1M. It runs pose-free: no ground-truth camera poses or intrinsics, and supplying them adds only about 0.1 dB.
Why per-pixel Gaussians waste budget
Most feed-forward splatting models emit one Gaussian per input pixel. That ties the primitive budget to image resolution and view count, not to the scene. A blank wall and a leafy tree get the same density. Add more views and the count explodes: YoNoSplat at 192 views carries 90x more primitives than ZipSplat and renders 45x slower. The redundancy is the cost, and it scales the wrong way.
ZipSplat breaks that coupling. The backbone (it works on both ViT-style VGGT and DA3-G) produces dense tokens; k-means then compresses them to K = r·T scene tokens, where r is a compression ratio you pick at inference. Flat regions collapse to a few tokens, detail-rich regions keep many. Cross- and self-attention refine the scene tokens, and a small MLP turns each into 32 Gaussians whose positions are unconstrained, so a single token’s Gaussians can spread out to cover real geometry instead of sitting on a pixel ray.
Key results
- DL3DV, 24 views, pose-free: 24.14 PSNR / 0.768 SSIM / 0.198 LPIPS at 249K Gaussians, vs YoNoSplat 22.01 / 0.710 / 0.223 at 1.2M and DA3 21.69 at 6.1M. Better on every metric with roughly 5x fewer primitives.
- Same backbone, head-to-head: swapping in ZipSplat’s token decoder for a per-pixel DA3 decoder on the identical backbone gives 1.5-2.7 dB higher PSNR with 13-25x fewer Gaussians. This isolates the decoder as the source of the gain, not a stronger backbone.
- RealEstate10K, 6 views, pose-free: 26.20 PSNR at 62K Gaussians vs YoNoSplat 24.99 at 301K. It even edges DepthSplat (24.16) which runs with ground-truth poses and 393K Gaussians.
- Zero-shot Mip-NeRF360, 128 views: 22.29 PSNR at 1.3M Gaussians vs DA3 20.19 at 32.5M, a 25x reduction on data it never trained on.
- Speed: 401 FPS rendering at 192 views (102K Gaussians), 685 FPS at 24 views; forward pass under 0.8 s and 8.1 GB at 24 views.
- Where the budget goes per token: quality saturates at 32 Gaussians per token; doubling to 64 buys only +0.03 dB for twice the budget.
What the compression ratio actually does
The compression ratio r is the interesting knob. One trained model spans the whole quality-versus-count curve by changing r at inference; the teaser plots a single ZipSplat as several red stars across that curve. At r=0.1 it already beats YoNoSplat with about 24x fewer Gaussians. There is a floor: the paper sets r_min = 0.5·sqrt(2/N) so token count keeps up with view count N, and pushing r below ~0.01 starts dropping whole scene regions. So the dial is real but bounded, and the right setting depends on how many views you feed.
Limits and open questions
Fewer Gaussians does not mean uniformly sharper. Per-pixel methods embed input colors directly into each Gaussian, which preserves high-frequency texture; ZipSplat predicts from aggregated tokens, so at sparse views it trails on LPIPS even while leading on PSNR and SSIM. The k-means allocation can also misjudge: it pours Gaussians into busy vegetation and starves flat surfaces, and it degrades on moving objects or targets with little context overlap. The ablations show the system is fragile to remove: coupled initialization is worth 0.25 dB and the geometric loss is needed just to train stably, so this is a tuned pipeline, not a drop-in decoder. The paper foregrounds primitive count and speed but says little about training data scale and cost, which matters for anyone trying to reproduce it. And several comparisons mix pose-free and pose-required baselines, so read each table for what setting it actually used before claiming a clean win.
FAQ
How does ZipSplat get 6x to 33x fewer Gaussians than pixel-aligned methods?
It stops emitting one Gaussian per pixel. K-means clusters the backbone’s dense tokens into K = r·T scene tokens, and each token decodes 32 Gaussians with free 3D positions. Because clustering follows scene content, flat regions use few tokens and detailed regions keep more. The reduction ranges from 6x at matched settings to 24x against a per-pixel decoder on the same backbone, up to 33x against YoNoSplat at comparable quality.
Does ZipSplat need camera poses or intrinsics?
No. It reconstructs and renders pose-free, with no ground-truth poses or intrinsics, and tops other pose-free baselines on DL3DV and RealEstate10K. When poses are available, feeding them as optional camera priors adds only about 0.1 dB, so the pose-free path is the headline, not a fallback.
Where does ZipSplat lose to per-pixel Gaussian splatting?
At sparse views and high-frequency texture. Per-pixel methods inject input colors straight into each Gaussian, preserving fine detail, so ZipSplat trails them on LPIPS at few views despite winning on PSNR and SSIM. Its k-means allocation also over-serves complex vegetation and under-serves flat surfaces, and quality drops on moving objects.
Is ZipSplat one model per quality level or one model for all of them?
One model. The compression ratio r is set at inference, so a single trained ZipSplat covers the whole quality-versus-Gaussian-count curve. At r=0.1 it already exceeds YoNoSplat with about 24x fewer Gaussians, and the practical floor is r_min = 0.5·sqrt(2/N) tied to the view count N.
One line: ZipSplat shows the Gaussian budget in feed-forward splatting should follow scene complexity, not pixel count, buying 6-33x fewer primitives and 45x faster rendering at higher PSNR. Read the original paper on arXiv, and for the 3D-aware vision direction see VLM3.