把成对重排当主动学习:更省调用的 PRP 重排器
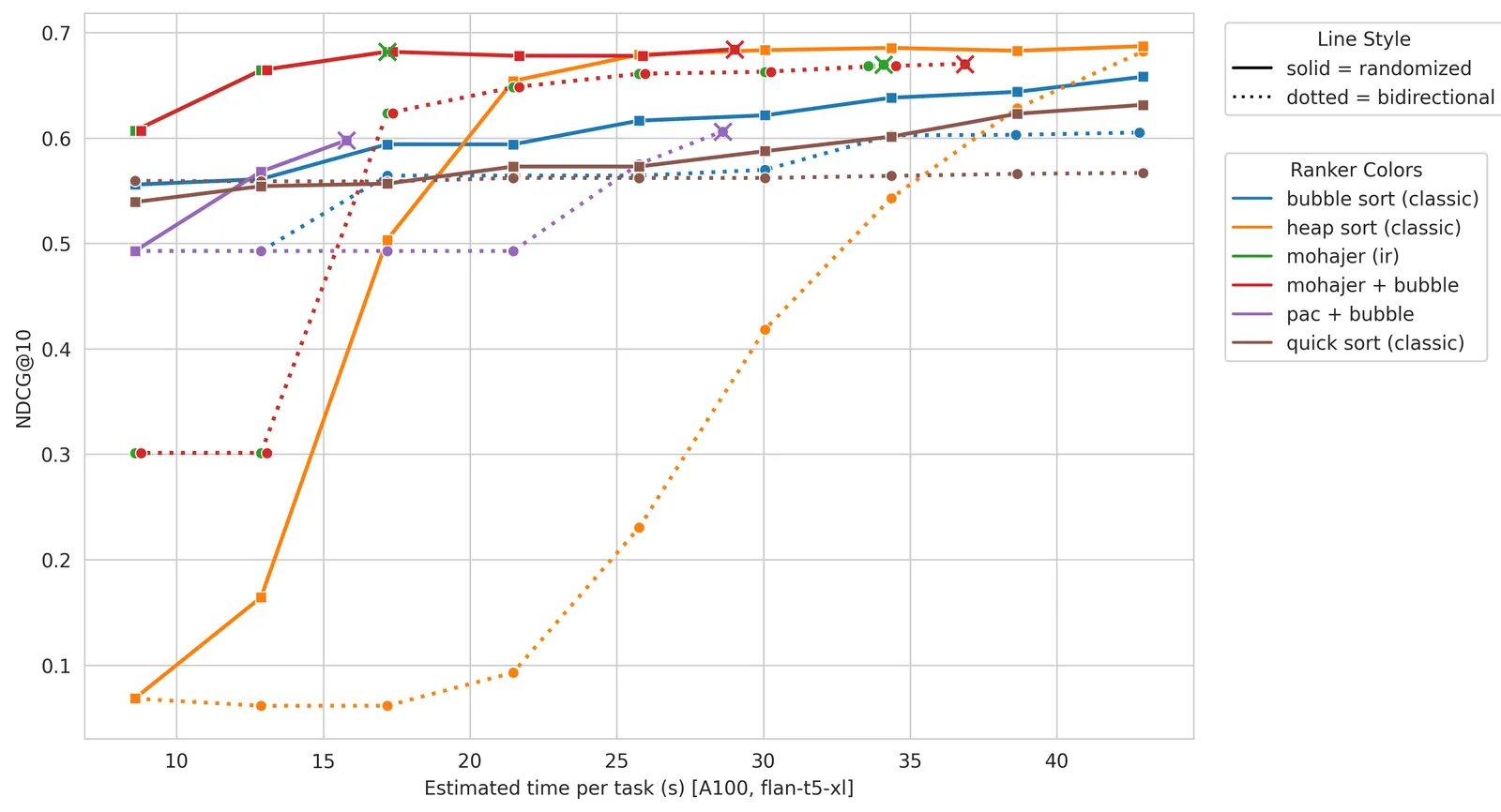
把 LLM 成对重排看作主动学习,锦标赛选择器在 TREC DL 上拿到 68.00 NDCG@10,LLM 调用比排序式 PRP 少 3-5 倍,随机方向 oracle 把位置偏置变噪声。
快速答案
这篇论文把成对排序提示(PRP)——让 LLM 判断「文档 A 是否比 B 更相关」——重新表述成一个主动学习问题,并证明这个视角很值。它的锦标赛式选择器 Mohajer 在 TREC DL 上用 Flan-T5-XL 拿到 68.00 NDCG@10,而 LLM 调用次数比排序式 PRP 基线少 3-5 倍。核心技巧是一个随机方向 oracle:每对文档随机决定谁排前面,只发一次 LLM 调用,把 LLM 评判器众所周知的位置偏置转成无偏噪声,而主动排序器天生能容忍噪声。
为什么排序式 PRP 浪费调用
成对排序提示精度高但昂贵:它一次只比两个文档,而把比较结果变成排名最直接的办法就是排序。问题在于,LLM 的成对判断用作者的话说是「有噪声、对顺序敏感、有时还不可传递」——A 胜 B、B 胜 C,却 C 胜 A。经典比较排序假设存在干净的全序,于是要么反复重查不稳定的对(BubbleSort 的滑动窗口每个任务能跑到 941-1669 次调用),要么仅凭一次摇摆的比较就下了确定结论。当每次比较都是一个数十亿参数模型的前向推理时,这两种都不是你想要的。
主动排序如何改变预算
关键洞察是:你很少需要完整排名——top-k 检索只要把头部文档排对就行。主动排序算法把比较预算花在刀刃上:它们把排名当作要通过有信息量的查询去「学」的东西,而不是穷举式地排序。论文用几种这类选择器对标排序基线(BubbleSort、HeapSort、QuickSort),其中两个最突出:Mohajer,一个锦标赛式 top-k 选择器;以及优化版 PAC(概率近似正确)流程。两者都自适应地决定该比较哪些对,因此一旦榜单头部稳定就提前停手,而不必跑完整轮排序。
随机方向 oracle
位置偏置——LLM 不看内容、系统性地偏向第一个或第二个文档——是 PRP 的隐形杀手。标准修法是双向 oracle:既问 A-vs-B 又问 B-vs-A 再调和,但这让调用翻倍。本文的替代是随机方向 oracle:对每一对,抛硬币决定哪个文档排前面,然后只发一次调用。在大量比较里偏置被平均成零均值噪声,而主动排序器本就为容忍噪声而设计。你用一半的调用换到了大部分去偏效果。这是论文最干净的点子,而且作者坦承:他们目前还无法从理论上解释它为何效果这么好。
关键结果
- TREC DL 上 68.00 NDCG@10(DL2019/2020,Flan-T5-XL):随机方向 oracle 下的 Mohajer 选择器,预算 B=250 与 B=300 调用时取得。
- 比 BubbleSort 高 +9.67 NDCG@10:双向 oracle、B=300 同等调用预算下,Mohajer 得 66.09,BubbleSort 仅 56.42。
- 端到端少 3-5 倍 LLM 调用:BEIR 式任务(N=100、K=10)上,主动选择器每任务用 184-345 次调用(55.0-57.3 NDCG@10),而 BubbleSort PRP 要 941-1669 次(56.8-60.4 NDCG@10)。
- 跨多个模型规模验证:Flan-T5-L、Flan-T5-XL、Flan-T5-XXL、Qwen3-4B-Instruct;数据集覆盖 COVID、Robust04、Touché、SciFact、DBPedia、FiQA。
局限与存疑
诚实地看:这是效率换质量的权衡,不是白赚。在端到端 BEIR 数字上,主动选择器的原始 NDCG@10 其实略低于 BubbleSort(55.0-57.3 对 56.8-60.4)——卖点是用零头的调用逼近同等质量,而不是重排得更好。作者也坦白:随机方向的增益「实证上一致但缺乏理论解释」,延迟测量不完整、未实现并行化(这会改变那些易并行排序算法的调用预算账),提示设计、模型家族、解码设置都会移动数字,且没有对 PAC 超参数 m 做消融。所以它在真正受调用约束的场景里最有说服力——小预算、昂贵评判器;若你能廉价地批量或并行比较,优势就弱了。
常见问题
《Active Learners as Efficient PRP Rerankers》到底提出了什么?
它主张把 LLM 成对重排当成主动学习:不再用穷举成对比较去排序,而是用主动排序选择器(主要是 Mohajer 和优化版 PAC)自适应地挑选要比较哪些对,再配一个每对只用一次调用的随机方向 oracle 来去偏。
这套主动 PRP 方法能省多少 LLM 调用?
在 BEIR 式任务上比排序式 PRP 少 3-5 倍——每任务约 184-345 次,对比 BubbleSort 的 941-1669 次,而 NDCG@10 与更贵的基线只差几个点。
论文里的随机方向 oracle 是什么?
对每一对文档,随机决定哪个先出现,然后只做一次 LLM 比较调用。这把 LLM 系统性的位置偏置变成零均值噪声,用一半成本拿到接近双向(两次调用)oracle 的去偏效果。
主动 PRP 在排序质量上能赢过标准 PRP 吗?
在端到端设置的原始质量上不能——BubbleSort PRP 的 NDCG@10 可能还略高一点。它的贡献是效率:在质量贴近的同时大幅减少 LLM 调用,而当每次比较都是昂贵的模型调用时,这才是要紧的。
一句话:把 LLM 成对重排重新表述成主动学习、随机化比较方向,你就能用零头的调用保住大部分排序质量。阅读 arXiv 原文。