AgentDoG 1.5: A Lightweight Guardrail for AI Agent Safety
AgentDoG 1.5 trains 0.8B-8B agent-safety guard models on only ~1k samples, hits 92.2% accuracy on R-Judge with the 4B variant, rivals GPT-5.4, and cuts agentic-RL deployment overhead by two orders of magnitude.
Quick answer
AgentDoG 1.5 is an open agent-safety guardrail that judges whether an AI agent’s full execution trajectory is dangerous — and trains small enough to actually deploy. The 4B variant reaches 92.2% accuracy and 92.7% F1 on R-Judge, within about a point of GPT-5.4 (93.3% / 93.7%), using only around 1,000 training samples. On fine-grained risk diagnosis it goes much further than GPT-5.4: 55.2% average accuracy across three risk dimensions versus GPT-5.4’s 25.8%. The models and datasets are released openly.
Why agent guardrails broke
The threat model shifted. Open-world agents like Codex- and OpenClaw-style coding/computer-use systems now execute real commands across shells, files, and tools — and frontier models lower the bar for attackers to craft those exploits. A guardrail that only inspects a single prompt or a single tool call misses the harm, because risk in agentic settings emerges from a trajectory: a benign-looking sequence of steps that ends in data exfiltration, destructive shell commands, or cross-tool attack chaining. Most prior agent-alignment work either leans on a closed frontier API as judge (expensive, uninspectable, latency-bound) or on a heavy fine-tuned model that is impractical to run inline on every action.
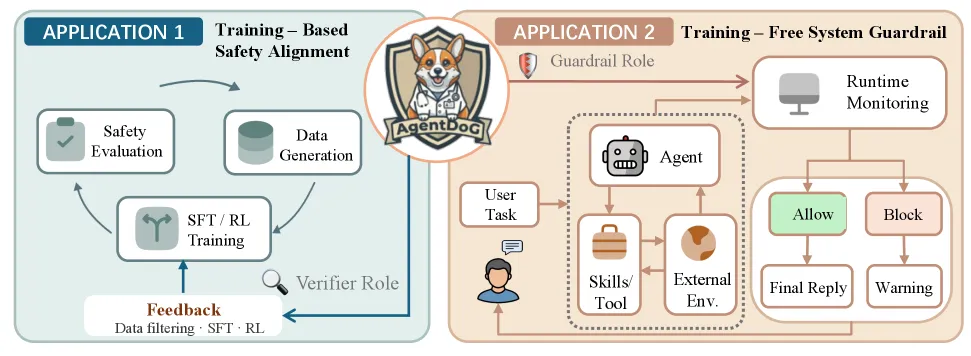
How AgentDoG 1.5 works
The framework decomposes safety diagnosis along three axes — risk source (where the danger comes from), failure mode (how the agent fails), and real-world harm (what damage results) — under an updated taxonomy that adds leaf categories specific to Codex and OpenClaw execution scenarios. A taxonomy-guided data engine generates training trajectories, then influence-function purification filters them down to roughly 1k high-signal samples. Training is two-stage: supervised fine-tuning followed by reinforcement learning, with chain-of-thought reasoning so the guard explains its judgment rather than emitting a bare label. The base models are the Qwen3.5 series plus Llama-3.1-8B-Instruct, yielding 0.8B, 2B, 4B, and 8B guards.
It serves two roles. As a training-time reward/filter, it cleans agent SFT data and scores RL rollouts. As a training-free online guardrail, it sits inline and moderates a live agent’s actions in real time with no further training.
Key results
- R-Judge: AgentDoG 1.5-4B scores 92.2% accuracy / 92.7% F1, essentially matching GPT-5.4 (93.3% / 93.7%) and trailing Gemini-3.1-Pro (97.3%).
- ATBench (the paper’s own 1,000-trajectory benchmark, 503 safe / 497 unsafe): the unified 4B variant hits 78.4% accuracy / 77.7% F1, above GPT-5.4’s 73.7% and Gemini-3.1-Pro’s 75.5%, and well above AgentDoG 1.0-4B at 64.0%.
- Fine-grained diagnosis (ATBench, 3-dimension average): AgentDoG 1.5-4B reaches 55.2% (risk source 75.2%, failure mode 27.5%, real-world harm 62.9%) versus GPT-5.4 at 25.8% — the largest margin in the paper.
- As a data filter for safety SFT (Qwen3.5-4B): AgentHarm harm score drops from 57.49% to 20.32% and refusal rate rises from 28.41% to 75.00%, while BFCL function-calling accuracy stays at 81.12% — safety up without wrecking utility.
- Scalability: a finite-state simulation training environment holds a peak memory footprint under 2.5 GB while supporting 10,000 concurrent environments, cutting deployment overhead versus Docker-level setups (SWE-Bench, AgentHazard) by two orders of magnitude.
The honest read: the headline binary-safety numbers are good but not category-leading — Gemini-3.1-Pro beats it on R-Judge, and on ATBench it only edges the frontier APIs. The genuinely differentiating result is fine-grained diagnosis, where a 4B open model roughly doubles GPT-5.4’s accuracy, plus the cost story of getting there on ~1k samples.
Limits and open questions
Failure-mode classification is the weak link: at 27.5% it badly trails risk-source accuracy (75.2%), and the authors admit the unified coarse-to-fine model was not specifically optimized for fine-grained diagnosis due to resource constraints. The 100x overhead reduction comes from finite-state simulated environments that trade strict real-world fidelity for deployability — so a guard tuned in simulation may behave differently against genuinely novel real execution. Coverage is anchored to Codex and OpenClaw scenarios; other agent platforms are future work. And as with any guardrail, the published scores reflect known attack distributions, not adaptive adversaries who optimize against the guard itself.
FAQ
What is AgentDoG 1.5?
AgentDoG 1.5 is a lightweight, open guardrail framework for AI agent safety. It trains small models (0.8B-8B) to inspect an agent’s full execution trajectory, flag unsafe behavior, and diagnose the risk source, failure mode, and real-world harm — usable both as a training-time filter and a training-free online monitor.
How does AgentDoG 1.5 perform against GPT-5.4?
On R-Judge it nearly matches GPT-5.4 (92.2% vs 93.3% accuracy) at 4B parameters, and on fine-grained risk diagnosis it far exceeds it (55.2% vs 25.8% average). On the ATBench binary benchmark the unified 4B variant scores 78.4% versus GPT-5.4’s 73.7%.
Why is AgentDoG 1.5 trained on only ~1k samples?
A taxonomy-guided data engine generates candidate trajectories, then influence-function purification keeps only the most informative ~1,000 examples. The point is that careful data selection, not data volume, drives a small guard model to frontier-comparable safety judgment cheaply.
What does the 100x deployment-overhead reduction mean?
AgentDoG 1.5 ships with a finite-state simulated training environment that supports 10,000 concurrent agent environments under 2.5 GB peak memory, replacing heavy Docker-per-agent setups. This makes large-scale agentic safety SFT and RL roughly two orders of magnitude cheaper to run.
One line: a 4B open guard, trained on ~1k samples, judges whole agent trajectories about as well as GPT-5.4 and far better at explaining why. Read the original paper on arXiv.