Manifold Power Iteration:让 MoE 路由器更懂专家
MPI 让 MoE 路由行对齐专家权重的主奇异方向。11B MoE 平均 benchmark 准确率从 40.92 升到 42.76,训练只慢 0.2%。
快速答案
Manifold Power Iteration(MPI)是一种 Mixture-of-Experts 路由器重设计。它把每个 router row 从普通可学习向量,改成会朝对应专家权重矩阵主奇异方向靠拢的专家代理。论文里最直接的数字是:在 11B MoE 实验中,7 个下游任务的平均准确率从 40.92 升到 42.76,GSM8K 从 17.89 升到 27.60。作者报告训练吞吐只慢 0.2%,推理时没有额外开销。
它修的是 router row
稀疏 MoE 层里,路由器决定每个 token 交给哪些专家处理。标准做法通常是一个可学习矩阵:每一行代表一个专家,输入 token 和这些行算分,得分最高的专家被激活。这个接口很简单,也足够通用,但它有一个隐藏问题:router row 被当成专家代理,训练目标却没有明确要求它编码专家本身的权重结构。
MPI 直接修这个点。论文并没有发明新的 dispatch 形式,也没有要求换掉 top-k 路由。它提出的判断更窄:如果 router row 是专家的压缩表示,那它至少应当贴近专家权重矩阵里信息量最大的方向,也就是主奇异方向。
Power-then-Retract 怎么做
每一步训练都给所有专家做完整奇异值分解显然太贵。MPI 用一次 power iteration 替代。对每个 router row,方法取出对应专家的权重,做一次轻量矩阵向量更新,把该行推向主方向;随后执行 retraction,把这一行重新归一到受控尺度。
第二步很关键。没有范数约束时,连续 power iteration 可能让 router row 的范数膨胀或塌缩。在 MoE 路由里,尺度不是中性变量:范数更大的行更容易赢得路由,进而让某个专家过载。论文把这个模式叫作 Power-then-Retract:先朝专家方向移动,再回到稳定的球面约束上。
作者还给了几何推导。MPI 可以被理解为在流形约束下最大化 router row 与专家权重方向投影的最速上升更新。对工程读者来说,这说明它有明确优化目标,不只是随手加的正则项。
关键结果
- 1B 优化器扫描: 在 AdamW、AdamH、Muon、MuonH 四种设置下,MPI 把 25 个 benchmark 平均准确率分别从 42.26 提到 43.56、42.59 提到 43.93、43.01 提到 43.55、42.78 提到 43.98。
- 3B 结果: 经过 midtraining 后,ARC-C、MMLU、TriviaQA、NaturalQs、BBH、GSM8K、MBPP 的平均准确率从 36.37 升到 38.70。
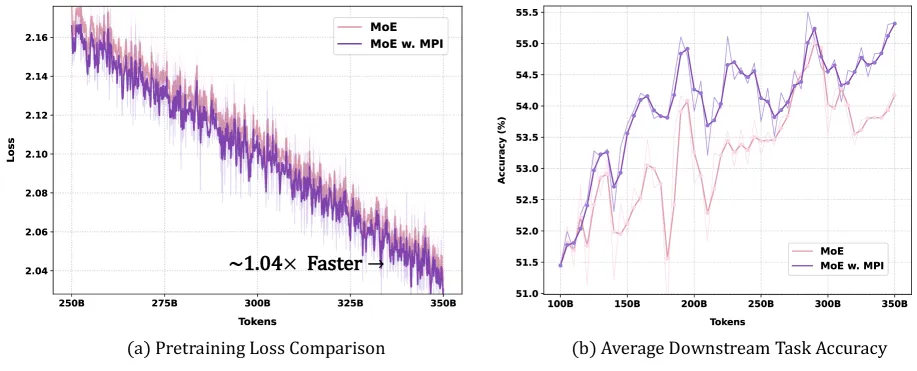
- 11B 结果: 同一组任务平均准确率从 40.92 升到 42.76。其中 GSM8K 提升最大,从 17.89 到 27.60。
- 困惑度: 11B 上 validation bits-per-byte 从 0.728 降到 0.723;Math 集从 1.852 降到 1.581。
- 负载均衡: 3B 模型的 MaxVio Batch 从 1.133 降到 1.024,MaxVio Global 从 0.964 降到 0.711。
- 效率: 11B 实验中 vanilla MoE 吞吐为每天 34.97B tokens,MPI 训练只慢 0.2%。作者称推理零开销,因为可在模型加载时预先计算变换后的 router weights。
最有说服力的是模式一致:1B 在不同优化器上有提升,3B 和 11B 放大后仍有提升。
为什么这篇值得看
MoE 重新成为大模型工程的核心,原因很现实:它能增加参数容量,但不必每个 token 激活全部参数。问题是稀疏模型最终取决于路由质量。路由不好,专家会被浪费,负载会倾斜,token 也可能被送到不合适的专家。
这篇论文有价值,因为它把路由看成表示学习问题,不只盯着负载均衡。很多 MoE 工作会加 auxiliary loss,或调整 top-k 分配。MPI 问的是更底层的问题:router row 本身是不是专家的有效摘要? 这个问题足够干净,也有机会放在其他路由技巧下面使用。
局限与存疑
这些实验是作者自己的预训练实验,还不是开放复现结果。benchmark 覆盖面足以显示信号,但不能证明 MPI 对所有 MoE 架构、所有专家布局和所有训练数据都有效。论文主要拿 vanilla MoE router 做对比,因为作者把 MPI 定义为可与其他路由方法正交叠加。这一定位合理,但也留下了真正工程上最关心的问题:当 MPI 叠加强路由方法和强负载均衡方法后,剩下多少增益?
0.2% 训练开销也需要在真实训练栈里复核。作者的 11B 设置很有参考价值,但不自动覆盖所有分布式实现。推理零开销同样有前提:加载模型时能干净地预计算 router 变换。
常见问题
Manifold Power Iteration 在 MoE 路由里是什么?
Manifold Power Iteration 是一种更新 MoE router row 的方法:让每一行朝对应专家权重矩阵的主奇异方向靠拢,再通过归一化保持路由尺度稳定。
MPI 对 11B MoE 提升有多大?
论文的 11B 实验中,7 个下游任务平均准确率从 40.92 升到 42.76。GSM8K 从 17.89 升到 27.60,validation bits-per-byte 从 0.728 降到 0.723。
MPI 会明显拖慢 MoE 训练吗?
论文报告在 11B 预训练中训练只慢 0.2%。作者还称 MPI 没有推理开销,因为调整后的 router weights 可以在模型加载时预先算好。
MPI 只是一个负载均衡方法吗?
不是。MPI 的主要目标是让 router row 对齐专家权重方向。负载均衡改善更像副作用:在 3B 实验中,MaxVio Global 从 0.964 降到 0.711。
这篇 MPI router 论文最大的局限是什么?
主要局限是对比对象多为 vanilla MoE routing。论文认为 MPI 与其他 router 设计兼容,但它和当前最强路由/负载均衡组合放在一起后能保留多少收益,仍需要更多独立实验。
一句话:MPI 有意思,因为它给 MoE 路由器规定了更明确的任务:代表专家,别只抢一个 top-k 分数。阅读 arXiv 原文。