FORT-Searcher:训练不抄近路的搜索智能体
FORT-Searcher 用抗捷径任务训练 3B active 搜索智能体,同规模开源总体 66.2;FORT 数据把答案命中时间从 18.7 推迟到 46.9。
快速答案
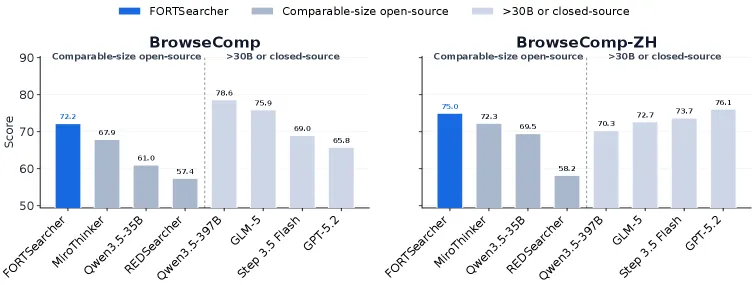
FORT-Searcher 解决的是深度搜索智能体训练数据里的“假难题”问题:题面看起来多跳复杂,但一个罕见线索、一个暴露常数或模型先验就能很早锁定答案。FORT 定义了四类捷径风险,再合成让取证过程真正必要的任务。SFT-only 的 FORT-Searcher 在同规模开源搜索智能体里总体 66.2,BrowseComp 72.2,BrowseComp-ZH 75.0。更关键的证据是轨迹诊断:FORT 数据平均求解成本 141.0、答案命中时间 46.9,而 REDSearcher 数据是 92.1 和 18.7。
难度要看答案何时出现
这篇论文先把结构复杂度和真实搜索难度拆开。一个问题可以有很多事实节点,但如果一个线索第一轮搜索就暴露答案,它并不能训练深度搜索。FORT 关注四类风险:证据共覆盖、单线索过强、常数暴露、先验绑定。
合成流程围绕这些风险做控制:先选长尾实体,再构建证据图,再生成题面,最后用强搜索智能体做对抗式 refinement。捷径太明显的草稿要修,过度模糊导致不可解的草稿也要收窄。目标不是越难越好,而是可解且必须搜索。
FORT-Searcher 本身并不靠巨大模型取胜。它基于 Qwen3-30B-A3B-Thinking,推理时约 3B active 参数,只做监督微调。这让结论更集中在数据质量和 rollout 协议上。
关键结果
- 五个完整可比基准总体 66.2,高于 MiroThinker-1.7-mini 的 64.6 和 Qwen3.5-35B-A3B 的 59.9。
- BrowseComp 为 72.2,BrowseComp-ZH 为 75.0,xbench-DeepSearch-2505 为 80.8,xbench-DeepSearch-2510 为 57.2,Seal-0 为 46.0。
- 上下文管理影响很大:BrowseComp 从 55.9 升到 72.2,BrowseComp-ZH 从 62.1 升到 75.0。
- 同一诊断下,FORT 数据求解成本 141.0、答案命中时间 46.9;REDSearcher 为 92.1 和 18.7。
- 移除捷径控制后,合成题准确率从 29.0 升到 81.6,答案命中时间从 46.5 提前到 11.8,说明题目变容易了。
对研究者和构建者的判断
实际价值不在于照搬标题数字。FORT-Searcher 适合在你的任务分布和论文设置相近时参考,尤其要看清楚比较对象、评测协议和收益来源。如果你的系统瓶颈不是论文测到的那个环节,同一个方法可能只会增加复杂度。更稳妥的做法是先复现一个小规模本地评测,确认收益来自方法本身,而不是数据、工具链或裁判口径。
局限与存疑
FORT-Searcher 主要验证的是可核验短答案的 Web 搜索任务。它还不能证明同样方法适用于开放式研究、企业内部搜索,或需要主观质量判断的答案。部分轨迹诊断依赖强模型检查完整轨迹,所以这些指标是操作性代理,不是所有捷径的绝对真值。
真正会改变判断的证据,是更独立的外部复现、更完整的发布产物,以及由非作者团队设计的压力测试。在那之前,这篇更适合作为有清晰证据面的方向性结果,而不是无条件通用结论。
常见问题
FORT-Searcher 是什么?
它是一个用 FORT 合成数据监督微调出来的深度搜索智能体。FORT 的重点是让训练题抗捷径,逼迫模型在回答前真正获取证据。
FORT-Searcher 和同规模开源智能体比如何?
在有完整五项成绩的同规模开源智能体中,它总体 66.2,高于 MiroThinker-1.7-mini 的 64.6。
FORT 为什么不只是把搜索轨迹做长?
论文看答案命中时间和先验捷径率。FORT 推迟答案暴露、减少捷径,让智能体在回答前取证,而不是找到答案后继续绕路。
一句话:FORT-Searcher 的价值在于把搜索数据难度定义成轨迹属性,而不是图有多大。 阅读 arXiv 原文。