X-Stream: Why MLLMs Score ~50% on Multi-Stream Video
X-Stream is the first benchmark for watching several live video streams at once. The best model, Gemini 3 Pro, hits 49.6% versus a 91.84% human baseline, and proactive ability collapses below 21%.
Quick answer
X-Stream asks a question nobody had benchmarked before: can a multi-modal large language model (MLLM) watch several live video streams at the same time and reason across them? The answer is a clear no. On 4,220 curated QA pairs spanning 932 videos, the strongest model, Gemini 3 Pro, reaches only 49.60% overall, while human annotators hit 91.84%. Every open-source model lands in the 6–34% range. The headline framing from the abstract (“about 50% score”) is generous. That 50% belongs to one proprietary model, and the rest of the field is far worse.
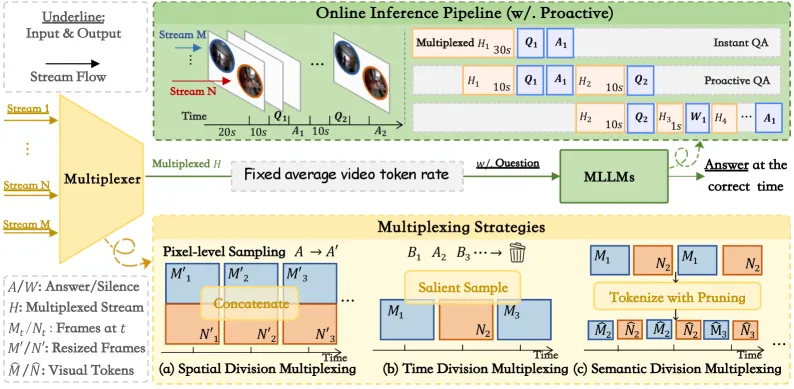
The paper makes two contributions. One is a benchmark that is genuinely hard to cheat. The other is a clean conceptual lens: treating an MLLM as a multiplexer, the signal-processing component that packs multiple channels into one pipe. That framing turns a vague “models are bad at multitasking” complaint into three concrete, testable strategies.
Why multi-stream is a different problem
Single-stream video understanding has matured: ask one question about one clip, and modern MLLMs do fine. But the real applications the authors care about feed the model concurrent streams that must be fused online: live sports with multiple camera angles, autonomous driving with front and rear views, multi-screen collaboration, split-screen game streaming. Existing benchmarks never test this. A model that aces single-stream video can still be unable to say which of two camera feeds shows the event that caused something in the other.
X-Stream organizes its scenarios into three families: multi-window (split-screen gaming, streamer reaction shots), multi-view (front/rear driving cameras, ego/exo perspectives), and multi-device (street view plus a map, dashboard plus a road camera). Tasks climb three rungs of difficulty. There are five foundational tasks (visual/audio/temporal grounding, counting, saliency), five logical-cognition tasks (3D spatial, counterfactual, causal, commonsense reasoning, anomaly detection), and one agency task (behavior planning and decision-making), 11 subtasks in all.
How the multiplexing lens works
Borrowing from Signal Multiplexing Theory, the authors test three ways to cram N video streams into a single MLLM context:
- Spatial Division Multiplexing: concatenate frames at the pixel level (think picture-in-picture). It preserves temporal modeling best and excels at cross-stream referencing.
- Time Division Multiplexing: feed streams sequentially with shared temporal embeddings. It works best for two-stream cases.
- Semantic Division Multiplexing: keep only the k most salient tokens via a DPP (determinantal point process) kernel. Under tight token budgets, it wins once you reach three or more streams.
The honest finding is that no single strategy is universally optimal. Which one wins depends on token bandwidth and how many streams you are juggling. That is a more useful result than a single “best method” claim, because it tells engineers the trade-off is structural, not a tuning detail.
Inside the benchmark
The piece that makes X-Stream credible is its dual-verification pipeline. A naive multi-stream QA set is easy to game: a question that says “across both feeds” can often be answered from one feed alone. The authors apply two checks to filter out shortcut questions: sufficiency (the answer must be derivable from the intended streams) and necessity (it must NOT be derivable from a single stream). This is the kind of construction detail that separates a real benchmark from a leaderboard that quietly rewards single-stream priors.
Key results
- Gemini 3 Pro: 49.60% overall, the top score, still 42 points below humans (91.84%).
- GPT-5: 27.78%; GPT-4o: 22.46%. The generational jump exists but is modest given the gap to human performance.
- Best open-source: Qwen3-Omni-30B-A3B at 34.28%, with Qwen3-VL-30B close at 34.19%.
- Dedicated streaming models do worst: Dispider 15.44%, VideoLLM-online-8B 8.48%, MMDuet2 6.79%. Purpose-built online video models are not ready for concurrency.
- Proactive (“forward”) ability is the real failure: most models score under 21%, meaning they rarely speak up at the right moment without being prompted.
- Hardest subtasks: decision-making and causal reasoning are the “most formidable bottlenecks”. Even Gemini 3 Pro only reaches 41.79% on causal reasoning and 44.18% on decision-making, versus 66.72% on the easier visual grounding.
Limits and open questions
The authors are candid about the ceiling. Public video lacks the precision you would get with professional multi-camera rigs, so some scenarios are approximations rather than ground truth. Audio multiplexing is still rudimentary: the strategies are tuned for visual streams, and sound is handled with simple techniques. The multiplexing strategies also struggle to balance video comprehension against temporal reasoning, since the method that sees the most detail is not the one that tracks time best.
A skeptic’s note: X-Stream is a diagnosis, not a fix. The three multiplexing strategies are evaluation harnesses, not a trained model that closes the gap. And LLM-as-judge scoring (Spearman correlation 0.62 with human raters, p < 0.05) is moderate, not airtight, so small differences between mid-pack models should be read loosely. If you only build single-stream applications, this benchmark does not change your roadmap yet.
FAQ
What is X-Stream and what does it benchmark?
X-Stream is the first benchmark for multi-stream streaming video understanding. It tests whether MLLMs can watch and reason across several concurrent video feeds online. It has 4,220 QA pairs over 932 videos, 11 subtasks, and three scenario types (multi-window, multi-view, multi-device).
How well do GPT-5 and Gemini 3 Pro do on X-Stream?
Gemini 3 Pro leads at 49.60% overall and GPT-5 reaches 27.78%, both far below the 91.84% human baseline. Proactive ability is worse: most models score under 21%, showing they struggle to react at the right moment across streams.
What does “MLLM as a multiplexer” mean in X-Stream?
It treats the model like a signal multiplexer that must pack multiple streams into one context. The paper tests three strategies (spatial, time, and semantic division multiplexing) and finds none is best everywhere. The winner depends on token budget and stream count.