SCOPE:让大模型在开放任务上自博弈进化
SCOPE 让出题的 Challenger 与检索作答的 Solver 互相进化,靠一份冻结的自评委打分,八个开放基准最高提升 +10.4 分,且不用任何人工标注的提示。
快速答案
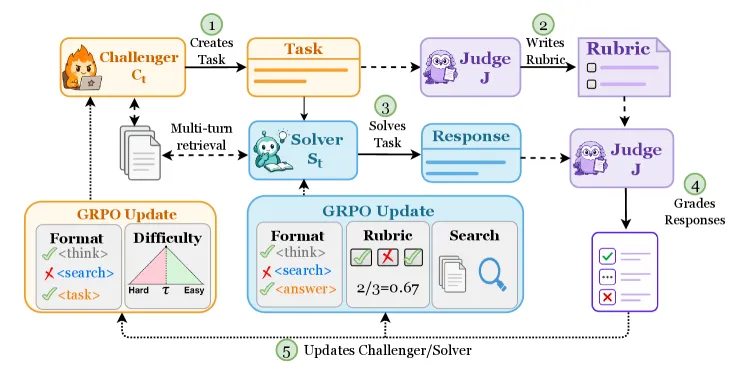
SCOPE 让一个 7-8B 的语言模型在开放式任务上自我提升,全程不需要人工写的提示、标准答案,也不需要更强的外部裁判。它把同一个基座模型拆成三个角色:**Challenger(出题者)**根据文档生成问题,**Solver(作答者)**通过多轮检索来回答,冻结的 Judge(裁判)(也就是训练起点那个模型的快照)从源文档里提炼出一份评分细则(rubric),再据此给答案打分。Challenger 和 Solver 互相对抗、共同训练。
核心结论:在八个开放式基准上,SCOPE 把三个不同的基座模型最高拉高了 +10.4 分(Qwen2.5-7B,三轮迭代后 24.4 → 34.8),并且追平甚至超过了用约 9K 条人工精选提示训练出来的 GRPO_data 基线,而 SCOPE 一条人工提示都没用。
协同进化的循环怎么转
真正巧妙的地方在于它怎么绕开了”裁判难题”。数学、代码上的自博弈之所以成立,是因为答案可以用规则验证:证明能查、单元测试能跑。可开放式任务(深度研究、学术问答、规划、创意写作)没有这种判定器,所以以往的做法只能退回到人工数据集,或者用 GPT-4 这类前沿模型当裁判。SCOPE 把这两根拐杖都扔了。
- Challenger 先抽一篇文档,然后写一道”应当能从这篇文档里答出来”的题。它的奖励是让题目难而可解:不能简单到 Solver 秒答,也不能难到无人能答。
- Solver 在语料库上做检索增强生成,可以分多轮搜索后再作答。
- Judge 是第 0 步冻结的原始模型。关键在于:它能看到 Challenger 用的那篇源文档,据此生成针对该题的评分细则,再拿这份细则去评 Solver 的答案。正是”把细则锚定在真实文档上”这一步,才让一个冻结的、非前沿的模型也能给出可用的奖励信号。
训练交替进行:先调 Challenger,把难度稳定在”有产出”的区间;再调 Solver,让它把题做出来。两者一起往上漂,这就是名字里”协同进化的策略”的含义。
关键结果
- 八个开放式基准(DRB-RACE、ResearchRubrics、ResearchQA、SQA-CS-V2、ResearchPlanGen、HealthBench、WildBench、Arena-Hard-CW)上,对 Qwen2.5-7B、Qwen3-8B、OLMo-3-7B 平均最高提升 +10.4 分。
- Qwen2.5-7B:24.4 → 34.8(+10.4),第三轮迭代;
GRPO_data只到 33.4,SCOPE 在零人工提示下胜出。 - Qwen3-8B:37.7 → 43.1(+5.4);
GRPO_data41.5,SCOPE 领先。 - OLMo-3-7B:30.7 → 38.5(+7.8);
GRPO_data39.0。这里人工数据基线反超了一点点,是 SCOPE 在主指标上唯一没领先的模型。 - 留出的短答问答:在七个问答基准上最高涨 +13.8 分;Qwen3-8B 上 SCOPE 拿到 61.8,
GRPO_data是 60.7。这说明开放式训练能迁移到干净的事实问答上,而不是只会写啰嗦的长答案。
我最看重的是短答问答这块的迁移。用细则打分的强化学习有个常见翻车点:模型学会写更长、更含糊的答案,细则分高了,事实含量却没涨。SCOPE 在短答问答上也提升,说明它学到的是”检索 + 落地”,而不是单纯灌水。
为什么”冻结裁判”是个有意思的赌注
用冻结的初始模型当裁判,是刻意设计,不是将就。如果裁判跟着 Solver 一起进化,就有奖励黑客的风险:Solver 和裁判可能在某个共同的捷径上”合谋”。冻结裁判保证了打分目标是静止的。代价也很直接:你的奖励信号永远不可能比第 0 天的模型更聪明。SCOPE 的赌注是:文档锚定的评分细则能让一个平庸裁判变得”够用”,因为最难的部分(知道正确答案)被甩给了源文档,而不是压在裁判的参数知识上。
这个赌注大体成立,但也给方法封了顶。你没法靠这套把 7B 模型自举到前沿水平;你只能把它自举到”它自己的文档锚定判断”所能认证的天花板。
局限与存疑
- 细则生成是瓶颈,这是作者自己的诊断。整条循环的上限取决于冻结裁判从文档里写出的细则质量,提升细则合成是最明显的抓手。
- OLMo-3-7B 是个警示样本:那里
GRPO_data(39.0)反超了 SCOPE(38.5)。人工提示有时仍会赢,所以”不需要数据”是平均意义上成立,并非绝对。 - 依赖语料库:一切都锚定文档,能学到的能力被检索语料库框死。那些”无法从文档里答出来”的开放创意,在这套框架里没有清晰路径。
- 本文未测规模:结果只到 7-8B。协同进化在 70B+ 上是否还稳定、冻结裁判是否还有用,都是未知。
谁该跳过:如果你的任务本来就有验证器(数学、代码、结构化抽取),直接用那个验证器跑 GRPO 更简单、效果大概也更好。SCOPE 的复杂度只有在”没有验证器、又不愿为前沿裁判付费”时才划算。
常见问题
SCOPE 和 RLAIF 或者用 GPT-4 当裁判有什么区别?
SCOPE 完全不调用外部或更强的模型。它的裁判是被训练基座模型的一个冻结副本,而且打分依据是从源文档提炼出的评分细则,不是裁判自己的主观判断。这让奖励更便宜,也摆脱了对前沿 API 的依赖,代价是奖励上限被你的起始模型框住。
SCOPE 真能打过用人工数据训练的 GRPO 吗?
平均而言能。在 Qwen2.5-7B、Qwen3-8B 以及留出的短答问答上,SCOPE 追平或超过了用约 9K 条人工提示训练的 GRPO_data。例外是 OLMo-3-7B,那里人工基线 39.0 略高于 SCOPE 的 38.5。所以”不需要人工提示”是平均结论,不是绝对结论。
SCOPE 最大的弱点是什么?
作者直接点名:评分细则的生成质量。冻结裁判给出的奖励,可靠程度全看它从每篇文档里抽出的细则,细则差就会卡死整条协同进化循环。它也没在 8B 以上验证过,只适用于”能从检索语料库里答出来”的任务。