稀疏自编码器:从大模型激活里找出可解释特征
在大模型激活上训练一个稀疏自编码器,能把『叠加』拆成单一含义的特征,可解释性强过神经元;还能编辑某个概念(比如撇号规则)看模型行为随之改变。
快速答案
大模型里的一个神经元,往往同时为许多互不相关的概念而激活——这就是「叠加」(superposition),它让神经元几乎没法解读。本文在模型内部激活上训练一个稀疏自编码器(SAE),还原出一组规模大得多的特征,其中绝大多数只对单个可以用人话命名的概念激活。在盲测人工评分和自动评分下,SAE 特征都比模型自己的神经元、PCA 方向等基线更单义、更可解释;作者还把间接宾语识别(IOI)行为因果地定位到比以往任何分解都更细的一组特征上。
它针对的「多义性」难题
机械可解释性卡了多年的真实原因是:单个神经元很少只代表一件事。同一个神经元可能既对法语文本、又对 DNA 序列、又对 HTTP 请求亮起——根本找不到一个干净的概念挂上去。主流解释是叠加:一个有 d 个神经元的模型想表达的特征远多于 d,于是把它们塞进彼此重叠、非正交的方向里,容忍一点干扰。如果这是真的,计算的基本单位压根就不是神经元,逐个读神经元本身就走错了路。
本文押的注是:真正的特征是稀疏的——任一 token 只有少数几个被激活——并且它们活在一个比神经元更多方向的「过完备」基里。正是这个重构,让稀疏自编码器成了顺理成章的工具。
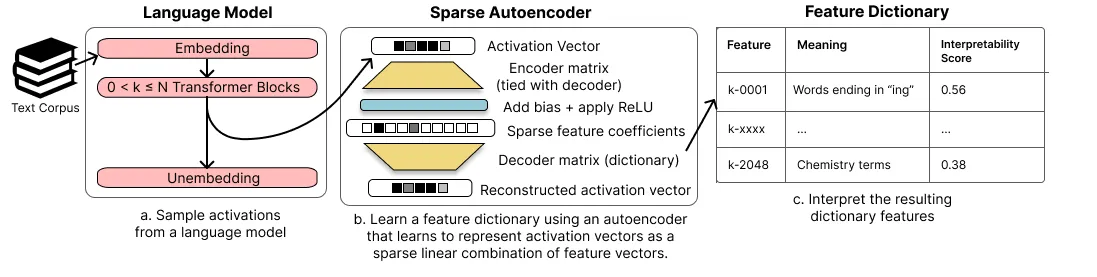
稀疏自编码器怎么工作
这个 SAE 故意做得简单:只有一个隐藏层,宽度大于模型维度,训练目标只有重建激活向量,同时用 L1 惩罚逼隐藏编码稀疏。编码器把一条激活映射成一个高维、绝大部分为零的编码;解码器的列向量就构成了一部学出来的字典,每一列是一个特征方向。因为任意输入下几乎所有项都是零,留下来的每一项被迫携带一个具体、可复用的含义,而不是许多含义糊在一起。
两个设计要点很关键。字典是过完备的——特征数多于神经元——这正是叠加为真时所需要的;而唯一的监督只有「重建 + 稀疏」,没人事先给特征贴标签。可解释的结构是被发现出来的,不是被规定的。这本质上就是经典的字典学习,只是用到了 transformer 激活,而非图像块。
关键结果
- 可解释性胜过基线。 在盲测人工评分和基于 GPT 的自动评分(autointerpretation)下,SAE 特征都比单个神经元、PCA/ICA 成分以及原始残差流基更可解释。
- 是因果,而非相关。 在间接宾语识别任务上,作者精确定位出对反事实行为负因果责任的具体特征——粒度比以往对该回路的分解都更细;编辑这些特征,模型输出会朝预期方向改变。
- 具体的单义特征。 还原出的特征清晰到诸如「撇号语境」特征、「右括号」特征——能用几个字命名的概念,这正是目标所在。
- 一个真实旋钮:稀疏度与保真度的取舍。 稀疏惩罚加大,特征更干净但重建变差;放松,则还原更多激活但特征又糊回去。没有唯一「正确」的字典大小——它是一个调参轴。
为什么现在重要
这是把 SAE 从小众想法变成「打开大模型的默认首选工具」的代表作之一。大约一年内,前沿实验室就把同一套配方扩到了生产级模型——Anthropic 在 Claude 3 Sonnet 上的「Scaling Monosemanticity」、OpenAI 的 SAE 工作,血缘都能追到这里。如果你见过有人放大一个「金门大桥」特征、模型就停不下来地念叨它的演示,背后那个机制就是稀疏自编码器学出来的字典。本文是该方法在真实 LM 上行得通的、紧凑可复现的早期证明。
局限与存疑
结果令人鼓舞,但远未盖棺。可解释性是「测出来」的,不是「保证」的:分数比基线高,但大量特征仍然含糊,而且「比神经元更可解释」本就是个低门槛。稀疏惩罚会留下死特征和重复特征,字典宽度和 L1 权重的选择仍带几分手艺活——后续工作大量精力正是花在这些失效模式上(死隐元、L1 带来的收缩)。重建并不完美,所以 SAE 是看模型的一面有损透镜,而非对模型的忠实重写;它丢掉的东西,在你的分析里就是不可见的。本文实验做在小模型上——它论证的是原理,至于在前沿规模下是不是每一项重要计算都能这么干净地分解,留给了后来的实验室回答。
常见问题
这篇《Sparse Autoencoders Find Highly Interpretable Features》到底主张什么?
主张:训练一个稀疏、过完备的自编码器去重建大模型激活,得到的特征会对单个可命名概念激活;并且这些特征在度量上比模型神经元或 PCA 方向更可解释,还有至少一个回路(IOI)被因果地定位出来。
为什么用稀疏自编码器,而不直接读神经元?
因为神经元是多义的:由于叠加,一个神经元会对许多互不相关的概念激活。SAE 的过完备字典把这些重叠方向拆成彼此分离、大多单义的特征,于是你检视的每个单元只承载一个概念。
什么是神经网络里的「叠加」?
叠加指模型用比神经元更多的方向(彼此重叠、非正交,并容忍小干扰)来表达比神经元数更多的特征。它是单个神经元难以解释的主因,也是「过完备 SAE 是对的工具」这一前提的来源。
它和 Anthropic 的「Scaling Monosemanticity」有何不同?
核心方法相同——用稀疏自编码器从激活里学一部特征字典。这篇 2023 年的论文是更早、更小规模的演示,并给出 IOI 的因果证据;Anthropic 2024 年的工作把完全相同的配方扩到了生产模型(Claude 3 Sonnet),找出了数以百万计的特征。
一句话:在激活上训练一个稀疏自编码器,模型纠缠的神经元就解析成了单义、可编辑的特征。阅读 arXiv 原文。