SU-01:30B 开源模型如何拿下金牌级奥赛推理
上海 AI 实验室的 30B-A3B 开源模型 SU-01,仅用约 33.8 万条短 SFT 轨迹加 200 步两阶段 RL,就在 IMO 2025 拿到 35 分金牌线。
快速答案
上海 AI 实验室的 30B-A3B 开源模型 SU-01,用一套刻意求简的配方,在数学与物理奥赛上同时拿到金牌级成绩。它在 IMO 2025 上得 35 分(正好是金牌线),USAMO 2026 超金牌线 10 分;配合测试时扩展(test-time scaling),在 IPhO 2024(25.3 对 20.8)和 IPhO 2025(21.7 对 19.7)都越过金牌门槛。按前沿标准看,它的训练管线很小:约 33.8 万条每条不到 8K token 的监督轨迹,加上仅 200 步的两阶段强化学习。
「简单统一」才是真正的卖点
真正的看点不是「模型拿了金牌」——闭源大厂早就做到了——而是不靠繁复的、分模态的复杂堆叠也能到这一步。SU-01 用一个底座(P1-30B-A3B)、一个 SFT 阶段、一条 RL 管线,同时覆盖数学和物理这两个通常要分开处理的领域。诚实地说:它的贡献是工程上的克制,而非新算法。这里没有新的 RL 目标函数;论文的价值在于证明一套干净、可复现的扩展配方,在 30B 级开源模型上能走多远。
SFT 数据里装了什么
监督阶段用了约 33.8 万条轨迹,但配比比数量更关键。按论文自己的拆分,它分成直接生成数据(54.3%,含数学、STEM、代码、指令遵循)和自我提升数据(45.7%,由自我验证、自我修正的轨迹组成)。关键在于:保留的每条回答都短于 8K token。这个约束是有意思的设计——SFT 不去模仿冗长的思维链,而是教紧凑的推理与自我纠错,把「长思考」留给 RL 去长出来。
两阶段 RL 管线
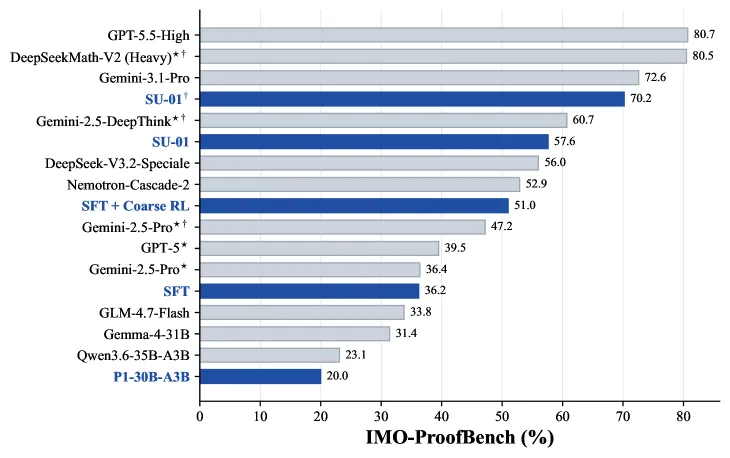
RL 一共跑 200 步,拆成 96 步粗训和 104 步精训。粗训阶段在宽泛数据上扩展推理,精训阶段在更难、更精挑的题目上收紧行为。收益在消融里看得很清楚:纯 SFT 在 IMO-ProofBench 上得 36.2%,SFT 加粗训 RL 跳到 51.0%,完整的 SU-01 直接生成达 57.6%——配测试时扩展达 70.2%。模型在推理时能把轨迹长度推过 10 万 token,这正是测试时扩展增益的来源。
关键结果
- IMO 2025: 35 分,恰好踩在金牌线上。
- USAMO 2026: 35 分,超金牌线 10 分。
- IPhO 2024: 配测试时扩展 25.3 分,高于 20.8 的金牌线。
- IPhO 2025: 配测试时扩展 21.7 分,高于 19.7 的金牌线。
- AIME 2025 / 2026: 94.6% / 93.3%。
- IMO-ProofBench: 直接 57.6%,测试时扩展 70.2%——在 x3 图里,这个 70.2 与 Gemini-3.1-Pro(72.6)同档,且领先多个前沿系统。
- AMO-Bench: 59.8%;AnswerBench: 77.5%;FrontierScience-Olympiad: 总分 62.5%。
为什么现在重要
这个结果落在「金牌级推理是否非前沿级闭源大模型不可」的争论之中。SU-01 给出的答案是「不必」:一个 30B-A3B 底座、约 33.8 万条短轨迹、200 步 RL,就够到了前不久还属于最大闭源系统的金牌线。对预算有限、想自建推理模型的人,最有用的一点是数据设计——短 SFT 轨迹加自我验证/自我修正数据,长度靠 RL 挣出来,而不是在 SFT 里照抄。
局限与存疑
金牌线的说法建立在少量竞赛题目上,方差是真实存在的——IPhO 成绩只有配测试时扩展才越线,直接生成并不达标,且 IPhO 2025 的余量(21.7 对 19.7)很薄。「金牌级」描述的是这几场特定考试上的分数门槛,并不保证能扛住更难或风格迥异的题。论文还重度依赖一个证明评分基准(IMO-ProofBench),而自动证明打分本身就有争议。最后,「简单统一」是相对的:10 万 token 轨迹和测试时扩展让推理很贵,所以「训练便宜」并不自动等于「部署便宜」。
常见问题
SU-01 是什么,谁做的?
SU-01 是上海 AI 实验室(与香港中文大学、清华、上海交大、北大合作)推出的 30B-A3B 推理模型,在 P1-30B-A3B 底座上用简单的「先 SFT 后 RL」配方,在数学与物理奥赛达到金牌级成绩。
SU-01 是怎么做到金牌级奥赛推理的?
SU-01 先在约 33.8 万条不到 8K token 的监督轨迹上微调,再跑 200 步两阶段 RL(96 步粗训 + 104 步精训),并用能把轨迹拉过 10 万 token 的测试时扩展。这套组合把 IMO-ProofBench 从 36.2%(纯 SFT)抬到直接 57.6%。
SU-01 在 IMO 2025 和 IPhO 上得多少分?
SU-01 在 IMO 2025 得 35 分(金牌线),配测试时扩展在 IPhO 2024(25.3 对 20.8)和 IPhO 2025(21.7 对 19.7)越过金牌门槛,AIME 2025 与 2026 分别为 94.6% 和 93.3%。
SU-01 比前沿推理模型更省吗?
训练上更省:约 33.8 万条短轨迹、仅 200 步 RL,相对前沿管线相当克制。但推理不省——它最强的成绩要靠 10 万 token 以上轨迹的测试时扩展,因此服务成本依然高。
一句话:30B 开源模型上一套干净的「SFT 后 RL」配方就够拿金牌级奥赛分——前提是你付得起 10 万 token 的推理。阅读 arXiv 原文。