DelTA:面向可验证奖励强化学习的判别式 Token 信用分配
DelTA 把 RLVR 更新重加权,让信用落在真正能区分对错的 token 上,使 Qwen3-8B-Base 平均提升 3.26 分、Qwen3-14B-Base 提升 2.62 分。
快速答案
DelTA 把 RLVR 里的每一步策略梯度更新看作对 token 梯度向量的一个线性判别器,再对更新做重加权,让信用集中到真正能区分「答对/答错」的 token 上,而不是高频的格式与填充词。在七个数学推理基准上,它让 Qwen3-8B-Base 平均准确率提升 3.26 分(28.40 对 25.14),让 Qwen3-14B-Base 提升 2.62 分(39.91 对 37.29),全面超过 DAPO、SAPO 和 FIPO。
问题:回答级奖励,token 级更新
RLVR(可验证奖励的强化学习)只给模型一个标量——最终答案对不对——但梯度必须把这一个数字翻译成成千上万个 token 的概率微调。这就是信用分配问题,而标准的序列级方法处理得很粗暴:正确回答里的每个 token 都被同一个优势权重往上推,错误回答里的每个 token 都被往下压。
失败模式很具体。格式 token、连接词、套话几乎出现在每条回答里,不论对错。正因为它们太频繁,即便几乎不携带「推理是否成立」的信号,也会主导平均后的更新方向。真正起决定作用的 token——模型选对关键引理的那一步、它算对的那个数字——反而稀少,贡献被淹没。于是梯度预算大多花在了那些区分不出好坏轨迹的 token 上。
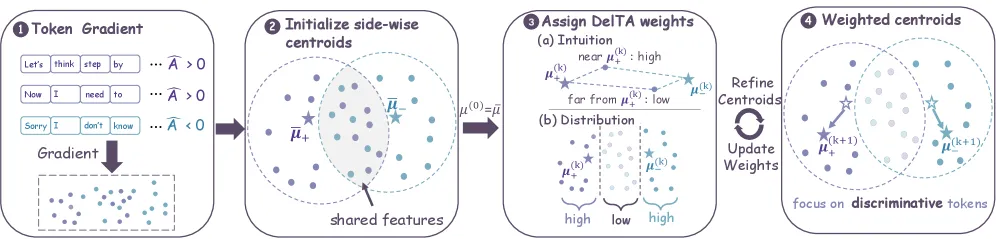
DelTA 如何重构信用分配
论文最有意思的是这层重构:它证明一次策略梯度更新在数学上等价于在 token 梯度向量上构建一个线性判别器——更新方向是由优势加权的 token 向量构成的质心,施加它就像把策略推向「正确」一侧、远离「错误」一侧。标准序列级 RLVR 用朴素平均来构造这个质心,这正是高频低信息 token 能压过它的原因。
DelTA 估计每个 token 的系数,放大侧别专属方向(明确指向正确或指向错误的 token),同时降低共享或弱判别 token 的权重(那些哪儿都不指的套话)。具体做法是对一个自归一化的 RLVR 代理目标做重加权,产出一个更有对比度的质心。重加权改变了哪些 token 驱动更新,但最终目标依然更新全部策略参数——这不是局部微调。
作者自己点明了一个诚实的代价:为了便宜地估计这些系数,DelTA 用的是受限于部分层的 token 梯度代理,而非全参数 token 梯度。这是出于算力的近似,不是白捡的便宜,也是该方法在不同模型族上最可能掉链子的地方。
关键结果
- Qwen3-8B-Base,七个数学基准: DelTA 平均 28.40,最强基线 25.14——提升 3.26 分。
- Qwen3-14B-Base,同一套件: 39.91 对 37.29——提升 2.62 分。
- AIME24: 43.13(8B)、56.87(14B),分别高于 38.75(SAPO)和 54.58(FIPO)。
- AIME25: 26.46(8B)、37.92(14B),对 24.37 与 35.00。
- HMMT25(2 月): 18.33(8B)、26.04(14B),对 15.62 与 21.46。
- Brumo 25: 44.79(8B)、54.79(14B),单基准领先幅度最大。
- 对比基线: DAPO、带 Forking Tokens 的 DAPO、SAPO 与 FIPO——DelTA 在几乎每个数据集上都领先各自的「最强基线」,而非仅平均领先。
- 数学之外: 论文还报告了代码生成(相对 DAPO 基线)、另一基座 Olmo3-7B-Base、以及域外评测的增益,但这些放在附录而非主表。
为什么现在重要
RLVR 是后训练推理模型的主流配方,而近期几乎每个变体——DAPO、SAPO、FIPO——都在改优势估计或裁剪。DelTA 攻的是一个更根本的关节:token 级信用信号本身,而且靠的是判别器论证而非启发式。在 AIME、HMMT 这类已接近饱和的硬数学基准上拿到 2 到 3 分的平均提升,在前沿是有分量的;而质心对比的框架本身可复用——它给「这份奖励到底该移动哪些 token」一个有原则的答案,而任何 RLVR 管线本就要隐式回答这个问题。
局限与存疑
诚实的局限在论文里写得清楚。其一,主要增益集中在数学推理;代码与域外结果存在,但只是附录规模,胜势的广度尚未确立。其二,DelTA 带来作者称为「适度但真实」的算力开销,依赖受限于部分层的梯度代理——全参数 token 梯度更忠实但更贵,代理在准确率上的代价没有定量说清。其三,所有主结果都在 Qwen3-Base 的 8B 与 14B 加一次 Olmo 运行上;能否扩展到更大规模、指令微调后的起点、或不如可验证数学那么干净的奖励信号,都还是开放问题。判别器框架优雅,但它相对更简单的优势重塑的实际优势,应在每个新场景上重新核验。
常见问题
DelTA 到底改了 RLVR 训练的什么?
DelTA 对每个 token 在策略梯度更新中的贡献做重加权,放大能区分对错的 token,压低高频低信号 token(格式、连接词)。它通过对一个自归一化的 RLVR 代理目标重加权来实现,且保持全部策略参数可更新。
DelTA 比 DAPO、SAPO、FIPO 强多少?
在七个数学基准上,DelTA 让 Qwen3-8B-Base 平均提升 3.26 分(28.40 对 25.14),让 Qwen3-14B-Base 提升 2.62 分(39.91 对 37.29),超过 DAPO、带 Forking Tokens 的 DAPO、SAPO 与 FIPO 中的最强者。
为什么标准 RLVR 会过度奖励格式 token?
因为序列级 RLVR 把一个优势权重平均到回答里所有 token 上,而格式与套话 token 几乎出现在每条回答里。它们的高频让它们主导平均后的更新方向,尽管几乎不携带「答案对不对」的信号。
DelTA 只对数学推理有效吗?
头部结果在七个数学基准上,但论文也报告了代码生成、Olmo3-7B-Base 模型和域外评测上的增益。这些更广的结果只是附录规模,所以数学才是证据最强的地方。
DelTA 的主要弱点是什么?
它依赖受限于部分层的 token 梯度代理(而非全参数 token 梯度)来压低系数估计成本,并带来适度算力开销。其主结果也只限于 Qwen3-Base 的 8B/14B,更大规模和指令模型上的表现尚未验证。
一句话:别把梯度花在区分不出对错的 token 上。阅读 arXiv 原文。