AgentDoG 1.5:轻量可扩展的 AI 智能体安全护栏
AgentDoG 1.5 仅用约 1k 样本训练 0.8B-8B 智能体安全护栏,4B 版在 R-Judge 上拿到 92.2% 准确率,逼近 GPT-5.4,部署开销砍掉两个数量级。
快速答案
AgentDoG 1.5 是一套开源的 AI 智能体安全护栏:它判断一条完整的智能体执行轨迹是否危险,而且小到真能部署。4B 版本仅用约 1000 条训练样本,就在 R-Judge 上拿到 92.2% 准确率、92.7% F1,与 GPT-5.4(93.3% / 93.7%)只差约一个百分点。在细粒度风险诊断上它甩开 GPT-5.4:三个风险维度平均准确率 55.2%,而 GPT-5.4 只有 25.8%。模型与数据集全部开源。
智能体护栏为什么失灵了
威胁模型变了。Codex、OpenClaw 这类开放世界智能体如今会在 shell、文件、工具之间执行真实命令,而前沿模型又降低了攻击者构造漏洞的门槛。只看单条提示或单次工具调用的护栏会漏掉伤害——因为智能体场景的风险来自整条轨迹:一串看似无害的步骤,最后却导致数据外泄、破坏性 shell 命令或跨工具攻击链。此前的智能体对齐工作要么用闭源前沿 API 当裁判(贵、不可审查、有延迟),要么用笨重的微调模型(无法对每个动作做内联实时判断)。
AgentDoG 1.5 怎么做
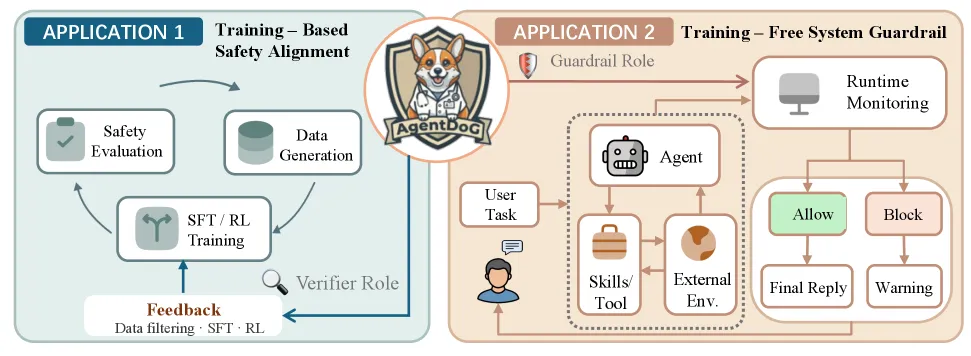
框架把安全诊断拆成三条轴:风险来源(危险从哪来)、失败模式(智能体怎么出错)、现实危害(造成什么损失),并更新了安全分类体系,为 Codex 与 OpenClaw 执行场景补充了专门的叶子类别。一个由分类体系驱动的数据引擎生成训练轨迹,再用影响函数提纯把它们筛到约 1k 条高信号样本。训练分两阶段:先监督微调,再强化学习,并带链式推理,让护栏给出判断理由而非一个干巴巴的标签。基座是 Qwen3.5 系列加 Llama-3.1-8B-Instruct,产出 0.8B、2B、4B、8B 四档护栏。
它身兼两职:作为训练期的奖励/过滤器,清洗智能体 SFT 数据、给 RL 轨迹打分;作为免训练的在线护栏,内联实时审查活动智能体的动作,无需再训练。
关键结果
- R-Judge: AgentDoG 1.5-4B 拿到 92.2% 准确率 / 92.7% F1,基本追平 GPT-5.4(93.3% / 93.7%),落后于 Gemini-3.1-Pro(97.3%)。
- ATBench(论文自建的 1000 条轨迹基准,503 安全 / 497 不安全): 统一版 4B 拿到 78.4% 准确率 / 77.7% F1,高于 GPT-5.4 的 73.7% 和 Gemini-3.1-Pro 的 75.5%,远高于 AgentDoG 1.0-4B 的 64.0%。
- 细粒度诊断(ATBench 三维平均): AgentDoG 1.5-4B 达 55.2%(风险来源 75.2%、失败模式 27.5%、现实危害 62.9%),GPT-5.4 仅 25.8%——这是全文优势最大的一项。
- 作为安全 SFT 的数据过滤器(Qwen3.5-4B): AgentHarm 危害分从 57.49% 降到 20.32%,拒答率从 28.41% 升到 75.00%,同时 BFCL 函数调用准确率守在 81.12%——安全提升而不毁掉能力。
- 可扩展性: 有限状态模拟训练环境峰值显存控制在 2.5 GB 以内,却能支撑 10000 个并发环境,相比 Docker 级方案(SWE-Bench、AgentHazard)把部署开销降低两个数量级。
老实说:二分类安全的头部数字不错但非顶尖——R-Judge 上输给 Gemini-3.1-Pro,ATBench 上也只是略胜前沿 API。真正拉开差距的是细粒度诊断:一个 4B 开源模型把 GPT-5.4 的准确率几乎翻倍,加上仅用约 1k 样本达成的成本优势。
局限与存疑
失败模式分类是短板:27.5% 远低于风险来源的 75.2%,作者也承认受资源限制,统一的「粗到细」模型并未针对细粒度诊断专门优化。100 倍开销下降来自有限状态模拟环境,它用现实保真度换取可部署性——所以在模拟里调好的护栏,面对真正新颖的真实执行可能表现不同。覆盖范围锚定在 Codex 与 OpenClaw 场景,其它智能体平台留作未来工作。和所有护栏一样,公开成绩反映的是已知攻击分布,而非针对护栏本身做优化的自适应对手。
常见问题
AgentDoG 1.5 是什么?
AgentDoG 1.5 是一套轻量、开源的 AI 智能体安全护栏框架。它训练小模型(0.8B-8B)检查智能体的完整执行轨迹,标记不安全行为,并诊断风险来源、失败模式与现实危害——既可作训练期过滤器,也可作免训练的在线监控。
AgentDoG 1.5 和 GPT-5.4 比怎么样?
4B 版在 R-Judge 上几乎追平 GPT-5.4(92.2% 对 93.3% 准确率),而在细粒度风险诊断上大幅领先(平均 55.2% 对 25.8%)。在 ATBench 二分类基准上,统一版 4B 拿到 78.4%,高于 GPT-5.4 的 73.7%。
为什么 AgentDoG 1.5 只用约 1k 样本训练?
分类体系驱动的数据引擎先生成候选轨迹,再用影响函数提纯,只保留信息量最大的约 1000 条。核心思路是:让小护栏达到接近前沿的安全判断,靠的是精挑数据而非堆数据量,从而更便宜。
部署开销降 100 倍是什么意思?
AgentDoG 1.5 自带有限状态模拟训练环境,峰值显存 2.5 GB 以内即可支撑 10000 个并发智能体环境,取代笨重的「每个智能体一个 Docker」方案,使大规模智能体安全 SFT 与 RL 的运行成本约降低两个数量级。
一句话:一个 4B 开源护栏,用约 1k 样本训练,判断整条智能体轨迹的水平接近 GPT-5.4,解释「为何不安全」则远胜。阅读 arXiv 原文。