Gemma Scope:DeepMind 为 Gemma 2 开放的稀疏自编码器套件
DeepMind 开放的 JumpReLU 稀疏自编码器套件,覆盖 Gemma 2 2B 与 9B 每一层,共 400+ 个 SAE、3000 万+ 特征,免费供可解释性研究。
快速答案
Gemma Scope 是一套开放的 JumpReLU 稀疏自编码器(SAE),数量超过 400 个,训练覆盖 Gemma 2 2B 与 9B 的每一层、每一子层,外加 27B 的部分层——共产出 3000 万+ 个学习到的特征、2000+ 份可下载的权重检查点。DeepMind 为此投入了超过 GPT-3 训练算力的 20%,向磁盘写了约 20 PiB 的激活值,然后把这一切免费开源,让可解释性与安全研究不再需要自己从零训练 SAE。
真正的贡献是「免费的 SAE 套件」
这里的研究成果不是新方法,而是拆掉了一道成本墙。稀疏自编码器把模型内部激活分解成一大批稀疏、通常可被人理解的特征,是目前逆向破解大模型「在想什么」的主流路线。难点在于:训练一整套 SAE 极其昂贵——你得在每一层抓取激活、把上 PB 的数据存盘、再为每个位置跑一次大规模训练。这个价签实际上把前沿规模模型上的机制可解释性,锁在了少数几家工业实验室手里。
Gemma Scope 把这笔账一次性付清,再把成果白送出去。任何人现在都能加载 Gemma 2 9B 第 20 层的 SAE 开始检查特征,而无需拥有一座 GPU 集群——这正是它的全部意义。
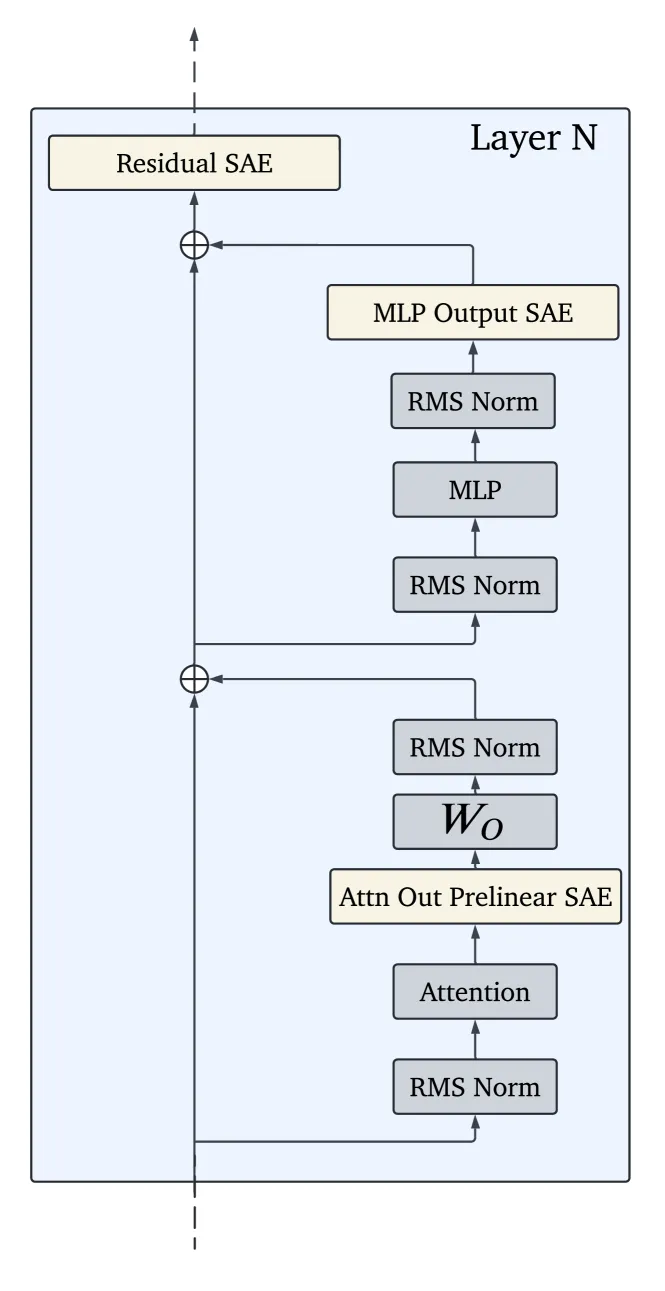
「everywhere all at once」到底覆盖了什么
这套套件在三个维度上的全面性,是此前的开放发布所不具备的。
- 每个位置、每一层。 每个 Transformer block 都在三个位置训练 SAE:注意力头输出(最终投影前)、MLP 输出、MLP 后的残差流。覆盖 2B 全部 26 层与 9B 全部 42 层。
- 多种宽度。 字典规模从 2^14(约 16K)一直到 2^20(约 100 万)个隐变量,你可以按自己的分析需要,在分辨率与算力之间权衡。
- 基座 + 指令微调。 SAE 主要在预训练模型上训练,但 DeepMind 还额外发布了在指令微调版 Gemma 2 9B 上训练的 SAE,供直接对比。
核心数字:400+ 个主 SAE、2000+ 份检查点、3000 万+ 特征,每个 SAE 在 4-16B token 上训练。
为什么选 JumpReLU,而不是 TopK
Gemma Scope 用的是 JumpReLU SAE——每个特征带一个可学习的阈值(平移后的阶跃门控)再叠加 ReLU,只有当预激活越过自己的阈值时该特征才激活。DeepMind 选它有两个务实理由。其一,在「重建质量 vs 稀疏度」的帕累托前沿上,JumpReLU 略优于 Gated 与 TopK SAE。其二,TopK 强行规定每个 token 恰好激活 k 个特征,而 JumpReLU 允许激活特征数随 token 浮动,更贴近信息的真实分布。诚实的脚注是:在人工评分的可解释性上,JumpReLU、TopK、Gated 三者几乎不可区分,所以这个优势体现在保真度指标上,而非可解释性。
关键结果
- 残差流是最难的位置。 Delta loss(把 SAE 接回模型后多出的交叉熵)在残差流 SAE 上始终最高——那里微小的重建误差对下游预测伤害最大。
- 加宽换保真。 把宽度从 2^14 加到 2^19,在固定稀疏度下能稳定降低 delta loss,但收益递减,且无法保证多出的容量真去学了新特征。
- 基座 SAE 能迁移到对话模型。 仅在基座激活上训练的 SAE,重建指令微调版 Gemma 2 9B 激活的效果,几乎与直接在 IT 模型上训练的 SAE 一样好——一个有用且不显然的结论。
- bfloat16 几乎免费。 推理从 float32 切到 bfloat16,对 SAE 保真度影响可忽略。
- 多语言文本上最差。 Delta loss 在数学数据(DeepMind Mathematics)上最低、在多语言数据(Europarl)上最高,反映了以英语为主的预训练配比。
局限与存疑
最大的隐忧在地基而非工程:至今没有公认的指标能判断一个 SAE 到底「好不好」。Delta loss 和未解释方差占比衡量的是重建,不是可解释性,论文也坦承二者可能背离。特征分裂尚无定论——更宽的 SAE 有时学到真正的新特征,有时只是重组旧特征,且没有干净的办法分辨。Transcoder 在 GPT-2 Small 上有效,但在 Gemma 2 上表现不如普通 MLP SAE,先前结论没能迁移过来。而且 SAE 会系统性地漏掉只在更宽字典里才出现的特征,意味着任何单一 SAE 都给不出完整图景。Gemma Scope 是一个供可解释性研究使用的平台,而非对 Gemma 2 的最终解读——那些硬核科学问题,恰恰是它抛给社区去解的。
常见问题
Gemma Scope 是什么?
Gemma Scope 是 DeepMind 开放的一套 400+ 个 JumpReLU 稀疏自编码器,训练于 Gemma 2 2B 与 9B(及 27B 部分层),免费发布,让研究者无需自训 SAE 即可解读 Gemma 2 的内部特征。
Gemma Scope 的训练成本有多高?
DeepMind 投入了超过 GPT-3 训练算力的 20%,向磁盘写了约 20 PiB 激活值,产出数千亿级的 SAE 参数——这道成本墙,如今对其他所有人都被这次发布拆掉了。
什么是 JumpReLU 稀疏自编码器?
JumpReLU SAE 给每个特征加一个可学习阈值(平移阶跃门控)再叠加 ReLU,只有预激活超过自身阈值时该特征才激活。它允许每个 token 的激活特征数浮动,而 TopK SAE 把它固定为 k。
在哪里能下载 Gemma Scope 的 SAE?
权重在 Hugging Face 上,并配有 Neuronpedia 的交互式特征浏览器。你可以加载任意层、任意子层(注意力、MLP 或残差流)的 SAE,宽度从约 16K 到约 100 万特征不等。
Gemma Scope 在指令微调模型上能用吗?
能。在基座 Gemma 2 9B 上训练的 SAE,重建指令微调版 9B 激活几乎与直接在 IT 模型上训练的 SAE 一样保真,因此基座 SAE 可迁移到对话模型。
一句话:DeepMind 一次性付清了 PB 级 SAE 的账单并把成果开源,让前沿模型可解释性变成单个研究者也能做的事。阅读 arXiv 原文。