Reinforcement Learning · Language Models · LLM Reasoning
DRPO: Rethinking Divergence Regularization in LLM RL
DRPO swaps DPPO's hard divergence mask for a smooth advantage-weighted quadratic regularizer, keeping the Binary-TV trust region but with bounded gradient weights, and trains Qwen3 LLMs more stably under FP8.
Quick answer
DRPO is an RL fine-tuning objective for LLMs that replaces DPPO’s hard divergence mask with a smooth advantage-weighted quadratic regularizer. It keeps the same Binary-TV trust region as DPPO, defined by the sampled token’s absolute probability shift, but produces a continuous gradient weight instead of an on/off cutoff. The weight decays to zero at the boundary when an update pushes away from the behavior policy, then turns corrective beyond it, and amplifies updates that move back toward the behavior policy. Because the weight tracks absolute probability shift, it stays bounded even on rare tokens, where SPO’s ratio-based weight can blow up. The paper reports that DRPO matches or beats GRPO, SPO, DPPO, and an unregularized surrogate across six training settings, and is most useful when low-precision FP8 makes training unstable.
The problem: ratio clipping is a bad proxy for divergence
LLM RL is usually off-policy. Rollouts come from an inference engine whose numerics differ from the training engine, and trajectories get split across mini-batches, so the policy being updated is not the one that generated the data. PPO and GRPO control this drift with ratio clipping on the per-token importance ratio. The paper’s argument, following DPPO and Qi et al., is that the importance ratio is a weak proxy for actual distributional shift in long-tailed vocabularies. On a rare token, a small absolute probability change produces a large ratio change, so a ratio-based trust region overreacts to noise on the tail and underreacts where it matters.
DPPO already fixed the proxy by replacing ratio clipping with a divergence-based mask: it bounds the sampled token’s Binary-TV shift, the absolute probability difference between the current and behavior policy collapsed to a Bernoulli over that token. DRPO keeps that geometry and attacks the next problem: DPPO still uses a hard mask.
What the hard mask gets wrong and what the smooth regularizer fixes
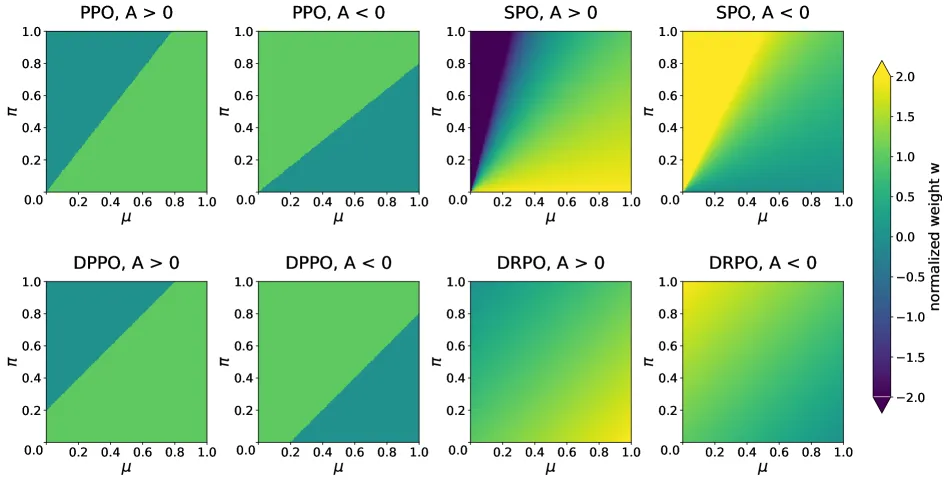
DPPO’s mask zeros a token’s gradient once it crosses the trust-region boundary in a harmful direction. That makes training brittle near the boundary, because a small change in the estimated divergence can flip a token from full-strength gradient to zero. Past the boundary there is no signal at all telling the policy to come back.
DRPO borrows the idea from SPO: enforce the same boundary with a smooth quadratic penalty instead of a discontinuous cutoff. The result is a per-token gradient weight that varies continuously with both the size and the direction of the probability shift. Inside the boundary the gradient is attenuated as the shift approaches the threshold. At the boundary the weight is zero, which matches DPPO’s stationary point under the same threshold. Outside the boundary the weight goes negative, so the gradient reverses and pulls the policy back. When an update moves toward the behavior policy, the weight is amplified rather than suppressed.
The novel part over SPO is the denominator. SPO’s penalty is an advantage-weighted Pearson chi-square that scales each squared shift by 1 over the behavior probability, so it is dominated by the low-probability tail. DRPO penalizes the absolute probability shift directly, an advantage-weighted squared L2 distance that is symmetric in the current and behavior policy. Because Binary-TV is bounded in [0,1], DRPO’s gradient weight is bounded everywhere and its variance is at most one quarter. SPO’s weight grows without bound along the low-probability axis.
Why the long tail matters
The tail is not a rounding error here. Figure 2 reports that tokens with behavior probability at or below 0.01 make up 7.8% of all sampled tokens on Qwen3-30B-A3B-Base. On those tokens a modest absolute shift produces a large ratio change, so SPO’s ratio weight can dominate the gradient while contributing little to the real distributional shift. DRPO’s bounded weight is the direct response to that regime.
Key results
- Six settings, all stable: Across Qwen3-4B-Base, Qwen3-30B-A3B-Base (BF16, FP8-rollout, FP8-E2E), Qwen3.5-35B-A3B-Base, and DeepSeek-R1-Distill-Qwen-1.5B, DRPO matches or exceeds the best AIME24/AIME25 accuracy of every baseline.
- Ratio methods collapse under FP8: GRPO and SPO often collapse before reaching reasonable accuracy in low-precision settings, where FP8 plus the MoE architecture widens the train-inference mismatch.
- Hard masks lag smooth ones: DPPO trains stably on Qwen3-30B-A3B-Base but converges slower and lands lower than DRPO, the paper’s evidence that a smooth signal beats a brittle cutoff.
- A trust region is still needed: The unregularized surrogate drops in three of six settings, most sharply on Qwen3-4B-Base where accuracy falls from 0.25 to 0.17.
- The corrective signal carries the gain: Mask-DRPO, which uses DPPO’s gradient inside the boundary and DRPO’s only outside, matches full DRPO. So most of the benefit comes from the smooth correction beyond the trust region, not from reshaping gradients inside it.
- Advantage weighting is load-bearing: Removing the absolute-advantage factor from both SPO and DRPO causes a consistent drop and destabilizes training, because that factor keeps the trust-region boundary independent of reward scale.
Limits and open questions
The headline metrics are AIME24/AIME25 average accuracy summarized as curves in Figure 3, not a per-setting numeric table in the main text, so the reported edge over DPPO is described as matching or exceeding rather than a single quoted gap. There is no compute or wall-clock accounting, so the efficiency claim rests on faster convergence in the plots. The benchmarks are math-only with rule-based verification on a filtered DAPO subset of about 13K problems, so generalization to code, agentic, or open-ended RLHF tasks is untested. DRPO and DPPO share a threshold for an apples-to-apples boundary, but DRPO introduces its own regularization threshold (set to 12.5) whose sensitivity is pushed to the appendix. The strongest framing is a stability and convergence win in hard precision regimes, not a large accuracy jump on top of an already strong RL recipe.
Builder takeaway
If you train LLMs with RL in FP8 or on MoE models and you see GRPO or SPO collapse, DRPO is cheap to try: it is a drop-in change to the per-token gradient weight, not a new rollout pipeline. The mechanism to internalize is the gradient-centered view. A regularizer that looks fine as a KL or TV objective can still induce ratio-based geometry through its gradient, and that geometry is what blows up on the tail. Judge a regularizer by the per-token weight it produces, not by the divergence name on the objective. If you already train in BF16 on dense models and never see instability, the upside is smaller.
FAQ
What is DRPO (Divergence Regularized Policy Optimization)?
DRPO is an RL fine-tuning objective for LLMs from Tencent Hunyuan, UIUC, and NUS, released with the UniRL repository. It replaces DPPO’s hard divergence mask with a smooth advantage-weighted quadratic regularizer on the sampled token’s absolute probability shift. It keeps DPPO’s Binary-TV trust region but produces bounded, continuous gradient weights that attenuate updates inside the boundary and correct them outside.
What is the difference between DRPO’s smooth regularizer and DPPO’s hard mask gradient?
DPPO zeros a token’s gradient once it crosses the trust-region boundary in a harmful direction, which is brittle near the boundary and gives no signal beyond it. DRPO replaces that cutoff with a continuous weight: it decays to zero at the boundary, reverses to a corrective signal outside it, and amplifies updates that move back toward the behavior policy. The Mask-DRPO ablation shows the gain comes mainly from that corrective signal outside the trust region.
In DRPO, why is ratio-based clipping a poor proxy for distributional shift?
In long-tailed LLM vocabularies, a small absolute probability change on a rare token produces a large importance-ratio change. So a ratio-based trust region overreacts to tail noise. The paper measures 7.8% of sampled tokens at behavior probability at or below 0.01, where SPO’s ratio weight 1 over mu can dominate the gradient. DRPO penalizes absolute probability shift instead, which is bounded in [0,1] with variance at most one quarter.
In the DRPO results, does it raise accuracy or only training stability?
Mostly stability and convergence. Its clearest win is that GRPO and SPO collapse under FP8 while DRPO keeps training, and that DPPO converges slower and lower. Final AIME24/AIME25 accuracy is reported as matching or exceeding baselines across six settings rather than as a fixed numeric jump, and there is no compute accounting, so the contribution reads as a steadier trust region rather than a capability leap.
One line: DRPO turns DPPO’s on/off divergence mask into a smooth, bounded gradient weight, buying more stable LLM RL on the long tail and under FP8, with gains shown as faster convergence rather than a quoted accuracy gap. Read the original paper on arXiv.