X-Stream:多路视频流为何让 MLLM 只拿 50 分
X-Stream 是首个多路并发视频流理解基准。最强的 Gemini 3 Pro 仅 49.6%,人类却有 91.84%,主动反应能力更跌破 21%。
快速答案
X-Stream 提出了一个此前没人系统评测过的问题:多模态大模型(MLLM)能不能同时看好几路实时视频流,并在它们之间做跨流推理?答案很干脆:不能。在覆盖 932 段视频、4220 道精选 QA 的测试上,最强的 Gemini 3 Pro 总分只有 49.60%,而人类标注者拿到 91.84%。所有开源模型都落在 6%–34% 区间。
需要说一句实话:摘要里”约 50 分”的说法偏乐观,那 50 分只属于一个闭源旗舰,其余模型差得远。这篇论文真正的价值有两点。一是一个难以作弊的基准。二是一个干净的概念视角:把 MLLM 当作多路复用器(multiplexer),也就是信号处理里把多条信道塞进一根管道的那个部件。这个比喻把”模型不擅长一心多用”的模糊抱怨,变成了三种可量化、可对比的具体策略。
多路流为什么是另一类难题
单路视频理解已经成熟:给一段视频问一个问题,现代 MLLM 表现不错。但作者关心的真实场景都要求模型在线融合多路并发流:多机位直播体育、前后视角的自动驾驶、多屏协作、分屏游戏直播。现有基准从不测这一点。一个在单路视频上拿满分的模型,仍可能说不出”两路摄像头里,是哪一路的事件导致了另一路的结果”。
X-Stream 把场景分成三类:多窗口(分屏游戏、主播反应镜头)、多视角(前后行车记录、第一/第三人称视角)、多设备(街景加地图、仪表盘加路面摄像头)。任务难度分三级:5 个基础任务(视觉/音频/时序定位、计数、显著性)、5 个逻辑认知任务(3D 空间、反事实、因果、常识推理、异常检测),以及 1 个主动决策任务(行为规划与决策),共 11 个子任务。
复用视角是怎么工作的
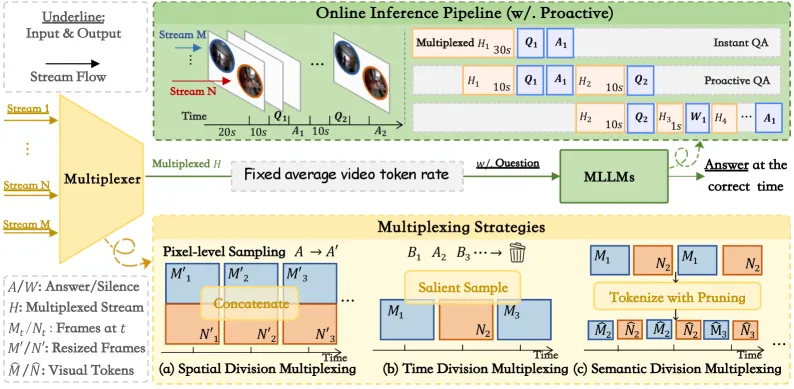
借鉴信号复用理论,作者测试了把 N 路视频塞进单个 MLLM 上下文的三种方式:
- 空分复用(Spatial Division):在像素层拼接画面(类似画中画)。它最能保留时序建模,跨流指代也最强。
- 时分复用(Time Division):用共享时序嵌入按顺序喂入各路流。它在双流场景下最优。
- 语分复用(Semantic Division):用 DPP(行列式点过程)核只保留 k 个最显著的 token。在 token 预算紧张、且流数达到 3 路以上时,它胜出。
一个诚实的结论:没有任何一种策略是放之四海皆准的最优解。哪种胜出,取决于 token 带宽和并发流的数量。这个结果比单纯宣称”我们的方法最好”更有用。它告诉工程师,这种取舍是结构性的,不是调参能抹平的。
基准内部:为什么难作弊
让 X-Stream 站得住脚的关键,是它的双重验证流水线。朴素的多流 QA 很容易被钻空子:一个写着”综合两路画面”的问题,往往单看一路就能答上来。作者用两道检查来过滤捷径题:充分性(答案必须能从目标流推出)和必要性(答案绝不能仅凭单路推出)。正是这种构造细节,把真正的基准和那些悄悄奖励”单流先验”的排行榜区分开来。
关键结果
- Gemini 3 Pro 总分 49.60%,全场最高,但仍比人类(91.84%)低 42 个百分点。
- GPT-5 27.78%,GPT-4o 22.46%:代际提升存在,但相对人类差距而言相当有限。
- 最强开源是 Qwen3-Omni-30B-A3B,34.28%,Qwen3-VL-30B 紧随其后(34.19%)。
- 专用流式模型反而最差:Dispider 15.44%、VideoLLM-online-8B 8.48%、MMDuet2 仅 6.79%。为在线视频量身打造的模型,并没准备好应对并发。
- 主动反应能力是真正的短板:多数模型在”主动(forward)“项上低于 21%,说明它们几乎不会在正确时机不被催促就开口。
- 最难的子任务是决策与因果推理,被称为”最棘手的瓶颈”:即便 Gemini 3 Pro,因果推理也只有 41.79%、决策 44.18%,而较简单的视觉定位有 66.72%。
局限与存疑
作者对天花板很坦诚。公开视频缺乏专业多机位设备那样的精度,所以部分场景是近似而非真值。音频复用仍很初级:策略主要为视觉流调优,声音只用简单手段处理。复用策略还难以在视频理解与时序推理之间取得平衡,看得最细的方法,未必是最会跟踪时间的方法。
一句怀疑者的提醒:X-Stream 是一份诊断书,不是解药。三种复用策略是评测脚手架,不是一个能补上差距的训练好的模型。而且 LLM-as-judge 打分与人类的 Spearman 相关只有 0.62(p < 0.05),属中等而非铁板钉钉,所以中游模型之间的小差距要松着看。如果你只做单路流应用,这个基准暂时还改变不了你的路线图。
常见问题
X-Stream 到底测的是什么?
X-Stream 是首个面向多路并发视频流理解的基准,测试 MLLM 能否在线观看并跨多路视频流做推理。它包含 4220 道 QA、932 段视频、11 个子任务和三类场景(多窗口、多视角、多设备)。
GPT-5 和 Gemini 3 Pro 在 X-Stream 上表现如何?
Gemini 3 Pro 以 49.60% 领先,GPT-5 为 27.78%,都远低于 91.84% 的人类基线。主动反应能力更差:多数模型低于 21%,说明它们很难在跨流的正确时机做出反应。
“把 MLLM 当多路复用器”是什么意思?
就是把模型看作信号复用器,必须把多路流打包进一个上下文。论文测试了空分、时分、语分三种复用策略,发现没有一种处处最优。胜出者取决于 token 预算和流数。