LLM Reasoning · Fine-Tuning & Adaptation
TrOPD: Trust-Region On-Policy Distillation for Small LLMs
TrOPD masks on-policy distillation to the tokens where the teacher is actually trustworthy, adding +3.06 to +3.52 average points over standard OPD on math, code, and STEM benchmarks with 1.5B-1.7B students.
Quick answer
TrOPD (Trust Region On-Policy Distillation) raises the average score of small student LLMs by +3.06 to +3.52 points over standard on-policy distillation across math reasoning, code generation, and general STEM benchmarks. The core move is narrow: apply on-policy distillation only on tokens where the teacher’s probability is at least the student’s, and handle the rest with a separate forward-KL term. The students are DeepSeek-Qwen2.5-1.5B and Qwen3-SFT-1.7B; teachers are Skywork-OR1-7B variants and Qwen3-Nemotron-4B.
The instability TrOPD fixes
On-policy distillation (OPD) trains a student on its own samples, scored by a teacher. The failure mode TrOPD targets is what happens when the student generates a token the teacher considers very unlikely. Reverse-KL on that token produces a large, noisy gradient that pushes the student off a cliff instead of correcting it. The further the student and teacher distributions drift apart, the worse this gets — so OPD destabilizes exactly on the hard, exploratory tokens that reasoning depends on. TrOPD’s premise is that the teacher is only a reliable supervisor on a subset of tokens, and the rest should be treated differently rather than trusted blindly.
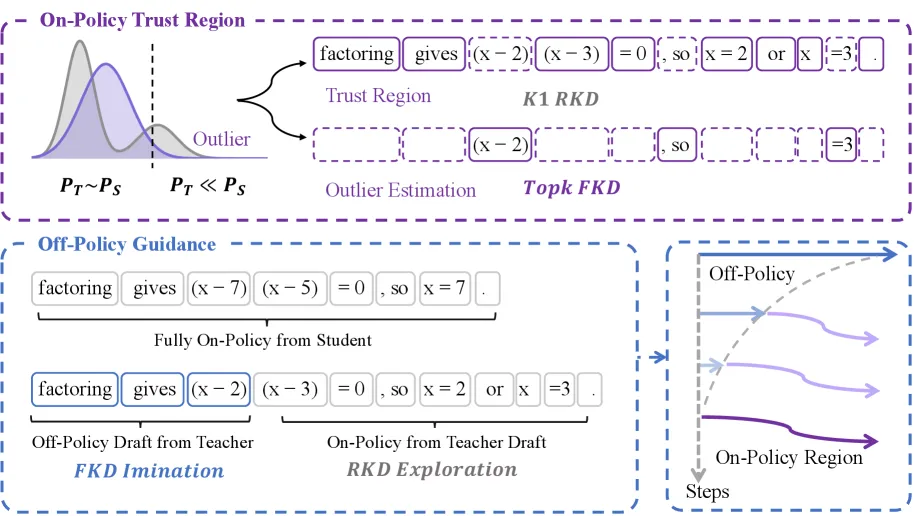
How trust-region OPD works
TrOPD splits every token into a trust region and an outlier set, using a per-token trust ratio P_trust(x) = min(teacher prob / student prob, 1).
- Trust-region on-policy learning. Standard OPD is applied only where the teacher assigns the token at least as much mass as the student does. Inside this region the teacher’s signal is reliable, so the on-policy gradient is kept.
- Outlier estimation. On tokens the teacher considers unlikely, TrOPD swaps the unstable reverse-KL gradient for a forward-KL objective over the teacher’s top-k vocabulary. This recovers a usable supervisory signal instead of either trusting a bad gradient or masking the token to zero.
- Off-policy guidance. Early in training the student also continues generation from teacher-written prefixes and imitates them with forward-KL, weighted at beta = 0.001 and annealed to zero. This seeds the student before its own rollouts are good enough to learn from.
The whole design is a credit-assignment story: decide token by token whether the teacher deserves to drive the gradient.
Key results
- Math, single-domain (Table 1). TrOPD averages 49.85 versus 46.79 for OPD — a +3.06 gain — with AIME 24 at 38.54 (vs 35.83), AIME 25 at 32.50 (vs 29.16), and AMC 23 at 78.51 (vs 75.39). REOPOLD, the strongest baseline, reaches 47.86.
- Multi-domain, DeepSeek-Qwen-1.5B (Table 3). TrOPD averages 40.63 versus OPD’s 37.11 — a +3.52 gain — across AIME 24/25, AMC 23, LiveCodeBench, and GPQA. The GPQA jump is the largest single move: 36.24 vs 28.03.
- Multi-domain, Qwen3-SFT-1.7B (Table 4). TrOPD averages 51.73 versus OPD’s 48.29 across math, STEM, instruction following, and code — a +3.44 gain.
- TrOPD beats all three reported OPD baselines: OPD, EOPD, and REOPOLD.
The consistency matters more than any single cell: the same ~3-point margin holds across three setups, two student bases, and four benchmark families, which is the kind of stability you want from a training-stability claim.
Why this matters now
On-policy distillation is becoming the default way to compress frontier reasoning behavior into deployable small models, and its biggest practical complaint is exactly this instability. TrOPD does not invent a new loss family; it adds a cheap, interpretable gate on top of OPD that says when to trust the teacher. That makes it easy to bolt onto existing pipelines, and the GPQA gain suggests the benefit shows up most on the harder out-of-distribution tokens where OPD was already weakest.
Limits and open questions
The authors name their primary limitation as the lack of practical deployment and application studies on small reasoning models — the work is post-training only, with no pre-training or mid-training stage. Beyond that: every result is on 1.5B-1.7B students with 4B-7B teachers, so it is unproven whether the ~3-point margin survives at larger student scale or a wider teacher-student gap. The trust ratio and the beta = 0.001 off-policy weight are hyperparameters that read as tuned, and there is no ablation reported here isolating how much of the gain comes from the trust mask versus the outlier forward-KL versus the off-policy warmup. Anyone whose OPD runs are already stable should expect a modest gain, not a step change. If your bottleneck is teacher quality rather than gradient noise, TrOPD does not address that.
FAQ
What is Trust Region On-Policy Distillation (TrOPD)?
TrOPD is an on-policy distillation method that applies the teacher’s gradient only on tokens where the teacher’s probability is at least the student’s, and replaces the unstable gradient on the remaining outlier tokens with a forward-KL objective over the teacher’s top-k vocabulary. It adds about 3 points of average benchmark gain over standard OPD.
How much better is TrOPD than standard OPD?
TrOPD improves average benchmark scores by +3.06 points on single-domain math, +3.52 points on multi-domain with a DeepSeek-Qwen-1.5B student, and +3.44 points with a Qwen3-SFT-1.7B student. It outperforms OPD, EOPD, and REOPOLD across math, code, and STEM benchmarks.
What models does TrOPD use as student and teacher?
The students are DeepSeek-Qwen2.5-1.5B and Qwen3-SFT-1.7B. The teachers are Skywork-OR1-Math-7B, Skywork-OR1-7B, and Qwen3-Nemotron-4B. All experiments are post-training only on these small students.
What are the limits of TrOPD?
TrOPD is validated only on 1.5B-1.7B students with 4B-7B teachers and is post-training only, with no deployment study. The authors flag the lack of practical deployment and application studies as the primary limitation, and the ~3-point margin is unproven at larger scale.
One line: trust the teacher only where it earns it, and on-policy distillation stops blowing up on hard tokens. Read the original paper on arXiv.