多模态模型 · 文生图 · Transformer
ARM:统一离散表征的自回归多模态大模型详解
ARM 是 7B 自回归模型,用一套下一 token 预测同时做理解、文生图和编辑,底层是共享离散分词器;RL 把 GenEval 从 0.79 提到 0.86。
快速答案
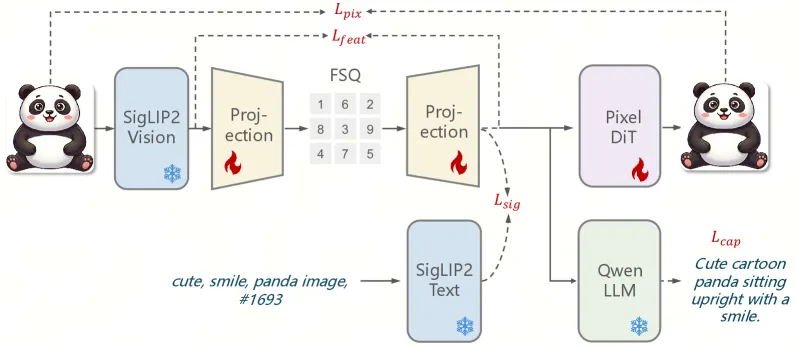
ARM 是单个 7B 自回归模型,用一套下一 token 目标同时预测文本与图像 token,覆盖理解、文生图和指令编辑。共享层是一个用四个目标一起训练的离散视觉分词器,所以同一套 token 喂给三个任务。监督训练之后,强化学习把 GenEval 从 0.79 提到 0.86,GEdit-Bench-EN 总分从 5.75 提到 6.68,而且文生图和编辑的 RL 会同时帮到两个任务。这些提升是配方的结果:一个主干、一套 token 空间,再加一层偏好优化。
分词器要解决什么
统一模型一直卡在分词器的取舍上。CLIP、SigLIP 这类语义编码器带高层含义、利于理解,却丢掉了重建和编辑所需的细节。像素级 VQ 分词器重建好,但语义弱,理解就吃亏。ARM 想用一套离散码同时拿到两边,办法是用四个损失一起监督分词器(公式 4,权重 1、5、5、1):
- 字幕损失,让量化后的 token 去预测一段描述,逼出语言对齐。
- 像素重建损失,用一个轻量扩散解码器学整流速度场,保真度由它负责。
- sigmoid 对比损失(SigLIP 风格),在 batch 内拉开语义可分性。
- 特征蒸馏损失,用余弦距离把量化嵌入对齐到原始 SigLIP2 特征。
量化用 Finite Scalar Quantization(FSQ),不需要显式可学习码本就能给到高容量。消融是四个目标有用的最干净证据:只用字幕加像素损失,ImageNet 零样本准确率塌到 0.2,PSNR 只有 15.2。加上 sigmoid 损失,零样本跳到 79.4,但 PSNR 掉到 9.3。四目标完整配方一次拿到 80.2 零样本和 19.6 PSNR,码本利用率(75.6)和困惑度(0.28)也最高。
一个模型怎么覆盖三个任务
token 空间定下来后,ARM 在交错的文本与图像 token 上训练 7B 自回归主干,用一个普通的下一 token 损失(公式 6)。训练分三阶段(预训练、续训、监督微调),最多用 200 张 GPU、序列长 80K,文生图是主导数据(占比 0.70 逐阶段降到 0.50)。图像生成和编辑就是模型吐出的视觉 token 序列,再由一个潜空间扩散解码器还原成像素。所以理解、生成、编辑是同一个操作配不同提示,这正是离散 token 设计的用意。
关键结果
- 理解(7B 统一模型): ARM 拿到 POPE 87.3、MMBench 80.7、MME-感知 1463、MMMU 40.2、GQA 76.1、SEED 73.1。在离散 token 统一模型里,它在 POPE 和 MMBench 领先,和 Janus-Pro、Show-o2 这类连续表征统一模型相当。
- 文生图(GenEval / DPG): RL 前 ARM 是 0.79 GenEval、84.48 DPG;ARM-RL 到 0.86 GenEval、86.00 DPG,接近 Janus-Pro-7B(0.80),低于 Qwen-Image(0.87)这类扩散头部。
- 推理生成(WISE): ARM 总分 0.50,与 FLUX.1[Dev] 持平,高于 Emu3(0.39)和 Janus-Pro-7B(0.35);RL 把 WISE 提到 0.56。
- 编辑(GEdit-Bench-EN): RL 前 ARM 总分 5.75,ARM-RL 6.68,接近 Step1X-Edit(6.70)和 BAGEL(6.52)。感知质量 G_PQ 7.68,是表里最高。
- RL 协同: 依次做 T2I RL、Edit RL、Joint RL,GEdit 从 5.75 到 6.68,GenEval 从 0.79 到 0.86,而理解分基本不动(MMMU 40.2 到 41.0,POPE 在 87 上下)。只做编辑 RL 也会带动 T2I,只做 T2I 也带动编辑。
怎么读这些对比
ARM 是离散 token 的自回归模型,天然对手是其他统一模型:Emu3、Janus / Janus-Pro、Show-o / Show-o2、Chameleon、Liquid、VILA-U。对这些它理解强、生成有竞争力。对纯扩散专用模型(Qwen-Image、FLUX、编辑上的 BAGEL),它在生成和编辑头部分上落后,但落后的是一个还能读图的模型,而专用模型不会读图。RL 阶段用 GRPO 式目标(公式 7),奖励模型是 GPT-o3 和 GPT-4.1,所以后训练收益依赖一个外部裁判,不是固定指标。
局限与存疑
ARM 没有压过扩散专用模型的生成与编辑:GenEval 0.86 低于 Qwen-Image 0.87,GEdit 6.68 低于 Step1X-Edit 6.70,和 BAGEL 大致打平。MMMU 40.2 落后于 Bagel(55.3)、Show-o2(48.9)这类连续统一模型,所以理解的领先是看具体基准的,不是全面领先。RL 奖励来自闭源 GPT 模型,没有同样的裁判和提示,0.79 到 0.86、5.75 到 6.68 这些跳幅很难复现。论文没报 FID,也没给自回归解码加扩散反分词这条路径的算力或时延成本,所以相对扩散基线的实际生成速度是个未知数。
对开发者的判断
如果你在做统一模型、被语义与保真的分词器取舍卡住,这里最能搬走的点是四目标分词器消融:sigmoid 项和特征蒸馏项,是让一套码同时拿到 80.2 ImageNet 零样本和 19.6 PSNR 的关键。RL 带来协同的结论值得盯,但绑在 GPT 奖励模型上,具体数字按各自配置看。今天若只要最强图像编辑,扩散编辑器在 GEdit 上分更高;ARM 的论点是一个自回归模型能在三个任务上同时接近头部。
常见问题
ARM(自回归多模态大模型)是什么?
ARM 是 Institute of Trustworthy Embodied AI 和字节 Seed 出的 7B 自回归模型,用一套下一 token 目标、在共享离散视觉分词器上统一图像理解、文生图和指令编辑。RL 后达到 GenEval 0.86、GEdit-Bench-EN 总分 6.68。
ARM 的离散视觉分词器和 CLIP、VQ 分词器有什么不同?
ARM 用四个目标一起监督一个分词器:字幕、像素重建、SigLIP 式 sigmoid 对比损失、SigLIP2 特征蒸馏,量化用 FSQ。消融显示只用字幕加像素是 0.2 ImageNet 零样本、15.2 PSNR,四个一起才能同时到 80.2 和 19.6,这是只用 CLIP 或只用 VQ 的分词器做不到的。
ARM 比 BAGEL、Qwen-Image 这类扩散模型强吗?
原始分数上没有。ARM-RL 是 GenEval 0.86 对 Qwen-Image 0.87,GEdit-Bench-EN 6.68 对 Step1X-Edit 6.70、BAGEL 6.52。ARM 的论点是用一个还能做理解的模型在生成和编辑上接近持平,不是在某个专用指标上取胜。
ARM 里强化学习加了什么?
用 GRPO 加 GPT 奖励模型的 RL 把 WISE 从 0.50 提到 0.56、GenEval 从 0.79 提到 0.86、GEdit-Bench-EN 总分从 5.75 提到 6.68,而理解分不动。论文还报了跨任务协同:做文生图 RL 会帮到编辑,反过来也成立。
一句话:ARM 把理解、文生图和编辑塞进一个 7B 自回归模型,底层是四目标离散分词器,再用 GPT 裁判的 RL 补上和扩散专用模型的大部分差距。阅读 arXiv 原文。