EurekAgent:科研智能体的环境工程
EurekAgent 认为瓶颈在环境设计,报告 26-circle packing 2.635999、TriMul 2005.03 微秒、MLE-Bench medal 85.71%。
快速答案
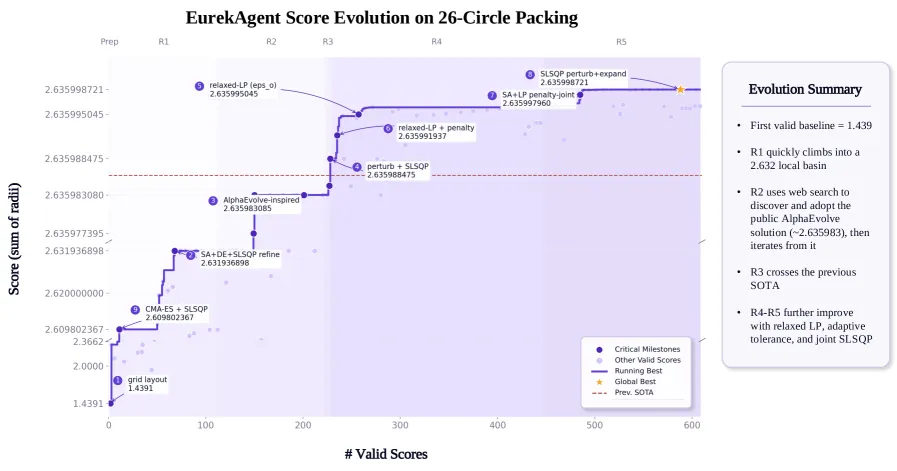
EurekAgent 的主张是:自主科学发现的瓶颈正在从“给智能体规定固定 workflow”转向“设计智能体所在的环境”。系统用权限、产物、预算和人类监督界面来让探索可控、可追踪、可复现。报告结果很亮眼:26-circle packing 为 2.635999,Erdos minimum overlap 为 0.380870,first autocorrelation inequality 为 1.502861,TriMul median 2005.03 微秒,7 题 MLE-Bench Lite 子集 any-medal 为 85.71%。
用环境替代固定流程
EurekAgent 没有为每类科研任务写死一套方法。它围绕现成 CLI agent 运行 prepare-propose-implement 循环。环境决定智能体能看什么、能改哪里、官方分数如何记录、历史尝试如何保留、预算快耗尽时怎样提醒。
权限工程是安全层。智能体可以使用工具和互联网资源,但隐藏 evaluator 和权威结果文件在可编辑工作区之外。同一轮并行实现 session 之间隔离,减少候选方案互相污染。
产物工程是记忆层。文件系统和 Git 历史保存准备摘要、proposal manifest、hypothesis、代码、分数和 transcript。预算工程把时间与 API cost 变成显式约束。人类监督界面让研究者能查看或纠偏,但不把系统退回纯手工执行。
关键结果
- 26-circle packing 报告 2.635999,高于前 AI 结果 2.635986 和约 2.634 的人类结果。
- Erdos minimum overlap 为 0.380870,低于前 AI 0.380876 和前人类 0.380927。
- first autocorrelation inequality 为 1.502861,略低于前 AI 1.502863。
- TriMul kernel engineering 最佳 median runtime 为 2005.0307 微秒,优于重评 leaderboard 第一的 2096.0441 微秒和 TTT-Discover 的 2247.7849 微秒。
- 7 题 MLE-Bench Lite 子集上,any-medal 85.71%,gold 71.43%,above median 100%。
对研究者和构建者的判断
实际价值不在于照搬标题数字。EurekAgent 适合在你的任务分布和论文设置相近时参考,尤其要看清楚比较对象、评测协议和收益来源。如果你的系统瓶颈不是论文测到的那个环节,同一个方法可能只会增加复杂度。更稳妥的做法是先复现一个小规模本地评测,确认收益来自方法本身,而不是数据、工具链或裁判口径。
对智能体构建者来说,最可迁移的是“探索自由”和“评价完整性”的分离。智能体可以搜索、写代码、查看历史尝试和迭代方案,但不能修改隐藏 grader 或权威分数文件。这个边界决定了系统是在做科研优化,还是只是给一个 coding agent 过大的文件系统权限。
第二个教训是工程化运行。长时间 discovery 需要可恢复状态、按分数排序的历史方案、预算耗尽时的中断策略,以及让人类能审查 transcript 的界面。这些不是炫技点,但如果系统找到了意外结果,正是这些记录决定结果能否被追踪和复核。
局限与存疑
论文主要验证有可执行 evaluator 和明确标量目标的任务。这很适合智能体优化,但不覆盖证据慢、噪声大、难以标量化的科学问题。部分对比来自本地重评或选定子集,不是统一大榜。环境工程这个方向可信,但这篇更像是有边界优化任务的强证据,不是完整“自动科学家”的证明。
真正会改变判断的证据,是更独立的外部复现、更完整的发布产物,以及由非作者团队设计的压力测试。在那之前,这篇更适合作为有清晰证据面的方向性结果,而不是无条件通用结论。
常见问题
EurekAgent 是什么?
它是一个环境工程化的自主科学发现系统,用权限、产物、预算和人类监督来协调 CLI agent 做有指标的科研优化。
EurekAgent 报告了哪些结果?
它在三个数学任务给出新最好数值,TriMul median 2005.03 微秒,7 题 MLE-Bench Lite 子集 any-medal 85.71%。
EurekAgent 的环境工程具体指什么?
指围绕智能体设计资源、约束、接口、记忆、evaluator 边界和预算控制,让探索既自由又可审计。
一句话:EurekAgent 最强的结论是,在可度量科研任务里,实验环境、评价边界和预算控制可能和提示词一样重要。 阅读 arXiv 原文。